The substantial resources available in modern programmable logic devices, in some cases including embedded processor cores, makes them strong candidates for implementing vision-processing functions. The rapidly maturing OpenCL framework enables the rapid and efficient development of programs that execute across programmable logic fabric and other heterogeneous processing elements within a system.
As mentioned in the initial article in this series, significant portions of many computer vision functions are amenable to being run in parallel. As computer vision—the use of digital processing and intelligent algorithms to interpret meaning from still and video images—finds increasing use in a wide range of applications, exploiting parallel processing has become an important technique for obtaining cost-effective and energy-efficient real-time implementations of vision algorithms. And FPGAs are strong candidates for massively parallel-processing implementations. Recent announcements from programmable logic suppliers such as Altera and Xilinx tout devices containing millions of logic elements, accompanied by abundant on-chip memory and interconnect resources, along with a profusion of high-speed interfaces to maximize data transfer rates between them and other system components.
Note, however, the "significant portions" phrase in the previous paragraph. Even the most parallelizable vision processing algorithms still contain a significant percentage of serial control and other code, for which a programmable logic fabric is an inferior implementation option. Conveniently, however, modern FPGAs often embed "hard" microprocessor cores, tightly integrated with the programmable logic and other on-chip resources, to handle such serial software requirements. They are a more silicon area-, performance- and power-efficient (albeit potentially less implementation-flexible) alternative to the "soft" processor cores, implemented using generic programmable logic resources, which have been offered by FPGA vendors for many years. And alternatively, a CPU or MCU may exist elsewhere in the system, whose communication with the FPGA is accelerated by the earlier-mentioned high-performance interfaces.
How, though, can you straightforwardly evaluate various vision algorithm partitioning scenarios between the FPGA and other processing resources, ultimately selecting and implementing one that's optimal for your design objectives? That's where OpenCL, a standard created and maintained by the Khronos Group industry consortium, comes in. OpenCL is a set of programming languages and APIs for heterogeneous parallel programming that can be used for any application that is parallelizable. Although originally targeted at heterogeneous systems with CPUs and GPUs, OpenCL can also be supported on a variety of other parallel processing architectures, including FPGAs. Some tradeoff between code portability and performance is still inevitable today; creating an optimally efficient OpenCL implementation requires knowledge of specific hardware details (either by yourself or the developers of the OpenCL function libraries that you leverage) and may also require the use of vendor-specific extensions. Both of these topics will be explored in more detail in the remainder of this article. And over time, many of these lingering issues will continue to be addressed; note, for example that C++ programming techniques are available in the latest version of OpenCL.
Middleware IP Unlocks Hardware’s Mysteries
The current OpenCL 2.1 spec has evolved considerably since OpenCL’s inception in 2008, and has become the de facto parallel language for heterogeneous devices and systems. Its promise of delivering portability and performance, however, remains a work in progress, particularly for non-GPU acceleration implementations. As with any new language and standard, the associated tools, IP and other infrastructure elements will continue to mature in the future. OpenCL aspires to raise the design abstraction level so that software developers can efficiently leverage the underlying hardware without the need for significant hardware expertise. Actualizing this aspiration requires significant ongoing advancements in compilers, high-level synthesis tools, and programming environments.
Middleware IP, represented by libraries and APIs, is also a critical factor in achieving this goal. Historically middleware has been a general term for software that ‘glues together’ separate, often complex, and already existing programs. Translating an algorithm or application into an efficient architecture and implementing it in hardware required synthesis tools, a team of RTL developers, and an abundance of time. As hardware designers implemented increasingly complex functions, the consequent need for semiconductor IP along with a robust path to integrating it has created both new companies and new high-level synthesis tools. High-level synthesis has matured as a technology but still requires some hardware expertise to guide the tool; partitioning the algorithm between the processor and hardware accelerators, for example, efficiently moving data, profiling, and other optimizations.
Middleware IP solves the problem of achieving good QOR (quality of results) from OpenCL and high-level synthesis without having to know the minute details of the underlying hardware architecture. If the middleware is programmable through an API, designers can quickly evaluate tradeoffs in area, performance and latency. In the case of FPGAs, which are a "blank sheet of paper," delivering IP, tools and other facilities that enable optimally "filling” them with high level-implemented algorithms has been an ongoing quest for the last quarter-century. The leading programmable logic vendors have made significant strides in these areas, particularly in the last five years, and OpenCL's broad industry support appears to be the "tipping point" for transforming longstanding potential into reality. What is missing until recently is middleware that leverages the FPGA vendors' OpenCL compilers and high-level synthesis and implementation tools.
