This article explains the differences between images intended for human viewing and for computer analysis, and how these differences factor into the hardware and software design of a camera intended for computer vision applications versus traditional still and video image capture. It discusses various methods, both industry standard and proprietary, for assessing and optimizing computer vision-intended image quality with a given camera subsystem design approach. And it introduces an industry alliance available to help product creators incorporate robust image capture and analysis capabilities into their computer vision designs.
The bulk of historical industry attention on still and video image capture and processing has focused on hardware and software techniques that improve images' perceived quality as evaluated by the human visual system (eyes, optic nerves, and brain), thereby also mimicking as closely as possible the human visual system. However, while some of the methods implemented in the conventional image capture-and-processing arena may be equally beneficial for computer vision processing purposes, others may be ineffective, thereby wasting available processing resources, power consumption, etc.
Some conventional enhancement methods may, in fact, be counterproductive for computer vision. Consider, for example, an edge-smoothing or facial blemish-suppressing algorithm: while the human eye might prefer the result, it may hamper the efforts of a vision processor that's searching for objects in a scene or doing various facial analysis tasks. In contrast, various image optimization techniques for computer vision might generate outputs that the human eye and brain would judge as "ugly" but a vision processor would conversely perceive as "improved."
Historically, the computer vision market was niche, thereby forcing product developers to either employ non-optimal hardware and software originally intended for traditional image capture and processing (such as a smartphone camera module, tuned for human perception needs) or to create application-optimized products that by virtue of their low volumes had consequent high costs and prices. Now, however, the high performance, cost effectiveness, low power consumption, and compact form factor of various vision processing technologies are making it possible to incorporate practical computer vision capabilities into a diversity of products that aren't hampered by the shortcomings of historical image capture and processing optimizations.
Detailing the Differences
To paraphrase a well-known proverb, IQ (image quality) is in the eye of the beholder…whether that beholder is a person or a computer vision system. For human perception purposes, the fundamental objective of improving image quality is to process the captured image in such a way that it is most pleasing to the viewer. Sharpness, noise, dynamic range, color accuracy, contrast, distortion, and artifacts are just some of the characteristics that need to blend in a balanced way for an image to be deemed high quality (Figure 1).

Figure 1. Poor color tuning, shown in the ColorChecker chart example on the left, results in halos within colored squares along with color bleeding into black borders (see inset), both artifact types absent from the high-quality tuning example on the right (Courtesy Algolux, ColorChecker provided by Imatest).
Achieving the best possible IQ for human perception requires an optimal lens and sensor, and an ISP (image signal processor) painstakingly tuned by an expert. Complicating the system design are the realities of component cost and quality, image sensor and ISP capabilities, tuning time and effort, and available expertise. There are even regional biases that factor into perceived quality, such as a preference for cooler images versus warmer images between different cultures. Despite these subjective factors, testing and calibration environments, along with specific metrics, still make the human perception tuning process more objective (at least for products targeting a particular region of the world, for example).
For both traditional and neural network-based CV (computer vision) systems, on the other hand, maximizing image quality is primarily about preserving as much data as possible in the source image to maximize the accuracy of downstream processing algorithms. This objective is application-dependent in its details. For example, sharp edges allow the algorithm to achieve better feature extraction for doing segmentation or object detection, but they result in images that look harsh to a human viewer. Color accuracy is also critical in applications such as sign recognition and object classification, but may not be particularly important for face recognition or feature detection functions.
As the industry continues to explore deep learning computer vision approaches and begins to integrate them into shipping products, training these neural network models with ever-larger tagged image and video datasets to improve accuracy becomes increasingly important. Unfortunately, many of these training images, such as the ImageNet dataset for classification, are captured using typical consumer handheld and drone-based cameras, stored in lossy-compressed formats such as JPEG, and tuned for human vision purposes. Their resultant significantly less-than-ideal included information hampers the very accuracy improvements that computer vision algorithm developers are striving for. Significant industry effort is now therefore being applied to computer vision classification, in order to improve accuracy (e.g. the precision and recall) of identifying a scene as well as specific objects within an image.
