
Although incorporating visual intelligence in your next product is an increasingly beneficial (not to mention practically feasible) decision, how to best implement this intelligence is less obvious. Image processing can optionally take place completely within the edge device, in a network-connected cloud server, or subdivided among these locations. And at the edge, centralized and distributed processing architecture alternatives require additional consideration. This article reviews these different architectural approaches and evaluate their strengths, weaknesses, and requirements. It also introduces an industry alliance available to help product creators optimally implement vision processing in their hardware and software designs.
The overall benefits of incorporating vision processing in products are increasingly understood and adopted by the technology industry, with the plethora of vision-inclusive announcements at this year's Consumer Electronics Show and Embedded Vision Summit only the latest tangible examples of the trend. However, where the vision processing should best take place is less clear-cut. In some cases, for responsiveness or other reasons, it's optimally tackled at the device, a location that's the only available option for a standalone system. In others, where rapidity of results is less important than richness or where device cost minimization is paramount, such processing might best occur at a network-connected server.
In yet other design scenarios, a hybrid scheme, with portions of the overall processing load subdivided between client and cloud (along with, potentially, intermediate locations between these two end points) makes most sense. And in situations where vision processing takes place either in part or in full at the device, additional system architecture analysis is required; should a centralized, unified intelligence "nexus" be the favored approach, or is a distributed multi-node processing method preferable (see sidebar "Centralized vs Distributed Vision Processing")? Fortunately, an industry alliance, offering a variety of technical resources, is available to help product creators optimally implement vision processing in hardware and software designs.
Vision Processing at the Device
Many embedded vision systems find use in applications that require semi- to fully autonomous operation. Such applications demand a real-time, low-latency, always-available decision loop and are therefore unable to rely on cloud connections in order to perform the required processing. Instead, such an embedded vision system must be capable of fully implementing its vision (and broader mission) processing within the device. Such an approach is also often referred to as processing at the edge. Typical applications that require processing at the edge include ADAS (advanced driver assistance systems)-equipped cars and drones, both of which must be capable of navigation and collision avoidance in the process of performing a mission (Figure 1).

Figure 1. Autonomous drones intended for agriculture and other applications are an example of vision processing done completely at the device, i.e. the edge (courtesy Xilinx).
Although vision processing takes place fully at the edge in such applications, this doesn't necessary mean that the device is completely independent from the device. Periodic communication with a server may still occur in order to provide the client with location and mission updates, for instance, or to transfer completed-mission data from the client to the cloud for subsequent analysis, distribution and archive. One example of such a scenario would be with an agricultural drone, which uses hyperspectral imaging to map and classify agricultural land. In this particular application, while the drone can autonomously perform the survey, it will still periodically transmit collected data back to the cloud.
More generally, many of these applications employ algorithms that leverage machine learning and neural networks, which are used to create (i.e., train) the classifiers used by the algorithms. Since real-time generation of these classifiers is not required, and since such training demands significant processing capabilities, it commonly takes place in advance using cloud-based hardware. Subsequent real-time inference, which involves leveraging these previously trained parameters to classify, recognize and process unknown inputs, takes place fully in the client, at the edge.
Processing at the edge requires not only the necessary horsepower to implement the required algorithms but also frequently demands a low power, highly integrated solution such as that provided by a SoC (system on chip). SoC-based solutions may also provide the improved security to protect information both contained within the system and transmitted and received. And the highly integrated nature of processing at the edge often requires that the image processing system be capable of communicating with (and controlling, in some cases) other subsystems. In drones, for example, SWaP (size, weight and power consumption) constraints often result in combining the image processing system with other functions such as motor control in order to create an optimal solution. And going forward, the ever-increasing opportunities for (and deployments of) autonomous products will continue to influence SoC product roadmaps, increasing processing capabilities, expanding integration and reducing power consumption.