Past vendor-provided library examples from other silicon technologies include IBM’s Fortran linear algebra library, Intel's IPP (Integrated Performance Primitives) and the OpenCV (open source computer vision) library (the latter initially developed within Intel but subsequently opened for broader industry adoption), Texas Instruments' IMGLIB and VLIB video analytics and vision libraries, and NVIDIA's CUDA development platform. In deep neural network applications, for example, NVIDIA's cuDNN library and API have dramatically accelerated the adoption of machine learning by leveraging the GPU's inherent parallelism and reducing developers' learning cycles. While FPGA suppliers are now delivering OpenCL-based and application-tailored frameworks, their customers also need to invest in the associated libraries and middleware IP that are equally necessary to implement vision algorithms. And while it’s possible to obtain this IP directly from a FPGA supplier, widespread adoption of a new standard such as OpenCL also requires a vibrant vendor-independent middleware IP ecosystem.
Auviz Systems is an example of a company that has invested in developing specialized libraries that target FPGAs. The company's AuvizCV library leverages OpenCL and currently supports more than 45 of the most commonly used OpenCV and OpenVX functions, with more under development (OpenVX is a Khronos Group-managed standard for cross-platform acceleration of computer vision applications). Users can select either area- or performance-optimized versions of each function and can also call multiple functions sequentially, streaming data from one to another in building up the image pipeline while reducing latency by minimizing memory transfers between the FPGA and CPU.
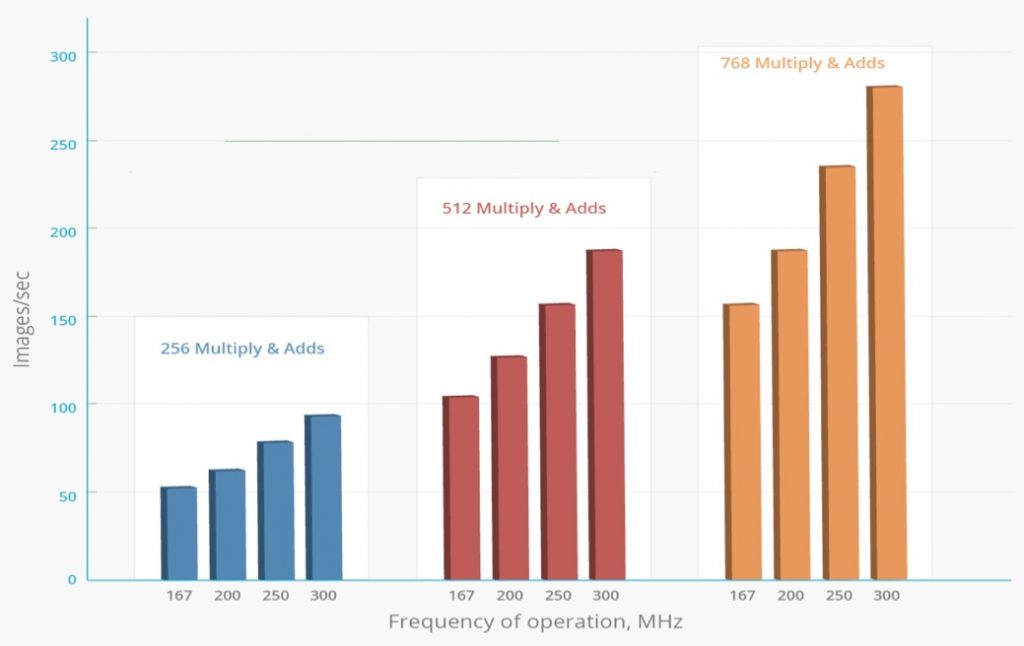
For data center applications, AuvizLA and AuvizDNN provide key algorithms for accelerating the learning and deployment of convolutional neural networks for deep learning through configurable deep neural network functions. In May 2015, at the Embedded Vision Summit, Auviz demonstrated a AlexNet convolutional neural network image classification system built using AuvizDNN functions. Based on this work, Auviz forecasts processing capabilities greater than 14 images/sec/watt on 28 nm FPGA’s. Figure 1 shows how performance scales with clock rate and the number of math (multiply/addition) operators built into the devices. In contrast, per data published in a Microsoft-authored paper (PDF), a high-end GPU can process only 4 images/sec/Watt. In general, FPGAs can deliver 2-10x higher performance/watt depending on the tools, libraries, use of floating-point, half-precision or fixed-point math, and other factors.
