by Dong-Ik Ko and Gaurav Agarwal
Texas Instruments
This article was originally published in the December 2011 issue of Embedded Systems Programming.
Gesture recognition is the first step to fully 3D interaction with computing devices. The authors outline the challenges and techniques to overcome them in embedded systems.
As touchscreen technologies become more pervasive, users are becoming more expert at interacting with machines. Gesture recognition takes human interaction with machines even further. It’s long been researched with 2D vision, but the advent of 3D sensor technology means gesture recognition will be used more widely and in more diverse applications. Soon a person sitting on the couch will be able to control the lights and TV with a wave of the hand, and a car will automatically detect if a pedestrian is close by. Development of 3D gesture recognition is not without its difficulties, however.
Limitations of (x,y) coordinate-based 2D vision
Designers of computer vision technology have struggled to give computers a human-like intelligence in understanding scenes. If computers don’t have the ability to interpret the world around them, humans cannot interact with them in a natural way. Key problems in designing computers that can "understand" scenes include segmentation, object representation, machine learning, and recognition.
Because of the intrinsic limitation of 2D representation of scenes, a gesture recognition system has to apply various cues in order to acquire better results containing more useful information. While the possibilities include whole-body tracking, in spite of combining multiple cues it’s difficult to get anything beyond hand-gesture recognition using only 2D representation.
"z"(depth) innovation
The challenge in moving to 3D vision and gesture recognition has been obtaining the third coordinate "z". One of the challenges preventing machines from seeing in 3D has been image analysis technology. Today, there are three popular solutions to the problem of 3D acquisition, each with its own unique abilities and specific uses: stereo vision, structured light pattern, and time of flight (TOF). With the 3D image output from these technologies, gesture recognition technology becomes a reality.
Stereo vision: Probably the best-known 3D acquisition system is a stereo vision system. This system uses two cameras to obtain a left and right stereo image, slightly offset (on the same order as the human eyes are). By comparing the two images, a computer is able to develop a disparity image that relates the displacement of objects in the images. This disparity image, or map, can be either color-coded or gray scale, depending on the needs of the particular system.
Structured light pattern: Structured light patterns can be used for measuring or scanning 3D objects. In this type of system, a structured light pattern is illuminated across an object. This light pattern can be created using a projection of laser light interference or through the use of projected images. Using cameras similar to a stereo vision system allows a structured light pattern system to obtain the 3D coordinates of the object. Single 2D camera systems can also be used to measure the displacement of any single stripe and then the coordinates can be obtained through software analysis. Whichever system is used, these coordinates can then be used to create a digital 3D image of the shape.
Time of flight: Time of flight (TOF) sensors are a relatively new depth information system. TOF systems are a type of light detection and ranging (LIDAR) system and, as such, transmit a light pulse from an emitter to an object. A receiver is able to determine the distance of the measured object by calculating the travel time of the light pulse from the emitter to the object and back to the receiver in a pixel format.
TOF systems are not scanners in that they do not measure point to point. The TOF system takes in the entire scene at once to determine the 3D range image. With the measured coordinates of an object, a 3D image can be created and used in systems such as device control in areas like robotics, manufacturing, medical technologies, and digital photography.
Until recently, the semiconductor devices needed to implement a TOF system were not available. But today’s devices enable the processing power, speed, and bandwidth needed to make TOF systems a reality.
3D vision technologies
No single 3D vision technology is right for every application or market. Table 1 compares the different 3D vision technologies and their relative strengths and weaknesses regarding response time, software complexity, cost, and accuracy.

Stereo vision technology demands considerable software complexity for high-precision 3D depth data that can be processed by digital signal processors (DSPs) or multicore scalar processors. Stereo vision systems can be low cost and fit in a small form factor, making them a good choice for devices like mobile phones and other consumer devices. However, stereo vision systems cannot deliver the accuracy and response time that other technologies can, so they’re not ideal for systems requiring high accuracy such as manufacturing quality-assurance systems.