Vision Processing in the Cloud
Not all embedded vision applications require the previously discussed real-time processing and decision-making capabilities, however. Other applications involve the implementation of extremely processing-intensive and otherwise complex algorithms, where accuracy is more important than real-time results and where high-bandwidth, reliable network connectivity is a given. Common examples here include medical and scientific imaging; in such cases, vision processing may be optimally implemented on a server, in the cloud (Figure 2). Cloud-based processing is also advantageous in situations where multiple consumers of the analyzed data exist, again such as with medical and scientific imaging.
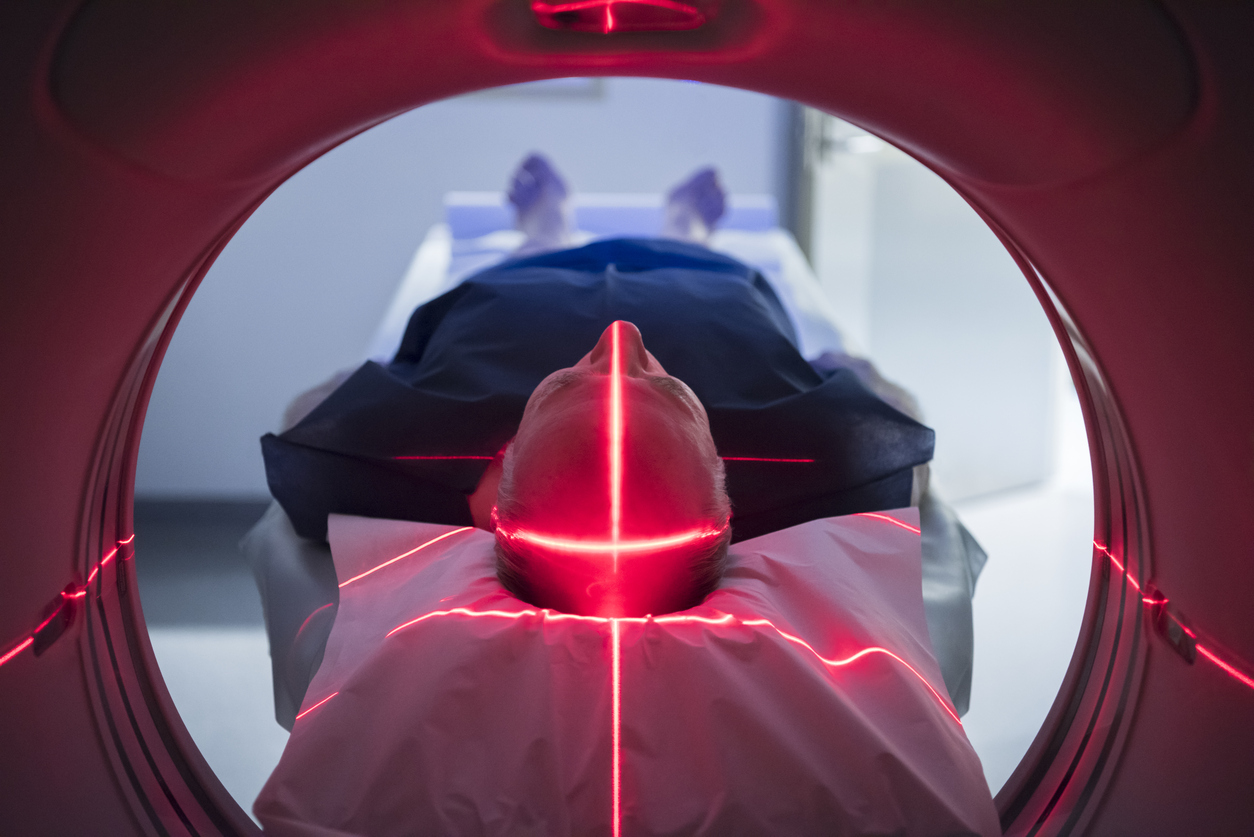
Figure 2. In applications such as medical imaging, responsiveness of image analysis results is less important than accuracy of results, thereby favoring a cloud-based vision processing approach (courtesy Xilinx).
