By Brian Dipert
Editor-In-Chief
Embedded Vision Alliance
and Eric Gregori and Shehrzad Qureshi
Senior Engineers
BDTI
This article was originally published at EDN Magazine. It is reprinted here with the permission of EDN. It was adapted from Eric and Shehrzad's technical trends presentation at the March 2012 Embedded Vision Alliance Member Summit.
In Part 1 of this two-part series put together by Embedded Vision Alliance editor-in-chief Brian Dipert and his colleagues Eric Gregori and Shehrzad Qureshi at BDTI, we look at examples of embedded vision and how the technology transition from elementary image capture to more robust image analysis, interpretation and response has led to the need for more capable image sensor subsystems.
In Part 2, "HDR processing for embedded vision," by Michael Tusch of Apical Limited, an EVA member, we discuss the dynamic range potential of image sensors, and the various technologies being employed to extend the raw image capture capability.
Look at the systems you're designing, or more generally at the devices that surround your life, and you're likely to see a camera or few staring back at you. Image sensors and their paired image processors are becoming an increasingly common presence in a diversity of electronic products. It's nearly impossible to purchase a laptop computer without a bezel-mount camera, for example, and an increasing percentage of all-in-one desktop PCs, dedicated computer displays and even televisions are now also including them.
Smartphones and tablets frequently feature image sensors, too, often located on both the front and back panels, and sometimes even arranged in "stereo" configurations for 3-D image capture purposes. And you'll even find cameras embedded in portable multimedia players and mounted in cars, among myriad other examples.
Application abundance
The fundamental justification for including the camera(s) in the design is often for elementary image capture purposes, notably still photography, videography, and videoconferencing. However, given that the imaging building blocks are already in place, trendsetting software and system developers are also leveraging them for more evolved purposes, not only capturing images but also discerning meaning from the content and taking appropriate action in response to the interpreted information.
In the just-mentioned vehicle case study, for example, an advanced analytics system doesn't just "dumbly" display the rear-view camera's captured video feed on a LCD but also warns the driver if an object is detected behind the vehicle, even going so far (in advanced implementations) as to slam on the brakes to preclude impact.
Additional cameras, mounted both inside the vehicle and in various locations around it, alert the driver to (and, in advanced implementations, take active measures to avoid) unintended lane transitions and collisions with objects ahead, as well as to discern road signs' meanings and consequently warn the driver of excessive speed and potentially dangerous roadway conditions. And they can minimize distraction by enabling gesture-interface control of the radio and other vehicle subsystems, as well as to snap the driver back to full attention if he or she is distracted by a text message or other task that has redirected eyeballs from the road, or has dozed off.
In smartphones, tablets, computers and televisions, front-mounted image sensors are now being employed for diverse purposes. They can advise if you're sitting too close or too far away from a display and if your posture is poor, as well as preventing extinguish of the backlight for as long as they sense you're still sitting in front of them (and conversely auto-powering down the display once you've left). Gesture interfaces play an increasingly important role in these and other consumer electronics applications such as game consoles, supplementing (if not supplanting) traditional button and key presses, trackpad and mouse swipes and clicks, and the like.
A forward-facing camera can monitor your respiration (by measuring the chest rise-and-fall cadence) and heart rate (by detecting the minute cyclical face color variance caused by blood flow), as well as advise if it thinks you've had too much to drink (by monitoring eyeball drift). It can also uniquely identify you, automatically logging you in to a system when you appear in front of it and loading account-specific programs and settings. Meanwhile, a rear-mount camera can employ augmented reality to supplement the conventional view of an object or scene with additional information.
These are all examples of embedded vision, a burgeoning application category that also extends to dedicated-function devices such as surveillance systems of numerous types, and manufacturing line inspection equipment. In some cases, computers running PC operating systems historically handled the vision analytics task; this was a costly, bulky, high power and unreliable approach. In other situations, for any or all of these reasons, it has been inherently impractical to implement vision functionality.
Nowadays, however, the increased performance, decreased cost and reduced power consumption of processors, image sensors, memories and other semiconductor devices has led to embedded vision capabilities being evaluated in a diversity of system form factors and price points. But it's also led to the need for increasingly robust imaging subsystems (see sidebar "Focus: the fourth dimension").