Structured light technology is a good solution for 3D scanning of objects, including 3D computer aided design (CAD) systems. The software complexity associated with these systems can be addressed by hard-wired logics (such as ASIC or FPGA), which require expensive development and materials costs. The computation complexity also results in a slower response time. Structured light systems are better than other 3D vision technologies at delivering high levels of accuracy at the micro level.
TOF systems deliver a balance of cost and performance that is optimal for device control in areas like manufacturing and consumer electronics devices needing a fast response time. TOF systems typically have low software complexity, but expensive illumination parts (LED, laser diode) and high-speed interface related parts (fast ADC, fast serial/ parallel interface, fast PWM driver) increase materials cost.
z & human/machine interface
With the addition of the "z" coordinate, displays and images become more natural and familiar to humans. What people see with their eyes on the display is similar to what their eyes see around them. Adding this third coordinate changes the types of displays and applications that can be used.
Displays:
Stereoscopic displays typically require the user to wear 3D glasses. The display provides a different image for the left and right eye, tricking the brain into interpreting a 3D image based on the two different images the eyes receive. This type of display is used in many 3D televisions and 3D movie theaters today.
Multiview displays do not require the use of special glasses. These displays project multiple images at the same time, each one slightly offset and angled properly so that a user can experience different projection of images for the same object per each viewpoint angle. These displays allow a hologram effect and will be delivered in new 3D experiences in the near future.
Detection and applications:
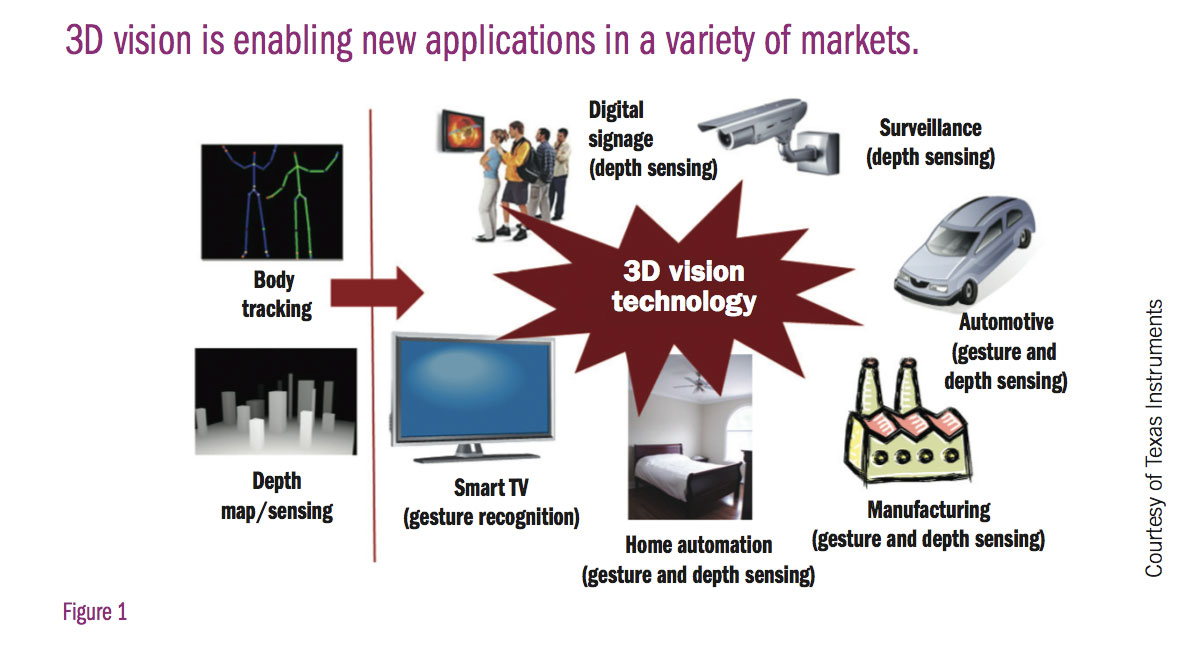
The ability to process and display the "z" coordinate is enabling new applications, including gaming, manufacturing control, security, interactive digital signage, remote medical care, automotive, and robotic vision. Figure 1 depicts some application spaces enabled by the body skeleton and depth map-sensing.