Application Examples
To further explore the types of images needed for computer vision versus human perception, first look at a "classical" machine vision application that leverages a vision system for quality control purposes, specifically to ensure that a container is within allowable dimensions. Such an application gives absolutely no consideration to images that are "pleasing to the eye." Instead, system components such as lighting, lens, camera and software are selected solely for their ability to maximize defect detections, no matter how unattractive the images they create may look to a human observer.
On the other hand, ADAS (Advanced Driver Assistance Systems) is an example of an application that drives tradeoffs between images generated for processing and for viewing (Figure 2). In some cases, these systems are focused entirely on computer processing, since the autonomous reactions need to occur more rapidly than a human can respond, as with a collision avoidance system. Other ADAS implementations combine human viewing with computer vision, such as found in a back-up assistance system. In this case, the display outputs a reasonably high quality image, typically also including some navigational guidance.


Figure 2. ADAS and some other embedded vision applications may require generating images intended for both human viewing (top) and computer analysis (bottom) purposes; parallel processing paths are one means of accomplishing this objective (courtesy study.marearts.com).
More advanced back-up systems also include passive alerts (or, in some cases, active collision avoidance) for pedestrians or objects behind the vehicle. In this application, the camera-captured images are parallel-processed, with one path going to the in-car display where the image is optimized for driver and passenger viewing. The other processing path involves the collision warning-or-avoidance subsystem, which may analyze a monochrome image enhanced to improve the accuracy of object detection algorithms such as Canny edge and optical flow.
Camera Design Tradeoffs
As background to a discussion of computer vision component selection, consider three types of vision systems: the human visual perception system, mechanical and/or electrical systems designed to mimic human vision, and computer vision systems (Figure 3). Fundamental elements that are common to all three of these systems include:
- Light, i.e. photons
- A lens with a focusing element (the cornea)
- A photoreceptor, i.e. image sensor (the retina)
- A SoC that contains a ISP and application processor (the human brain), and
- interconnects (the nervous system)
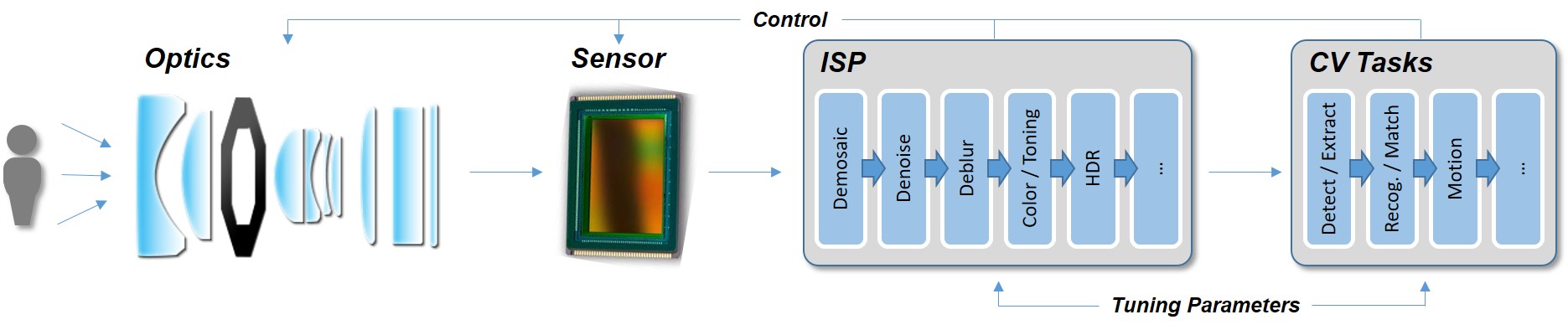
Figure 3. Cameras, whether conventional or computer vision-tailored, contain the same fundamental elements as found in the human visual system (courtesy Algolux).