Dynamic range versus resolution
For many years, the consumer digital camera market, whose constituent image sensors (by virtue of their high volumes and consequent low prices) also find homes in many embedded vision systems, was predominantly fueled by a "more megapixels is better" mentality. However, in recent times, the limitations of such a simplistic selection strategy have become progressively more apparent.
For one thing, consumers increasingly realize that unless they're printing wall-sized enlargements or doing tight crops of a source photo, they don't need high-resolution pictures that take up significantly more storage space than their lower-resolution precursors. And for another, the noisy and otherwise artifact-filled images generated by modern cameras reveal the lithography-driven downside of the increasing-resolution trend.
Sensors need to remain small in overall dimensions in order to remain cost-effective, a critical attribute in consumer electronics systems. As manufacturers shoehorn an increasing number of pixels onto them, individual pixel dimensions must therefore predictably shrink. Smaller pixels are capable of collecting fewer photons in a given amount of time, thereby leading to decreased light sensitivity. And this phenomenon not only degrades a camera's low-light performance, it also adversely affects the system's dynamic range, a compromise which can only be partially compensated for by post-processing, and then often only with motion artifacts and other tradeoffs (see Part 2 "HDR processing for embedded vision").
Ironically, embedded vision-focused applications tend to have lower resolution requirements than does general-purpose photography. The infrared and visible light image sensors in the Microsoft Kinect, for example, are VGA (640×480 pixel) resolution models, and the vision peripheral only passes along QVGA (320×240 pixel) depth map images to the connected game console or PC.