Human gesture recognition (consumer): Human gesture recognition is a new, popular way to give inputs in gaming, consumer, and mobile products. Users are able to interact with the device in a natural and intuitive way, leading to greater acceptance of the products. These human gesture recognition products include various resolutions of 3D data, from 160 x 120 pixels to 640x 480 pixels at 30-60 fps. Software modules such as raw to depth conversion, two-hand tracking, and full body tracking require a digital signal processor (DSP) for efficient and fast processing of the 3D data to deliver real-time gaming and tracking.
Industrial: Most industrial applications for 3D vision, such as industrial and manufacturing sensors, include an imaging system from 1 pixel to several 100K pixels. The 3D images can be manipulated and analyzed using DSP technology to determine manufacturing flaws or to choose the correct parts from a bin.
Interactive digital signage (pinpoint marketing tool): With interactive digital signage, companies will be able to use pinpoint marketing tools to deliver the content that is right for each customer. For example, as someone walks past a digital sign, an extra message may pop up on the sign to acknowledge the customer. If the customer stops to read the message, the sign could interpret that motion as interest in their product and deliver a more targeted message. Microphones would allow the billboard to detect and recognize key phrases to further pinpoint the delivered message.
These interactive digital signage systems will require a 3D sensor for full body tracking, a 2D sensor for facial recognition and microphones for speech recognition. Software for these systems will be run on higher-end DSPs and general-purpose processors (GPPs), delivering applications such as face recognition, full body tracking, and Flash media players as well as functionality like MPEG4 video decoding.
Medical (fault-free virtual/remote care): 3D vision will bring new and unprecedented applications to the medical field. A doctor will no longer be required to be in the same room as the patient. Using a medical robotic vision enabled by high accuracy of 3D sensor, remote and virtual care will ensure the best medical care is available to everyone, no matter where they are located in the world .
Automotive (safety): Recently, automotive technology has come a long way with 2D sensor technology in traffic signal, lane, and obstacle detection. With the advent of 3D sensing technology, "z" data from 3D sensors can significantly improve the reliability of scene analysis. With the inclusion of 3D vision systems, vehicles have new ways of preventing accidents, both day and night. Using a 3D sensor, a vehicle can reliably detect an object and determine if it is a threat to the safety of the vehicle and the passengers inside. These systems will require the hardware and software to support a 3D vision system as well as intensive DSP and GPP processing to interpret the 3D images in a timely manner to prevent accidents.
Video conferencing: Enhanced video conferencing of tomorrow will take advantage of 3D sensors to deliver a more realistic and interactive video conferencing experience. With an integrated 2D sensor as well as a 3D sensor and a microphone array, this enhanced video conferencing system will be able to connect with other enhanced systems to enable high-quality video processing, facial recognition, 3D imaging, noise cancellation and content players (Flash, etc.). With such intensive video and audio processing, DSPs with the right mix of performance and peripherals are needed to deliver the functionality required.