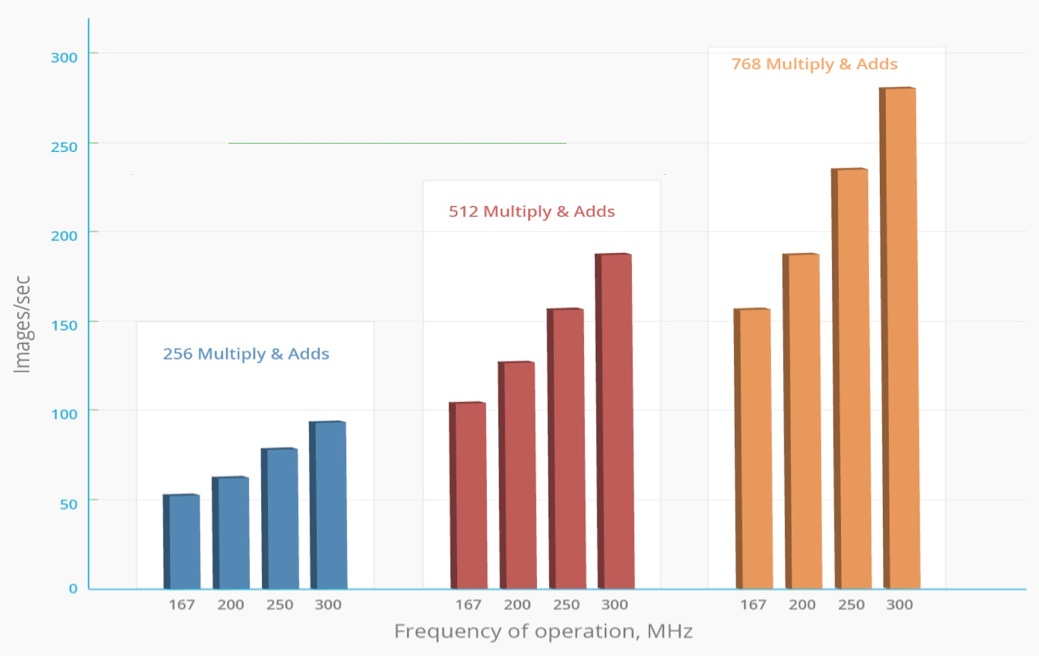
Figure 1. Modern FPGAs, in combination with associated OpenCL APIs, libraries and development toolsets, are capable of delivering very high image processing acceleration rates.
Extensions Build on Industry Standards
While the OpenCL standard enables code portability between various heterogeneous computing architecture alternatives, it also allows designers to optimize their implementations for specific architectures in order to obtain maximum performance. FPGA-based OpenCL acceleration "engines", which involve the creation of custom hardware architectures based on the kernel code of a particular design instead of "pushing" instructions through a fixed architecture, leverage FPGA flexibility to create unique custom platforms using the OpenCL standard in conjunction with vendor-specific extensions. Implementation options include embedding the host into the FPGA, thereby delivering low-latency and cache-coherent memory transaction between the internal host and the programmable acceleration fabric. Because the FPGA is creating the instructions in hardware, the design can be scaled for low- to high-end devices as well as next-generation devices, providing performance benefits without requiring modifications to the original code.
One vendor extension to the OpenCL standard, Channels, even allows data to stream directly into and out of the FPGA (as well as between kernels) without any host interaction. This capability removes the heavy dependency on high-speed caching for real-time data processing by only buffering data on an as-needed basis, either in low-latency customizable memory within the FPGA or external memory directly connected to the FPGA. Pipes, effectively inter-kernel Channels, have recently also been added to the standard and are supported by FPGAs for code portability as a subset of Channels. FPGAs' I/O bus flexibility enables them to connect to a multitude of interface options; they're not restricted to PCI Express, for example.
FPGA-accelerated systems allow designers to choose the level of abstraction for their code, enabling them to trade off development time versus performance. Whether the legacy code is C, C++, OpenCL or lower-level HDL (hardware description language), they can now leverage existing libraries and bring them into the OpenCL development environment. FPGAs also offer other optimization techniques not available in CPUs or GPUs. For example, launching kernels as tasks in the FPGA treats each kernel as a set of sequential instructions. This treatment allows the FPGA to create efficient hardware pipelines, providing explicit optimization insights into performance bottlenecks and ultimately resulting in a latency advantage for the FPGA.
GPUs and CPUs also require complex calculations to ascertain how the NDrange (a one-, two- or three-dimensional array description of the OpenCL work item space) needs to split into work groups in order to satisfy the compute devices' limited local memory and register resources. FPGAs have no practical limitation on either variable; since the large amount of internal memory blocks can be configured to provide "just enough" local memory and registers, the work group is the NDrange. The only exception to this general rule is if the compute units are duplicated, in which case the NDrange needs to divide over the number of available compute units.