Given the plethora of available pixels in modern sensors, some suppliers leverage the surplus to both improve light sensitivity and color accuracy, by migrating beyond the conventional Bayer RGB pattern filter array approach (Figure 1). Additional (and altered) filter colors claim to enhance full-spectrum per-pixel interpolation results, while monochrome (filter-less) pixels let in even more light at the tradeoff of dispensing with color discernment (Reference 1).
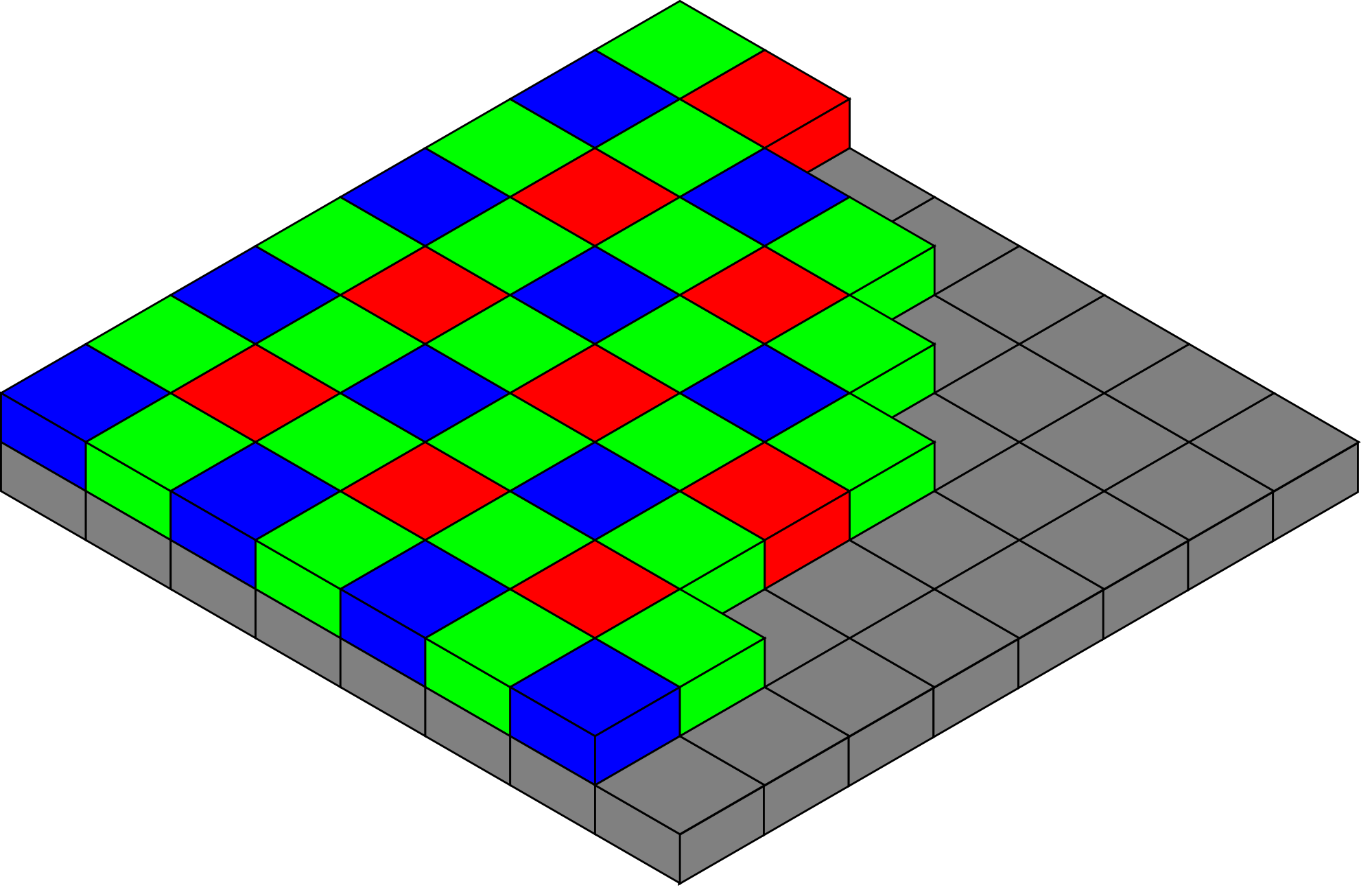



Figure 1: The Bayer sensor pattern, named after a Kodak imaging scientist, remains the predominant filter array scheme used in digital imaging applications (a). More modern approaches increase the number of green-spectrum pixels in a random pattern for enhanced detail in this all-important portion of the visible light spectrum (b), leverage subtractive colors (at the tradeoff of greater required post-processing) in order to improve the filters' light transmission capabilities (c) and even add filter-less monochrome pixels to the mix (d).
Leica's latest digital still camera takes filter alteration to the extreme; this particular model captures only black-and-white images by virtue of its filter-less monochrome image sensor (Figure 2a). Reviewers, however, espouse the sharpness of its photographs even at high ISO settings.
Meanwhile, Nokia's 808 PureView smartphone (Figure 2b) embeds a 41 Mpixel image sensor but by default outputs 8 Mpixel or smaller-resolution images (Reference 2). By combining multiple pixels in variable-sized clusters depending on the digital zoom setting, the 808 PureView dispenses with the need for a complex, costly and bulky optical zoom structure, and it also multiplies the effective per-image-pixel photon collection capability for improved low light performance.