Technology processing steps
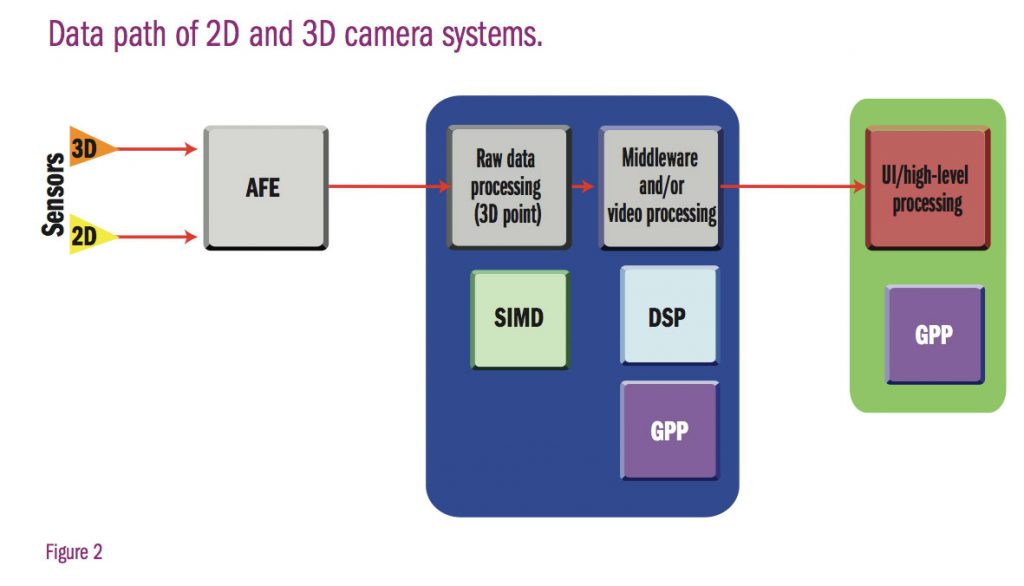
For many applications, both a 2D and 3D camera system will be needed to properly enable the technology. Figure 2 shows the basic data path of these systems. Getting the data from the sensors and into the vision analytics is not as simple as it seems from the data path. Specifically, TOF sensors require up to 16 times the bandwidth of 2D sensors, causing a big input/output (I/O) problem. Another bottleneck occurs in the processing from the raw 3D data to a 3D point cloud. Having the right combination of software and hardware to address these issues is critical for gesture recognition and 3D success. Today, this data path is realized in DSP/GPP combination processors along with discrete analog components and software libraries.
Challenges for 3d-vision embedded systems
Input challenges: As discussed, input bandwidth constraints are a considerable challenge for 3D-vision embedded systems. Additionally, there is no standardization for the input interface. Designers can choose to work with different options, including serial and parallel interfaces for 2D sensor and general purpose external memory interfaces. Until a standard input interface is developed with the best possible bandwidth, designers will have to work with what is available.
Two different processor architectures: The 3D depth map processing of Figure 2 can be divided into two categories: vision specific, data-centric processing and application upper-level processing. Vision specific, data-centric processing requires a processor architecture that can perform single instruction, multiple data (SIMD), fast floating-point multiplication and addition, and fast search algorithms. A DSP is a perfect candidate for quickly and reliably performing this type of processing. For application upper-level-processing, high-level operating systems (OSes) and stacks can provide the necessary feature set that the upper layer of any application needs.
Based on the requirements for both processor architectures, a system-on-chip (SoC) that provides a GPP+ DSP+ SIMD processor with a high data rate I/O is a good fit for 3D vision processing, providing the necessary data and application upper level processing.
Lack of standard middleware: The world of middleware for 3D vision processing is a combination of many different pieces pulled together from multiple sources, including open source (for example, OpenCV) as well as proprietary commercial sources. Commercial libraries are targeted for body tracking applications, which is a specific application of 3D vision. No standardized middleware interface has been developed yet for all the different 3D vision applications.
Anything cool after "z"?
While no one questions the "cool" factor of 3D vision, researchers are already looking into new ways to see beyond, through, and inside people and objects. Using multi-path light analysis, researchers around the world are looking for ways to see around corners or objects. Transparence research will yield systems that are able to see through objects and materials. And with emotion detection systems, applications will be able to see inside the human mind to detect whether the person is lying.
The possibilities are endless when it comes to 3D vision and gesture recognition technologies. But the research will be for nothing if the hardware and middleware needed to support these exciting new technologies are not there. Moving forward, SoCs that provide a GPP+DSP +SIMD architecture will be able to deliver the right mix of processing performance with peripheral support and the necessary bandwidth to enable this exciting technology and its applications.
Dong-Ik Ko is a technical lead in 3D vision business unit at Texas Instruments. He has more than 18 years experience in industry and academy research on embedded system design and optimization methods. He has a master of science in electrical engineering from Korea University and a Ph.D. in computer engineering from University of Maryland College Park.
Gaurav Agarwal a business development manager at Texas Instruments, where he identifies growth areas for the DaVinci digital media processor business. He holds a bachelor of technology in electrical engineering from the Indian Institute of Technology, Kanpur and a master of science in electronic engineering from University of Maryland.