The network-connected client can act either as a producer of vision data to be analyzed at the server, a consumer of the server's analysis results, or (as is frequently the case) both a producer and a consumer. In some applications, basic pre-processing in the client is also desirable prior to passing data on to the server. Examples include client-side metadata tagging in order to ensure traceability, for applications where images need to be catalogued and recalled for later use. Similarly, clients that act as processed data consumers may subsequently perform more complex operations on the information received; doing 3D rendering and rotation in medical imaging applications, for example. In both of these scenarios, care must be taken in the system design to ensure that data does not become stale (i.e. out of date) either in the client or at the cloud.
Connectivity is key to successful cloud based applications; both the cloud and client need to be able to gracefully handle unexpected and unknown-duration network disconnections that leave them unable to communicate with each other, along with reduced-bandwidth time periods. Should such an event occur, clients that act as producers should buffer data in order to seamlessly compensate for short-duration connectivity degradation. Redundant communication links, such as the combination of Wi-Fi, wired Ethernet, 4G/5G cellular data and/or ad hoc networking, can also find use in surmounting disconnections of any of them.
Vision processing within the cloud often leverages deep machine learning or other artificial intelligence techniques to implement the required algorithms. One example might involve facial recognition performed on images uploaded to social media accounts, in order to identify and tag individuals within those images. Such cloud-based processing involves not only the use of deep learning frameworks (such as Caffe and TensorFlow) and APIs and libraries (like OpenCV and OpenVX) but also the ability to process SQL queries and otherwise interact with databases. And server-based processing performance acceleration modules must also support cache coherent interconnect standards such as CCIX.
The processing capability required to implement these and other algorithms defines the performance requirements of the server architecture and infrastructure. Going forward, the cloud will experience ever-increasing demand for acceleration in expanding beyond the historical microprocessor-centric approach. One compelling option for delivering this acceleration involves leveraging the highly parallel processing attributes of FPGAs, along with their dynamic reprogrammability that enables them to singlehandedly handle multiple vision processing algorithms (and steps within each of them). Companion high level synthesis (HLS) development tools support commonly used frameworks and libraries such as those previously mentioned. And FPGAs' performance-per-watt metrics, translated into infrastructure costs, are also attractive in comparison to alternative processing and acceleration approaches.
Hybrid Vision Processing
For some computer vision applications, a hybrid processing topology can be used to maximize the benefits of both cloud and edge alternatives, while minimizing the drawbacks of each. The facial recognition feature found in Tend Insights' new Secure Lynx™ camera provides an example of this approach (Figure 3).

Figure 3. Leading-edge consumer surveillance cameras employ a hybrid vision processing topology, combining initial video analysis at the client and more in-depth follow-on image examination at the server (courtesy Tend Insights).
State-of-the-art face recognition can produce very accurate results, but this accuracy comes at a high price. These algorithms often rely on deep learning for feature extraction, which requires significant processing capacity. For example, the popular OpenFace open source face detection and recognition system takes more than 800ms to recognize a single face when the algorithm is run on a desktop PC running an 8-core 3.7GHz CPU. For a product such as the Tend Secure Lynx camera, adding enough edge-only processing power to achieve a reasonable face recognition frame rate would easily triple the BOM costs, pushing the final purchase price well above the threshold of target market consumers (not to mention also negatively impacting device size, weight, power consumption and other metrics).
A cloud-only processing solution presents even bigger problems. The bandwidth required to upload high-resolution video to the cloud for processing would have a detrimental impact on the consumer’s broadband Internet performance. Processing video in the cloud also creates a long-term ongoing cost for the provider, which must somehow be passed along to the consumer. While a hybrid approach will not work for all vision problems, face detection and recognition is a compelling partitioning candidate. Leveraging a hybrid approach, however, requires segmenting the total vision problem to be solved into multiple phases (Table 1).
|
|
Phase 1 |
Phase 2 |
|
Description |
Motion detection |
Face recognition |
|
Compute requirements |
Low |
High |
|
Filtering ability |
Very high |
Low |
|
Redundancy reduction |
Medium |
None |
|
"Solved" status |
Reasonably solved |
Rapid development |
|
Best location |
Edge |
Cloud |
Table 1. Segmenting the vision processing "problem" using a hybrid approach.