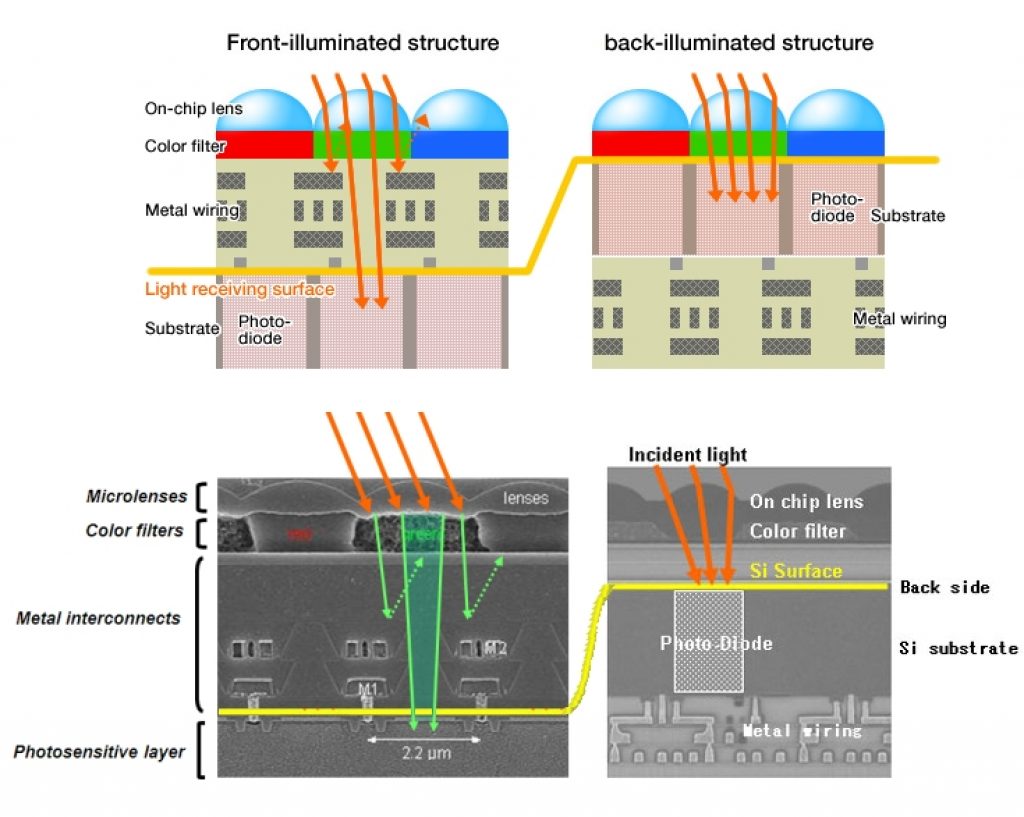
Implementation specifics aside, a new sensor design technique pioneered by Sony called backside illumination (Figure 2c) routes the inter-pixel wiring behind the pixels' photodiodes as a means of improving the sensor's per-pixel fill factor (the percentage of total area devoted to light collection) and therefore its low-light capabilities.


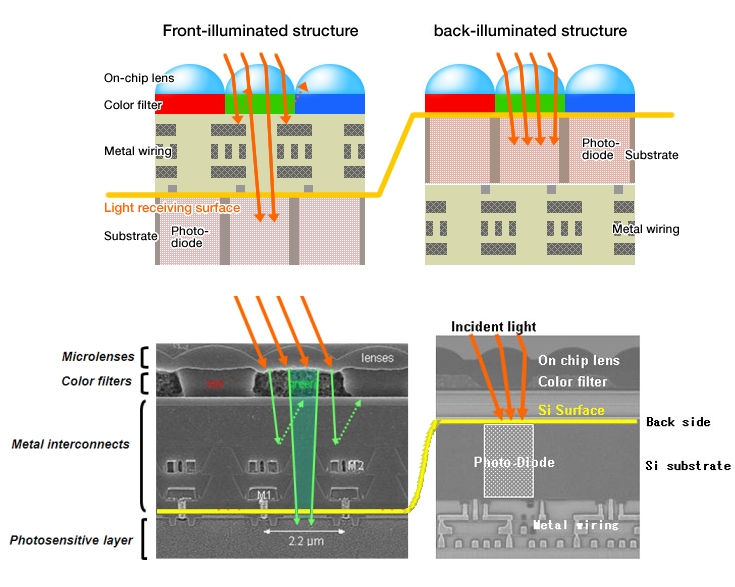
Figure 2: Leica's M Monochrom will set you back $8,000 or so and only captures black-and-white images, but reviewers rave at its sharpness and low-light performance (a). The Nokia 808 PureView Smartphone packs an enormous 41 Mpixel image sensor, which it uses to implement digital zoom and clustered-pixel photon collection capabilities (b). A Sony-pioneered sensor design technique called backside illumination routes the inter-pixel wiring behind the photodiodes, thereby improving the per-pixel fill factor ratio (c).
Depth discernment
A conventional image sensor-based design is capable of supporting many embedded vision implementations. It can, for example, assist in interpreting elementary gestures, as well as tackle rudimentary face detection and recognition tasks, and it's often adequate for optical character recognition functions. However, it may not be able to cleanly detect a more elaborate gesture that incorporates movement to or away from the camera (3-D) versus one that's completely up-and-down and side-to-side (2-D). More generally, it's unable to fully discern the entirety (i.e., the depth) of an object; it can't, for example, easily distinguish between a person's face and a photograph of that same person. For depth-cognizant requirements like these, a 3-D image sensor subsystem is often necessary (Reference 3).