For human vision, millions of years' worth of evolution has determined the system's current (and presumably optimal) structure, design, and elements. For designers of imaging systems, whether for human perception or computer vision, innovation and evolution have conversely so far produced an overwhelming number of options for each of these system elements. So how does a designer sort through the staggering number of lighting, lens, sensor, and processor alternatives to end up with the optimal system combination? And just as importantly, how does the designer model the system once the constituent elements are chosen, and how is the system characterized?
Another design challenge involves determining how the system's hardware components can impact the software selection, and visa versa. Similarly, how can the upstream system components complement any required downstream image processing? And how can software compensate for less-than-optimal hardware…and is the converse also true?
When selecting vision components, the designer typically begins with a review of the overall system boundary conditions: power consumption, cost, size, weight, performance, and schedule, for example. These big-picture parameters drive the overall design and, therefore, the selection of various components in the design. Traditional machine vision systems have historically been relatively unconcerned about size, weight and power consumption, and even (to a lesser degree) cost. Performance was dictated by available PC-based processors and mature vision libraries, for which many adequate solutions existed. For this reason, many traditional machine vision systems, although performance-optimized, historically utilized standard hardware platforms.
Conversely, the embedded vision designer is typically far more parameter-constrained, and thus is required to more fully optimize the entire system. Every gram, mm, mW, dollar and Gflop can influence the success of the product. Consider, for example, the components that constitute the image acquisition portion of the system design; lighting, the lens, sensor, pixel processor and interconnect. The designer may, for example, consider a low-cost package, such as a smartphone-tailored or other compact camera module (CCM). These modules can deliver remarkable images, at least for human viewing purposes, and are low SWaP (size, weight and power) and cost.
Downsides exist to such a highly integrated approach, however. One is the absence of "lifetime availability": these modules tend to have a lifespan of less than two years. Depending on the application, as previously discussed, the on-board processing may deliver an image suitable for viewing versus for additional vision processing. Also, these modules, along with the necessary support for them, may only be available to very high volume customers.
Component Selection
If the designer decides to choose and combine individual components, rather than using an integrated CCM, several selection factors vie for consideration. The first component to be considered is lighting (i.e. illumination), which is optimized to allow the camera to capture and generate the most favorable image outputs. Many embedded systems rely on ambient light, which can vary from bright sunlight to nearly dark conditions (in ADAS and drone applications, for example). Some scenes will also contain a combination of both bright and dark areas, thereby creating further image-processing challenges. Other applications, such as medical instruments, involve a more constrained-illumination environment and typically also implement specialized lighting to perform analyses.
Illumination options for the designer to consider include source type, geometry, wavelength, and pattern. Light source options include LED, mercury, laser and fluorescent; additional variables include the ability to vary intensity and to "strobe" the illumination pattern. The system can include single or multiple sources to, for example, increase contrast or eliminate shadows. Many applications also use lasers or patterned light to illuminate the target; depth-sensing applications such as laser profiling and structured light are examples. Whether relying on ambient light or creating a controlled illumination environment, designers must also consider the light's wavelength range, since image sensors operate in specific light bands.
Another key element in the vision application is the lens. As with lighting, many options exist, each with cost and performance tradeoffs. Some basic parameters include fixed and auto-focus, zoom range, field of view, depth-of-field and format. The optics industry is marked by continuous innovation; recent breakthroughs such as liquid lenses also bear consideration. The final component in the image capture chain, prior to processing, is the sensor. Many manufacturers, materials, and formats exist in the market. Non-visible light spectrum alternatives, such as UV and infrared, are even available.
The overall trend, at least with mainstream visible-light image sensors, is towards ever-smaller pixels (both to reduce cost at a given pixel count and to expand the cost-effective resolution range) that are compatible with standard CMOS manufacturing processes. The performance of CMOS sensors is approaching that of traditional CCD sensors, and CMOS alternatives also tend to be lower in both cost and power consumption. Many CMOS sensors, especially those designed for consumer applications, also now embed image-processing capabilities such as HDR (high dynamic range) and color conversion. Smaller pixels, however, requires a trade-off between spatial resolution and light sensitivity. Additional considerations include color fidelity and the varying artifacts that can be induced by sensors' global versus rolling shutter modes.