The first phase requires orders of magnitude less processing capacity than the second phase, allowing it to run on a low-power, low-cost edge device. The first phase also acts as a very powerful selective filter, reducing the amount of data that is passed on to the second phase.
With the Tend Secure Lynx camera, for example, the processing requirements for acceptable-quality face detection are much less than those for recognition. Even a low-cost SoC can achieve processing speeds of up to 5 FPS with detection accuracy good enough for a consumer-class monitoring camera. And after the camera detects and tracks a face, it also pushes crops of individual video frames to a more powerful network-connected server for recognition purposes.
By filtering both temporally and spatially in the first phase, the Tend Secure Lynx Indoor camera significantly lowers network usage. The first phase can also reduce data redundancy. Once the Tend Secure Lynx camera detects a face, it then tracks that face across subsequent video frames while using minimal computational power. Presuming that all instances of a spatially tracked face belong to the same person results in a notable reduction in the redundancy of recognition computation.
Delegating face recognition to the cloud also allows for other notable benefits. Although the problem of detecting faces is reasonably solved at the present time (meaning that well-known, low-cost techniques produce sufficiently accurate results), the same cannot be said about face recognition. The recent MegaFace Challenge, for example, exposed the limitations of even the best modern algorithms.
Academics and commercial entities are therefore both continuously working on developing new and improved facial recognition methods in order to improve accuracy. By implementing such rapidly advancing vision approaches in the cloud, the implementer can quickly stay up-to-date with the latest breakthroughs, balancing accuracy and cost. In the cloud, the entire implementation can be replaced seamlessly, including providing the ability to rapidly transition between custom-built implementations and third-party solutions.
However, some cloud drawbacks remain present in a hybrid approach. For example, although ongoing server and bandwidth costs are greatly reduced compared to a cloud-only solution, they remain non-zero and must be factored into the total cost of the product. Also, because the edge device has no ability to process the second phase, any connectivity breakdown means that the problem is only half-solved until the link to the cloud is restored. The camera will simply accumulate face detection data until the network connection is restored, at which time it will once again delegate all recognition tasks to the server.
In the case of the Tend Secure Lynx camera, however, this latter limitation is not a significant drawback in actual practice, because a breakdown in connectivity also prevents the camera from notifying the user as well as preventing the user from viewing live video. As such, even successful recognition would not be useful in the absence of a network connection.
While the hybrid architecture may be the superior approach at the present time, this won't necessarily always be the case. As embedded hardware continues to advance and prices continue to drop in coming years, it is likely that we will shortly begin to see low-cost, low-power SoCs with sufficient compute capacity to singlehandedly run accurate facial recognition algorithms. Around that same time, it is likely that accuracy improvement in new algorithms will begin to plateau, opening the door to move the entire vision problem into a low-cost edge device.
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products, and can provide significant new markets for hardware, software and semiconductor suppliers (see sidebar "Additional Developer Assistance"). Edge, cloud and hybrid vision processing approaches each offer both strengths and shortcomings; evaluating the capabilities of each candidate will enable selection of an optimum approach for any particular design situation. And as both the vision algorithms and the processors that run them continue to evolve, periodic revisits of assumptions will be beneficial in reconsidering alternative approaches in the future.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Nathan Kopp
Principal Architect, Tend Insights
Darnell Moore
Perception and Analytics Lab Manager, Texas Instruments
Mark Jensen
Director of Strategic Marketing for Embedded Vision, Xilinx
Sidebar: Centralized versus Distributed Vision Processing
Even if vision processing operates fully at the device, such as with the semi- and fully autonomous products mentioned earlier, additional processing architecture options and their associated tradeoffs beg for further analysis. Specifically, distributed and centralized processing approaches both offer strengths and shortcomings that require in-depth consideration prior to selection and implementation. Previously, drones were the case study chosen to exemplify various vision processing concepts. Here, another compelling example will be showcased: today's ADAS for semi-autonomous vehicles, rapidly transitioning to the fully autonomous vehicles of the near future.