Regardless of the specific 3-D sensor implementation, the common output is the depth map, an image matrix in which each pixel data entry (which is sometimes additionally color-coded for human interpretation purposes) represents the distance between the sensor and a point in front of the sensor (Figure 3). Each depth map frame commonly mates with a corresponding frame captured by a conventional 2-D image sensor, with the two frames parallax-corrected relative to each other, since they source from separate cameras in separate locations.



Figure 3: Regardless of the specific 3-D camera technique employed, they all output a depth map of objects they discern (a). A device such as the HTC EVO 3D smartphone, whose stereo sensor array is primarily intended to capture 3-D still and video images, can also be used for 3-D embedded vision purposes (b). Microsoft's Kinect harnesses the structured light method of discerning depth (c), by projecting a known infrared light pattern in front of it and then analyzing the shape and orientation of the ellipses that it sees (d).
One common method of discerning depth is by means of a stereo sensor array, i.e., a combination of two image sensors that are spaced apart reminiscent of the arrangement of a pair of eyes. As with the eyes and brain, the differing-perspective viewpoints of a common object from both sensors are processed by the imaging SoC in order to assess distance between the object and the sensor array. It's possible to extend the concept beyond two sensors, in multi-view geometry applications. The dual-sensor approach is often the lowest cost, lowest power consumption and smallest form factor candidate. And it's particularly attractive if, as previously mentioned, it's already present in the design for 3-D still image photography and video capture purposes.
One stereo imaging implementation is the discrete "binocular" approach, achieved by "bolting" two cameras together. Although this version of the concept may be the most straightforward from a hardware standpoint, the required software support is more complex. By means of analogy, two motorcycles linked together with a common axle do not make a car! The cameras require calibration for robust image registration, and their frames need to be synchronized if, as is commonly the case, either the camera array or the subject is moving.
Alternatively, it's possible to combine two image sensors in a unified SoC or multi-die package, outputting a combined data stream over a single bus. The advantages of the fully integrated approach include improved control and frame synchronization. The tighter integration leads to improved calibration, which in turn yields better stereo imaging results manifested as increased depth perception and faster image processing.
Projection approaches
Structured light, the second common 3-D sensor scheme, is the technology employed by Microsoft's Kinect. The method projects a predetermined pattern of light onto a scene, for the purpose of analysis. 3-D sensors based on the structured light method use a projector to create the light pattern and a camera to sense the result.
In the case of the Microsoft Kinect, the projector employs infrared light. Kinect uses an astigmatic lens with different focal lengths in the X and Y direction. An infrared laser behind the lens projects an image consisting of a large number of dots that transform into ellipses, whose particular shape and orientation in each case depends on how far the object is from the lens.
Advantages of the structured light approach include its finely detailed resolution and its high accuracy, notably in dimly illuminated environments where visible light spectrum-focused image sensors might struggle to capture adequate images. Structured light software algorithms are also comparatively simple, versus the stereo sensor approach, although the concomitant point cloud processing can be computationally expensive, approaching that of stereo vision.
Conversely, the structured light technique's reliance on infrared light, at least as manifested in Kinect, means that it will have issues operating outdoors, where ambient infrared illumination in sunlight will destructively interfere with the light coming from the projector. The projector is also costly and bulky, consumes a substantial amount of power and generates a large amount of heat; Kinect contains a fan specifically for this reason (Reference 4). And further adding to the total bill of materials cost is the necessary custom projector lens.
Time-of-flight is the third common method of implementing a 3-D sensor. As with structured light, a time-of-flight camera contains an image sensor, a lens and an active illumination source. However, in this case, the camera derives range (i.e., distance) from the time it takes for projected light to travel from the transmission source to the object and back to the image sensor (Reference 5). The illumination source is typically either a pulsed laser or a modulated beam, depending on the image sensor type employed in the design.