In almost all cases today, the pixel data that comes out of the sensor is processed by an ISP and then compressed. The purpose of the ISP is to deliver the best image quality possible for the application; this objective is accomplished through a pipeline of algorithmic processing stages that typically begins with the de-mosaic (also known as de-Bayer) of the sensor’s raw output to reconstruct a full-color image from the sensor's CFA (color filter array) red, green, and blue pattern. A monochromatic sensor does not need this de-mosaic step, since each pixel is dedicated to capturing light intensity, providing higher native resolution and sensitivity at the expense of loss of color detail.
Other key ISP stages include defective pixel correction, lens-shading correction, color correction, "3A" (auto focus, auto exposure, and auto white balance), HDR, sharpening, and noise reduction. ISPs can optionally be integrated as a core within a SoC, operate as standalone chips, or be implemented as custom hardware on an FPGA. Each ISP provider takes a unique approach to developing the stages' algorithms, as well as their order, along with leveraging hundreds or thousands of tuning parameters with the goal of delivering optimum perceived image quality.
Assessing Component Quality
When selecting vision system components, designers are faced with a staggering number of technical parameters to comprehend, along with the challenge of determining how various components are interdependent and/or complementary. For instance, how does the image sensor resolution affect the choices in optics or lighting? One way that designers can begin to quantify the quality of various components, and the images generated by them, is through available standards. For example, the European Machine Vision Association has developed EMVA1288, a standard now commonly used in the machine vision industry. It defines a consistent measurement methodology to test key performance indicators of machine vision cameras.
Standards such as EMVA1288 assist in making the technical data provided by various camera and sensor vendors comparable. EMVA1288 is reliable in that it documents the measurement procedures as well as the subsequent data determination processes. The specification covers numerous parameters, such as spectral sensitivity, defect pixels, color, and various SNR (signal/noise ratio) specifications, such as maximal SNR, dynamic range, and dark noise.
These parameters are important because they define the system performance baseline. For example, is the color conversion feature integrated in the sensor adequate for the application? If not, it may be better to instead rely on the raw pixel data from the sensor, recreating a custom color reproduction downstream. Another example is defect pixels. Some imaging applications are not concerned about individual (or even small clusters of) pixels that are "outliers", because the information to be extracted from the image is either "global" or pattern-based, in both cases where minor defects are not a concern. In cases like these, then, a lower-cost sensor may be adequate for the application.
Considering Image Quality
Moving beyond the performance of individual system components, the system designer must also consider the quality of the images generated by them, with respect to required processing operations. The definition and evolution of image quality metrics has long been an ongoing area of research and development, and volumes' worth of publications are available on the topic. Simply put, the goal of trying to objectively measure what is essentially a subjective domain arose from the need to assess and benchmark imaging and video systems, in order to streamline evaluation effort and complexity.
The first real metric available to measure image quality was quite subjective in nature. The MOS (mean opinion score) rates peoples' perceptions of a particular image or video sequence across a range from 1 (unacceptable) to 5 (excellent). This approach requires a large-enough population sample size and is expensive, time-consuming, and error-prone. Other more objective metrics exist, such as PSNR (peak signal-to-noise ratio) and MSE (mean squared error), but they have flaws of their own, such as an imperfect ability to model subjective perceptions.
More sophisticated metrics measure parameters such as image sharpness (e.g. MTF, or mean transfer function), acutance, noise, color response, dynamic range, tone, distortion, flare, chromatic aberration, vignetting, sensor non-uniformity, and color moiré. These are the attributes the ISP tries to make as ideal as possible. If it cannot improve the image enough, the system designer might need to select a higher quality lens or sensor. Alternative approaches might be to modify the ISP itself (not possible when it's integrated within a commercial SoC) or do additional post-processing on the application processor.