The quest to eliminate roadway accidents, injuries and deaths, as well as to shuttle the masses with "Jetsonian" convenience, has triggered an avalanche of activity in the embedded vision community around ADAS and vehicle automation. Vehicle manufacturers and researchers are rapidly developing and deploying capabilities that replace driver functions with automated systems in stages (Figure A). Computer vision is the essential enabler for sensing, modeling, and navigating the dynamic world around the vehicle, in order to fulfill the National Highway Traffic Safety Administration’s minimum behavioral competencies for highly automated vehicles (HAVs).
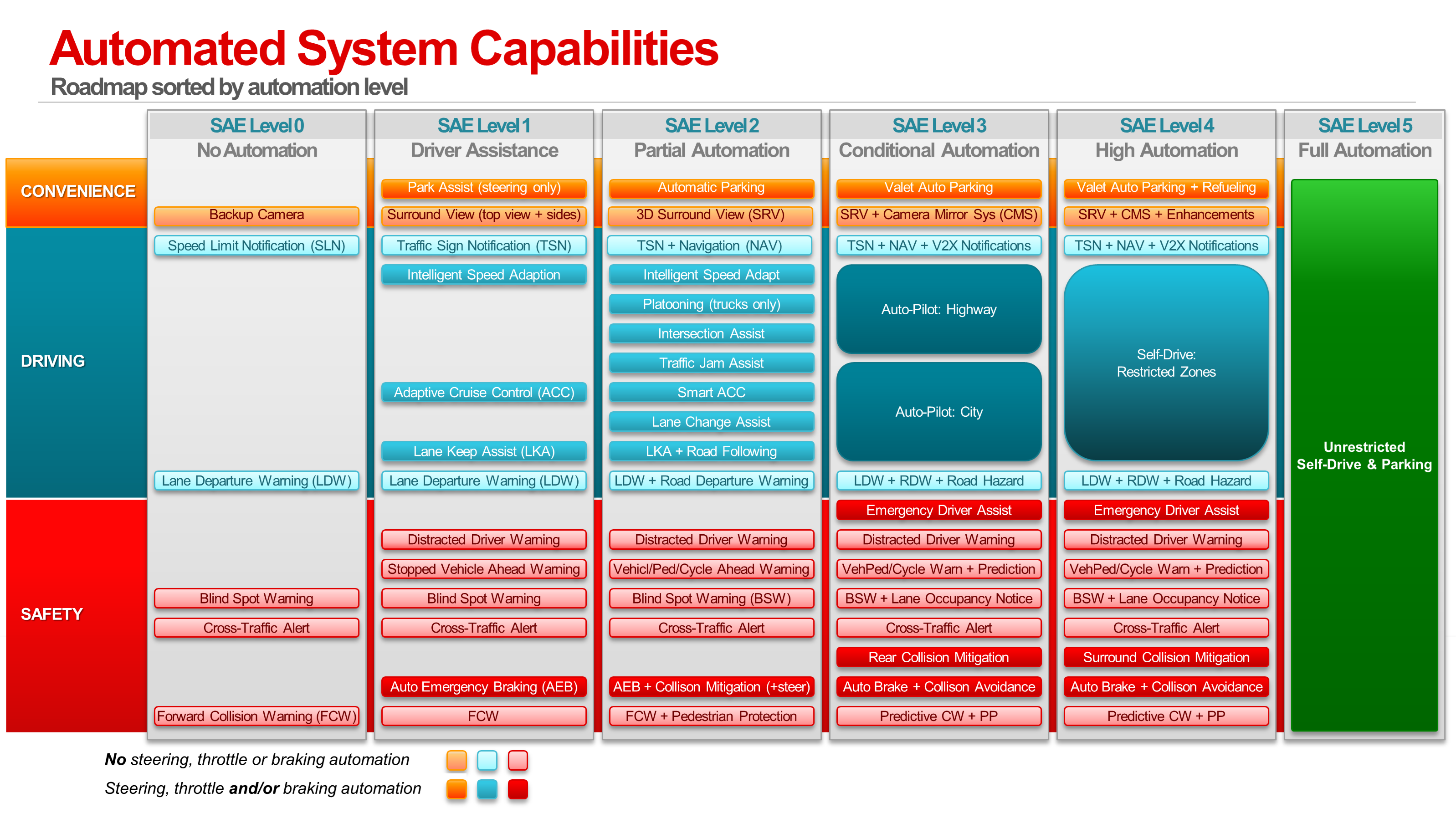
Figure A. The capabilities commonly found on vehicles equipped with ADAS and automated systems span parking, driving, and safety functions (courtesy Texas Instruments).
