
This article was originally published at Intel's website. It is reprinted here with the permission of Intel.
One day was a summer day like any other summer day. The next, everything had changed. Like swarms, like zombies they came, walking randomly in public places, staring lost into their smart phones, growing increasingly agitated. And then, just as suddenly, they were gone. Pokemon Go had swept across our town, another little dot on its march across the world. In its wake lingered the realization that if one instance had passed, the archetype, augmented reality (AR), was here to stay.
But really, AR has been here for decades. Military systems have used heads-up displays—presenting data on a transparent screen in front of the user—since at least the 1970s. Industrial aids that provide data or prompts—smart glasses—have been in use for several years in specific applications. Consumer experiments such as Google Glass have come and gone. So what is new this time?
Varieties of Augmented Experience
What’s new is that the technology is crossing a threshold, both in users’ experiences and in cost. Let’s look at the experience first. Early heads-up displays were static: the computer-generated information remained at the same location on the display no matter how you moved your head, no matter what was going on in the real world beyond the display. That is fine if the information is about you—your plane’s instrument readings or your heart rate. But it’s not ideal if the information is about an object out there in the world—say a hostile jet fighter or a skidding cement truck.
For information about a particular object, it is better to bind the information to the object, so when the object moves, the information box moves with it (Figure 1). This introduces a new level of complexity for the AR system. It must now find, identify, and track the object. To the heads-up display, add a camera and a vision-processing subsystem.

Figure 1. Floating text boxes only need to stay near their objects
We can add one more layer of complexity. In some situations, just presenting information in a heads-up manner is not enough. Perhaps the information gets lost in the view, or risks obscuring important detail. Is there another aircraft behind that info box? Or perhaps the augmentation needs to be more compelling than just a superimposed, transparent image. Perhaps you want to change the whole appearance of objects or the environment.
Now the user moves from transparent glasses to a virtual-reality headset, looking not through a transparent display but at a near-eye opaque display panel. Everything in the user’s visual field is now rendered—some directly from camera data, some from the graphics subsystem. The world the user sees is a composite of live video and created images.
The Two Latencies
This blended display strategy turns an uncomfortable spotlight on two latencies. One will be familiar to virtual-reality (VR) developers and game enthusiasts. The other is unique to AR.
The familiar latency is the delay between camera input and display output. On a VR headset, for instance, the time it takes a movement of the user’s head to be captured by sensors, processed by the system, and painted onto the display creates this latency. It’s the lag between when you move your head and when the scene moves before your eyes. The maximum imperceptible latency depends on the situation, but in a fast-moving environment it can be under 15 ms. Significantly longer latencies can result in disorientation or illness.
The second latency is specifically an AR issue. If you are blending live video from a head-mounted camera with augmenting graphics, you have to know where the augmented object should be in each video frame. This is a relatively minor issue for images such as text boxes or floating labels. It is probably OK if the label just wanders about near the object. But if you are re-rendering an object—changing its color for emphasis, or turning your dog into a giant chameleon—you need pixel-accurate location in each frame. A chameleon randomly overlapping your dog just doesn’t look right.
The problem is that there is a lot more processing involve in extracting an object from a frame, identifying it, and modifying it than there is in converting camera output video into a new format for a near-eye display. The augmented data may arrive at the display buffer long after the video frame from which it was extracted. If you delay the video to wait for the graphics, you risk exceeding that 15 ms display latency limit and disorienting—or nauseating—your user. If you render the augmenting data in the wrong frame, you risk degrading the image or breaking its connection with reality altogether. What to do?
“This is not a solved problem yet,” warns Holobuilder CEO Mostafa Akbari. But an answer begins with a look at the two parallel processes.
The Two Pipelines
You can visualize the AR system as two pipelines working side by side (Figure 2). One is a video-processing pipe that converts video from a camera—or cameras, for stereo vision—from its native format into the format needed by the display, and puts the data into a display buffer. This process, for Pokemon Go for instance, is more than adequately handled inside a smart phone by a combination of software and the phone’s limited video-acceleration hardware.
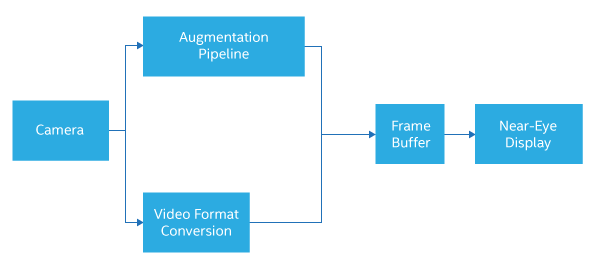
Figure 2. An advanced AR system comprises two pipelines.
The second pipeline is much more application-dependent. At its simplest, all it has to do is figure out where in each video frame to edit in a predetermined image, like a text box. In Pokemon Go’s case, this amounts to keeping Pikachu on the ground. Again, this task is readily handled in a smart phone. But AR can get much more demanding.