Several analysis tools and methodologies exist that harness these metrics, both individually and in combination, to evaluate the quality of a camera system's output images against idealized test charts. Specialized test environments with test charts, controlled lighting, and analysis software are required here to effectively evaluate or calibrate a complete camera. DxO, Imatest, Image Engineering, and X-rite are some of the well-known companies that provide these tools, in some cases also offering testing services.
While such metrics can be analyzed, what scores correlate to high-quality image results? Industry standards provide the answer to this question. DxO's DxOMark, for example, is a well-known commercial rating service for camera sensors and lenses, which has been around for a long time and aggregates numerous individual metrics into one summary score. Microsoft has also published image quality guidelines for both its Windows Hello face recognition sign-in feature and for Skype, the latter certifying video calls at both Premium and Standard levels.
The IEEE also supports two image quality standards efforts. The first, now ratified, is IEEE 1858-2016 CPIQ (camera phone image quality), intended to provide objective assessment of the quality of the camera(s) integrated within a smartphone. The second, recently initiated by the organization, is IEEE-P2020, a standard for automotive system image quality. The latter effort is focused not only on image quality for human perception with automobile cameras but also for various computer vision functions. As more camera-based systems are being integrated into cars for increasingly sophisticated ADAS and autonomous driving capabilities, establishing a consistent image quality target that enables the computer vision ecosystem to achieve highest possible accuracy will accelerate the development and deployment of such systems.
Tuning and Optimization
With the incredible advancements in optics, sensors, and processing performance in recent years, one might think an embedded camera would "out of box" deliver amazing images for either human consumption or computer vision purposes. Incredibly complex lens designs exist, for example, for both unique high-end applications and cost- and space-constrained mainstream mobile phones, in both cases paired with state-of-the-art sensors and sophisticated image-processing pipelines. As such, at least in certain conditions, the latest camera phones from Apple, Samsung, and other suppliers are capable of delivering image quality that closely approximates that of premium DSLRs (digital single-lens reflex cameras) and high-end video cameras.
In reality, however, hundreds to thousands of parameters, often preset to default values that don't comprehend specific lens and sensor configurations, guide the image processing done by ISPs. Image quality experts at large companies use analysis tools and environments to evaluate a camera’s ability to reproduce test charts accurately, and then further fine-tune the ISP to deliver optimum image quality. These expert engineering teams at leading core, chip and system providers spend many months iterating different parameter settings, lighting conditions, and test charts to deliver an optimum set of parameters; a massive amount of time and expense! And in some cases, they will invest in the development of internal tools that both supplement industry analysis offerings and that automate testing iterations and/or various data analysis tasks.
In the best-case scenario, the tuning process starts with a software model, typically in C or MATLAB, of the lens, sensor, and ISP. Initial test charts fed through the model produce output images subsequently analyzed by tools such those from Imatest. The development team iteratively sets parameters, sends images through the model, analyzes the results via both automated tools and visual inspection, and repeats this process until an acceptable result is achieved (Figure 4). The team then moves to the prototype stage, incorporating the lens, sensor, ISP (either on a SoC or FPGA), leveraging a test lab with lighting and test chart setups targeted for evaluating real-world image quality.