To faithfully execute driver tasks, highly automated vehicles rely on redundant, complimentary perception systems to measure and model the environment. Emerging vehicles achieving SAE Level 3 and beyond will commonly be equipped with multiple vision cameras as well as RADAR, LIDAR and ultrasonic sensors to support safety, driving, and parking functions. When such multi-modal data is available, sensor fusion processing is employed for redundancy and robustness. Two approaches to sensor fusion generally exist. With object-level sensor fusion, each modality completes signal chain processing to determine an independent result, i.e., the raw input is processed through all algorithm steps, including detection and classification, in order to identify obstacles. The detection likelihoods for each sensing mode are then jointly considered by applying Bayesian voting to determine the final result. An alternative method, using either raw or partially processed results from the signal chain, i.e., feature-level or even raw sensor fusion, can find use for more robust detection.
Most automotive SoCs feature architectures with dedicated hardware acceleration for low- and mid-level image processing, vision, and machine learning functions. A redundant compute domain with the processing capability needed to deploy safe-stop measures is also required to achieve the appropriate safety integrity level for HAVs as recommended by ISO 26262, the governing international standard for functional road safety. While no mandated sensor suite exists, a consensus has formed supporting two predominant vision processing topologies: centralized and distributed.
A centralized compute topology offers several notable inherent advantages, namely access to all the sensor data, which promotes low- latency processing and leads to a straightforward system architecture. Universal sensor access also facilitates flexible fusion options. Automated systems are expected to respond quickly to dynamic, critical scenarios, typically within 100 msec. A low-latency framework that processes all sensor data within 33 msec, i.e., 30 fps, can make three observations within this response window.
To support all Level 3+ applications on a single SoC, however, requires a substantial compute budget along with high bandwidth throughput, both of which generally come with high power consumption and cost liabilities. An example multi-modal sensor configuration will transfer 6.8 Gbps of raw input data to the central ECU (electronic control unit), mandating dense and expensive high-speed memory both at the system level and on-chip (Figure B). Moreover, scalability – especially with cost – can be difficult to achieve. A delicate balance is required with centralized compute arrangements; using two large SoCs, for example, relaxes the software requirements needed for supporting redundancy at the expensive of doubling cost and power, while using a less capable fail-safe ECU may demand a larger software investment.