Image sensors that integrate digital time counters typically combine with pulsed laser beams, as do shutter-inclusive range-gated sensors. In the latter case, the shutter opens and closes at the same rate with which the projector emits the pulsed beam. The amount of light each image sensor pixel "sees" is therefore related to the distance the pulse travelled, hence the distance from the sensor to the object. Time-of-flight designs that include image sensors with phase detectors conversely use modulated beam sources. Since the strength of the beam varies over time, measuring the incoming light's phase indirectly derives the time-of-flight distance.
Time-of-flight cameras are common in automotive applications such as pedestrian detection and driver assistance, and are equally prevalent in robotics products. They also have a long and storied history in military, defense, and aerospace implementations. The required image processing software tends to be simpler (therefore more real-time amenable) than that needed with stereo camera setups, although the time-of-flight technique's susceptibility to ambient illumination interference and multiple reflections somewhat complicates the algorithms. Frame rates can be quite high, upwards of 60 fps and a speed that's difficult to achieve with stereo imager setups, but the comparative resolution is usually lower. And, as with the structured light technique, the required time-of-flight light projector translates into cost, power consumption (and heat dissipation), size and weight downsides.
Industry alliance can help ensure design success
As previously showcased, embedded vision technology has the potential to enable a wide range of electronic products that are more intelligent and responsive than before, and thus more valuable to users. It can add helpful features to existing products. And it can provide significant new markets for hardware, software, semiconductor and systems manufacturers alike. A worldwide organization of technology developers and providers, the Embedded Vision Alliance (see Sidebar B), was formed beginning last summer to provide engineers with the tools necessary to help speed the transformation of this potential into reality.
References:
- www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/documents/pages/selecting-and-designing-image-sensor-
- www.embedded-vision.com/news/2012/03/05/nokias-808-pureview-technical-article-and-several-videos-you
- www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/videos/pages/march-2012-embedded-vision-alliance-summ
- www.ifixit.com/Teardown/Microsoft-Kinect-Teardown/4066/1
- www.embedded-vision.com/news/2012/03/01/time-flight-samsungs-new-rgb-image-sensor-also-has-depth-sight
Sidebar A: Focus: the fourth dimension
Conventional digital cameras, regardless of which 2-D or 3-D image sensor technology they employ, are all hampered by a fundamental tradeoff that has its heritage in "analog" film. The smaller the lens aperture (or said another way, the larger the aperture setting number), the broader the depth of field over which objects will be in focus. But with a smaller aperture, the lens passes a smaller amount of light in a given amount of time, translating into poor low-light performance for the camera.
Conversely, the wider the aperture (i.e., the smaller the aperture setting number), the better the low-light performance, but the smaller the percentage of the overall image which will be in focus. This balancing act between depth of focus and exposure has obvious relevance to embedded vision applications, which strive to accurately discern the identities, locations and movements of various objects and therefore need sharp source images.
Plenoptic imaging systems, also known as "light field" or "integral" imagers (with the Lytro Light Field camera the most well known consumer-tailored example) address the depth of field-versus-exposure tradeoff by enabling post-capture selective focus on any region within the depth plane of an image (Figure A). The approach employs an array of microlenses in-between the main camera lens and the image sensor, which re-image portions of the image plane. These microlenses sample subsets of the light rays, focusing them to multiple sets of points known as microimages.
Subsequent image reconstruction processes the resulting light field (i.e., the suite of microimages) to generate a 2-D in-focus picture. Altering the process parameters allows for interactive re-focusing within a single acquired image, and also engenders highly robust and real-time 3D reconstruction such as that promoted by Raytrix with its light field cameras.


Figure A: Lytro's Light Field camera (a) is the best-known consumer example of the plenoptic image capture technique, which allows for selective re-focus on various portions of the scene post-capture (b).
The technique was first described in the early 1900s, but digital image capture coupled with robust and low-cost processing circuitry has now made it feasible for widespread implementation (Reference A). Potential plenoptic imaging applications include:
- Optical quality inspection
- Security monitoring
- Microscopy
- 3-D input devices, and
- Both consumer and professional photography
The primary tradeoff at the present time versus conventional digital imaging involves resolution: the typical reconstructed plenoptic frame is 1 to 3 Mpixels in size. However, larger sensors and beefier image processors can improve the effective resolution, albeit at cost and other tradeoffs.