Consider a heads-up, near-eye display in a car, providing driver assistance information. You might want to identify all the objects that could intersect the planned path of your car, and highlight them. That would require extracting features from the video frame—and potentially from a fusion of video with other sensor outputs—using the features to locate objects, classifying the objects—by their potential behavior and the desirability of hitting them, for instance—projecting their probable and their physically possible courses, and highlighting the display to draw an appropriate degree of attention to each object. You might do no highlighting for fixed objects not in your path, translucent green for objects that could get in your way but probably won’t, and red for objects that appear determined to hurl themselves beneath your wheels.
This level of processing, within our aforementioned latency constraints, would challenge the most powerful in-car systems today and might better be done in a data center.
We didn’t choose the example at random. The challenges of a fully developed AR system are similar to those of a self-driving car, Akbari observes. You have to convert data from multiple sensors into a three-dimensional model of the real world. Then you have to locate yourself in that space, locate the objects you want to augment, and then render them correctly. In the auto industry, architects are planning to attack this problem with dedicated vision-processing chips, server-class CPUs, compute accelerators, and lots of power. Head-mounted AR goggles won’t have that luxury—just the display technology already taxes the limits of battery capacity and weight. So again: how to manage the latency of the AR pipeline in a wearable system? Answers are emerging stage by pipeline stage.
The Classical Pipeline
The stages in the augmentation pipeline are well defined (Figure 3). You have to fuse data from multiple types of sensors, and then extract distinguishing features—such as vertices, edges, and surfaces—from the sensor data. Then you must combine these feature sets and use them to locate objects in the 3D space. You must classify the objects and determine which ones to augment. Then you must render the augmented images into the display buffer in the correct frame and pixel locations. But the whole pipeline still has to fit within the latency limits. “You have to optimize each stage separately, and then optimize them all together,” Akbari says.

Figure 3. The augmentation pipeline includes a series of challenging tasks.
Today, unfortunately, optimization has to start outside the system—in the environment. “You try to find a room rich in features, with ideal lighting and lots of contrast,” Akbari counsels. This gives simple feature-extraction algorithms a fighting chance.
Inside the system, you make every attempt within your cost and power budget to reduce pipeline stages to hardware, for instance moving some tasks from CPUs to GPUs. “GPUs are good at feature extraction and rendering,” Akbari says. “It would be great if they were good at classification, too.” There are dedicated vision-processing ICs. And, Akbari hints, it would be really nice to have a simultaneous localization and mapping (SLAM) algorithm in hardware. In general, the more tasks you can shift from CPU software to dedicated or configurable hardware, the more you are likely to gain in performance, energy efficiency, and hence system size and weight.
That still leaves a lot of stages uncovered. Sensor fusion is often done with Kalman filters, which require a lot of matrix computations. Object recognition and classification have traditionally been done by rule-based systems implemented in software. But there is much interest now in moving these tasks to deep-learning networks—which are evolving their own dedicated, FPGA-based, or GPU-based hardware accelerators. But Akbari worries that today, the computations necessary for a deep-learning classifier may still be too heavy for wearable systems.
Finally, once you have identified the objects to be augmented, there is the non-trivial problem of finding them in the frame buffer and making the necessary changes. This may present a challenge for deep-learning classifiers, because while deep-learning networks are very good at telling you there is an Irish Red Setter in the scene, they aren’t intended to tell you exactly where it is.
The brute-force approach to bringing this pipeline into latency compliance is to simply find ways to run it faster—bigger CPUs, more cores, more hardware accelerations. But there are other possible strategies. One idea being actively researched for connected, autonomous vehicles is to refer the hard parts—like classification—up to the cloud. But Akbari cautions that the network and cloud computing latencies may be larger and more uncertain than the AR system can tolerate.
Another approach might be to give up on keeping the two pipelines frame-synchronous. Once you have extracted and classified an object, perhaps it is better not to repeat the whole process on the next frame. Instead, track the object from frame to frame, and only repeat the extraction and classification if you lose track of the thing. Such an approach may become necessary as the number of objects you have to follow increases from the one or two in a lab setting to the dozen or more facing an autonomous car or a pedestrian on a city street. And decoupling object classification from the pipeline reopens the possibility of exporting it to the cloud.
Still another idea, related to tracking, is motion prediction. If you can predict the location of an object several frames in advance, you can render the augmented image where you predict the object will be in a later frame, rather than racing to get the rendering put back into the original frame before it is displayed. This would allow the augmentation pipeline to run several frames behind the video pipeline. But there would be visual artifacts when you mispredicted the motion of the objects.
What Lies Ahead
Today, AR is real, but limited, Akbari says. “You can use an AR device in special situations: a constructed setting, perfect lighting, a particular function. We need to be able to take the glasses outdoors, use them in a general environment, and for longer periods of time.”
Akbari doesn’t expect a dramatic breakthrough, but rather years of steady engineering advances. “We will make a lot of progress by using scaling to adapt techniques from self-driving cars, such as more diverse sensors and better sensor fusion. Along the way we will achieve good user experiences in more and more environments, with more kinds of tasks, step by step. We will get longer periods of wear, and outdoor, real-world use. But we are a long way from a user putting on an AR headset in the morning and wearing it all day.” Augment as you will, but that is the reality.
By Ron Wilson
Editor-in-Chief, Intel