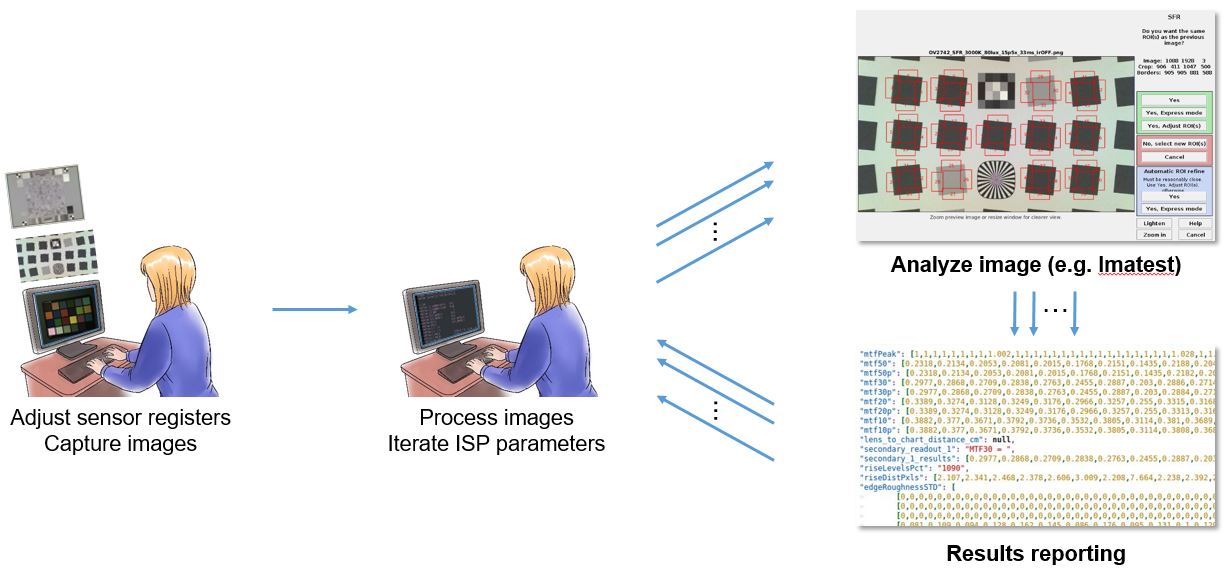
Figure 4. The image tuning process typically begins with iteration using a software model of the lens, sensor and ISP combination (Courtesy Algolux and Imatest).
This stage in the tuning process begins with the initial software model settings as a starting point; image quality experts iterating through additional parameter combinations until they achieve the best-case result. Furthermore, the process must be repeated each time the camera system is cost-optimized or otherwise component-altered (with a less expensive lens or sensor, for example, or an algorithm optimized for lower power consumption), as well as when the product goes through subsequent initial-production and calibration stages.
The performance of the camera is a critical value proposition, which easily rationalizes the investment by larger companies. Internal expertise improves with each product release, incrementally enhancing the team’s tuning efficiency. Teams at smaller companies that don’t have access to internal expertise may instead outsource the task to third-party analysis and optimization service providers; still a very costly and time consuming process. Outsourced services companies that perform tuning build their expertise by tuning a wide variety of camera systems from different clients.
The smallest (but most numerous) companies, which don’t even have the resources to support outsourcing, are often forced to resort to using out-of-box parameter settings. Keep in mind, too, that leading SoC providers provide documentation, tools, and support hand-holding for sensor integration, ISP tuning, etc. only to top customers. Even Raspberry Pi, an open source project, doesn’t provide access to its SoCs' ISP parameter registers for tuning purposes. Scenarios like this represent a significant challenge for any a camera-based system provider. Fortunately, innovative work is now being done to apply machine learning and other advanced techniques in automating IQ tuning for both human perception and computer vision accuracy. These approaches "solve" for the optimum parameter combinations against IQ metric goals, thereby striving to reduce tuning effort and expense for large and small companies alike.
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products, and can provide significant new markets for hardware, software and semiconductor suppliers (see sidebar "Additional Developer Assistance"). Delivering optimum image quality in a product otherwise constrained by boundary conditions such as power consumption, cost, size, weight, performance, and schedule is a critical attribute, regardless of whether the images will subsequently be viewed by humans and/or analyzed by computers. As various methods for assessing and optimizing image quality continue to evolve and mature, they'll bring the "holy grail" of still and video picture perfection ever closer to becoming a reality.
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. Algolux and Allied Vision, the co-authors of this article, are members of the Embedded Vision Alliance. The Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other deep learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, will be held May 1-3, 2017 at the Santa Clara, California Convention Center. Designed for product creators interested in incorporating visual intelligence into electronic systems and software, the Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Summit is intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. Online registration and additional information on the 2017 Embedded Vision Summit are now available.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Dave Tokic
VP Marketing & Strategic Partnerships, Algolux
Michael Melle
Sales Development Manager, Allied Vision