And longer term, the same lithography trends that have led to today's mainstream double-digit megapixel conventional cameras will also increase the resolutions of plenoptic variants. Also, sophisticated "super-resolution" interpolation techniques purport to at least partially mitigate low-resolution native image shortcomings.
References:
A. http://en.wikipedia.org/wiki/Light-field_camera
Sidebar B: The Embedded Vision Alliance
The mission of the Embedded Vision Alliance is to provide practical education, information, and insights to help designers incorporate embedded vision capabilities into products. The Alliance's website (www.Embedded-Vision.com) is freely accessible to all and includes articles, videos, a daily news portal, and a discussion forum staffed by a diversity of technology experts.
Registered website users can receive the Embedded Vision Alliance's e-mail newsletter, Embedded Vision Insights, and have access to the Embedded Vision Academy, containing numerous training videos, technical papers, and file downloads, intended to enable those new to the embedded vision application space to rapidly ramp up their expertise (References 6 and 7).
A few examples of the website's content include:
- The BDTI Quick-Start OpenCV Kit, a VMware virtual machine image that includes OpenCV and all required tools pre-installed, configured, and built, thereby making it easy to quickly get started with vision development using the popular OpenCV library (Reference 8).
- The BDTI OpenCV Executable Demo Package, a combination of a descriptive article, tutorial video, and interactive Windows vision software demonstrations (Reference 9).
- And a three-part video interview with Jitendra Malik, Arthur J. Chick Professor of EECS at the University of California at Berkeley and a computer vision pioneer.10
For more information, visit www.Embedded-Vision.com. Contact the Embedded Vision Alliance at [email protected] and +1-510-451-1800.
References:
- www.embeddedvisioninsights.com
- www.embeddedvisionacademy.com
- www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/downloads/pages/OpenCVVMwareImage
- www.embedded-vision.com/platinum-members/bdti/embedded-vision-training/downloads/pages/introduction-computer-vision-using-op
- www.embedded-vision.com/platinum-members/embedded-vision-alliance/embedded-vision-training/videos/pages/malik-uc-interview-1
Part 2 of this article discusses HDR processing for embedded vision.
Brian Dipert is Editor-In-Chief of the Embedded Vision Alliance ([email protected], +1-510-451-1800). He is also a Senior Analyst at BDTI, the industry's most trusted source of analysis, advice, and engineering for embedded processing technology and applications, and Editor-In-Chief of InsideDSP, the company's online newsletter dedicated to digital signal processing technology. Brian has a bachelors degree in Electrical Engineering from Purdue University in West Lafayette, IN. His professional career began at Magnavox Electronics Systems in Fort Wayne, IN; Brian subsequently spent eight years at Intel Corporation in Folsom, CA. He then spent 14 years (and five months) at EDN Magazine.
Eric Gregori is a Senior Software Engineer and Embedded Vision Specialist with BDTI. He is a robot enthusiast with over 17 years of embedded firmware design experience. His specialties are computer vision, artificial intelligence, and programming for Windows Embedded CE, Linux, and Android operating systems. Eric authored the Robot Vision Toolkit and developed the RobotSee Interpreter. He is working towards his Masters in Computer Science and holds 10 patents in industrial automation and control.
Shehrzad Qureshi is a Senior Engineer with BDTI and Principal of Medallion Solutions LLC. He has an M.S. in Computer Engineering from Santa Clara University, and a B.S. in Computer Science from the University of California, Davis. He is an inventor or co-inventor on 8 U.S. issued patents, with many more pending. Earlier in his career, Shehrzad was Director of Software Engineering and Acting Director of IT at Restoration Robotics. Prior to Restoration Robotics, Shehrzad was the Software Manager at biotech startup Labcyte. Shehrzad has held individual contributor positions at Accuray Oncology, where he worked in medical imaging, and Applied Signal Technology, where he worked on classified SIGINT defense programs. He is the author of Embedded Image Processing on the TMS320C6000 DSP (Springer, 2005).