Application Examples
Image processing in video analytics systems is one of many emerging opportunities for FPGA usage in conjunction with OpenCL. Today, many vision systems contain multiple interconnected circuit boards, implementing various functions (Figure 2):
- Cameras with one or multiple sensors for image capture
- A communications interface, typically Ethernet
- A frame grabber board to buffer and temporarily store the image
- And a means, typically PCI Express, to communicate the image information to a host PC system (either local or in the "cloud") for processing.
Aside from the sheer number of boards and components required in this legacy approach, other major drawbacks include high cost and power consumption, along with excessive capture-to-processing latency and poor scalability.
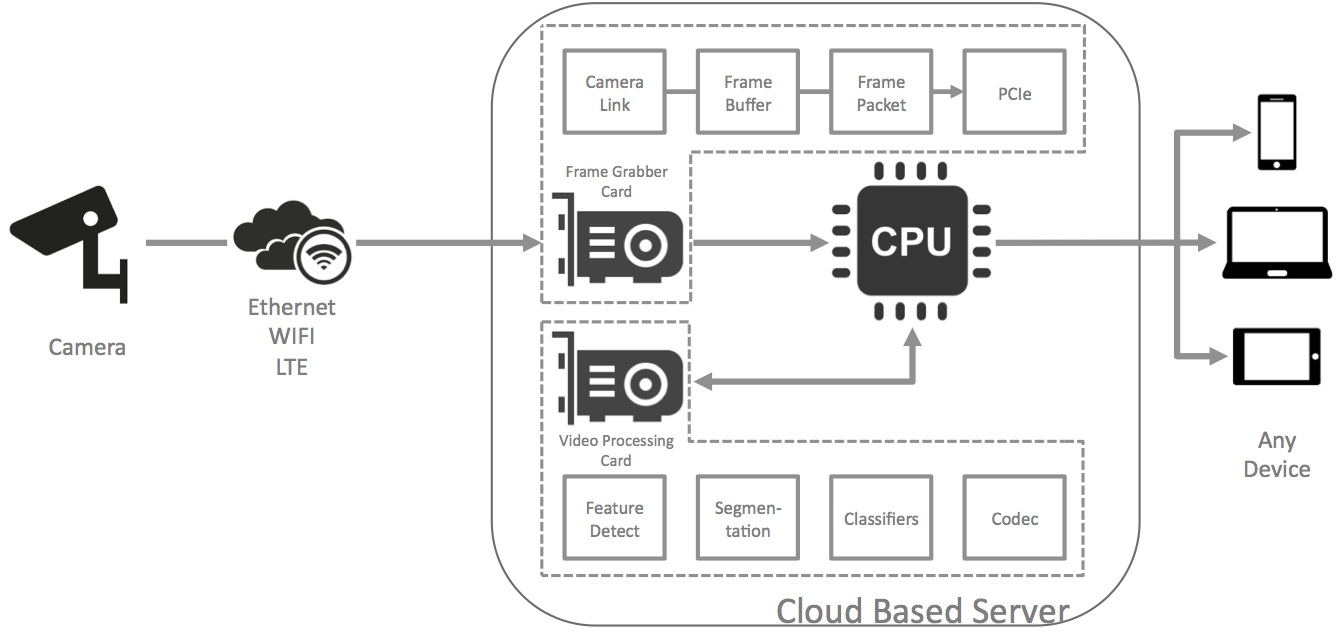
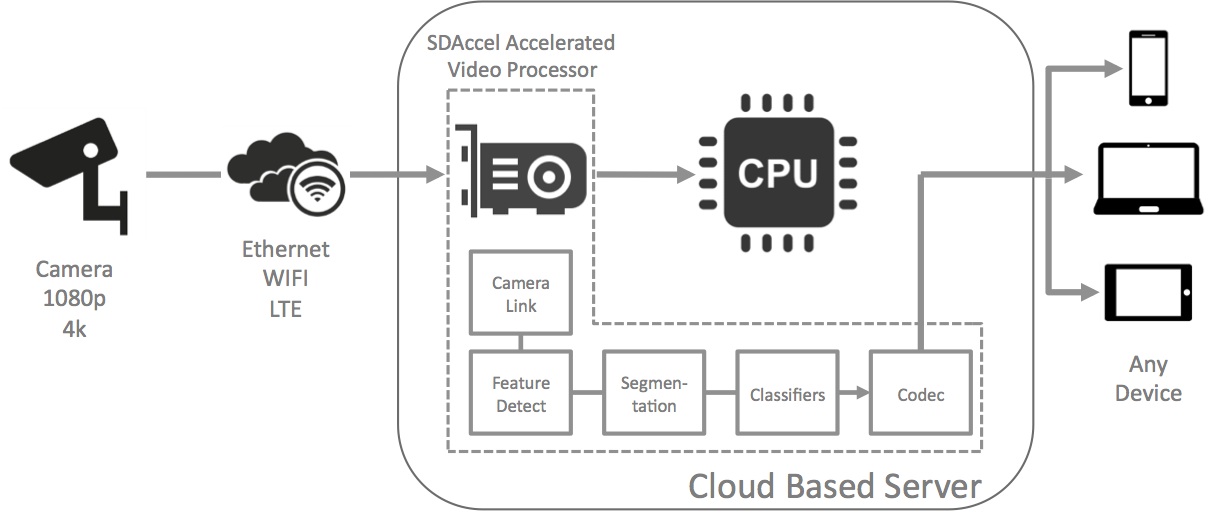
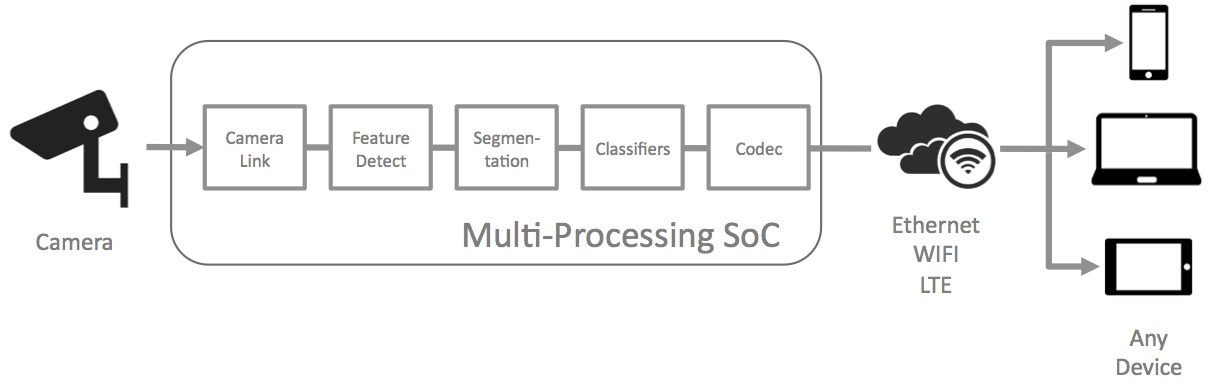
Figure 2. Frame buffers, historically required in video analytics systems (top), can be eliminated in FPGA-accelerated and OpenCL-enabled server configurations (middle). And when considering not only the FPGA's high performance but also its low power consumption and cost-effectiveness, alternative vision processing within the camera itself can reduce the amount of, if not completely eliminate the need for, server-based image analysis (bottom).
Alternatively, by augmenting servers with FPGA-accelerated processing via the combination of OpenCL and an associated toolkit from a programmable logic supplier such as Altera or Xilinx, video analytics can now be performed in a low latency and power efficient manner. OpenCL-based accelerators can directly receive live video feeds, eliminating the need for interim frame grabber cards, and they can accomplish feature detection, segmentation, classification and other vision processing tasks in real time.
In fact, latest-generation FPGAs with integrated processing units are capable of performing significant portions of, if not the entirety of, the necessary vision processing directly within the "edge" camera. In doing so, they reduce (if not eliminate) the need for separate server-based processing. By providing a direct interface from the image sensor(s) to the FPGA, latency is significantly reduced. In-line accelerators allow software developers to rapidly produce and deploy new video processing technologies by using OpenCL’s inherent parallel processing abilities, much faster than with standardized platforms and traditional ASIC "spins". And software development environments provide developers with a path to rapidly implement and evaluate their algorithms in programmable FPGAs.
Additional Developer Assistance
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products. And it can provide significant new markets for hardware, software and semiconductor suppliers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform this potential into reality. Altera, Auviz Systems and Xilinx, the co-authors of this article, are members of the Embedded Vision Alliance.
First and foremost, the Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV. Access is free to all through a simple registration process.
The Alliance also holds Embedded Vision Summit conferences in Silicon Valley. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May 2015, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Alliance website. The next Embedded Vision Summit, along with accompanying half- and full-day workshops, will take place on May 2-4, 2016 in Santa Clara, California. Please reserve a spot on your calendar and plan to attend.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Bill Jenkins
Senior Software Product Marketing Specialist, Altera
Vin Ratford
Co-Founder, Auviz Systems
Dan Isaacs
Director of Connected Systems, Xilinx
Kamran Khan
Senior Product Marketing Engineer, Xilinx