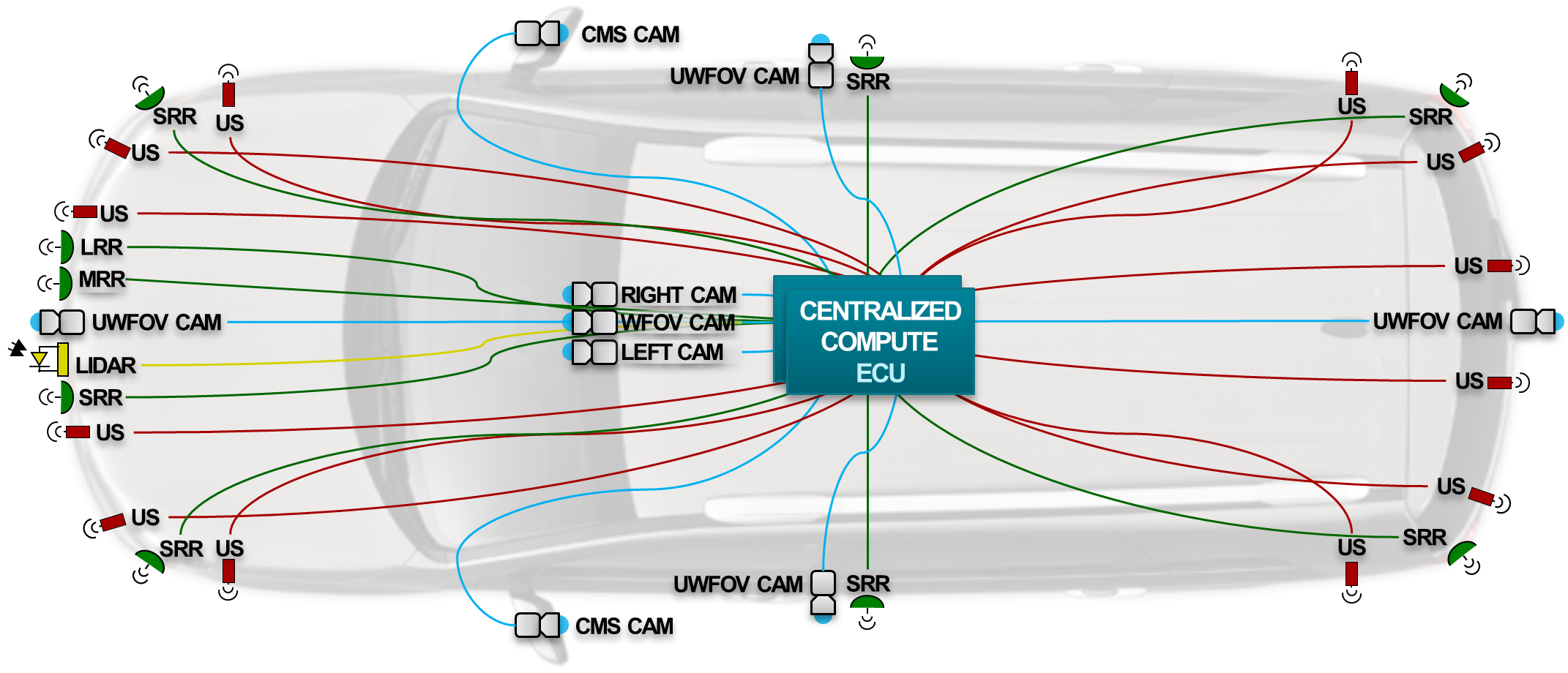
Figure B. An example sensor configuration leverages a centralized compute ECU for a highly automated vehicle. The sensor suite encompasses long-, medium-, and short-range RADAR, ultrasonic sonar, cameras with various optics including ultra-wide field-of-view, and LIDAR (courtesy Texas Instruments).
The alternative distributed compute topology inherits an installed base of driver assistance and vehicle automation applications that have already been cost-optimized, augmenting these systems with functional modules to extend capabilities. This particular framework offers more design, cost, and power scalability than the alternative centralized approach, at the expense of increased system complexity and latency. These challenges can be mitigated to a degree with careful hardware and software architecting. Moreover, at the tradeoff of additional software complexity, a distributed strategy can more robustly negotiate various fail-safe scenarios by leveraging the inherent redundancy of distributed sensing islands.
Example heterogeneous vision SoC families find use in surround view, radar, front camera, and fusion ECUs, with a particular family member chosen depending on the required level of automation and the specific algorithm specifications (Figure C). While dual (for redundancy) SoCs used in alternative centralized processor configurations can approach a cumulative 250 watts of power consumption, thereby requiring exotic cooling options, multiple distributed processors can support similar capabilities at an order of magnitude less power consumption.
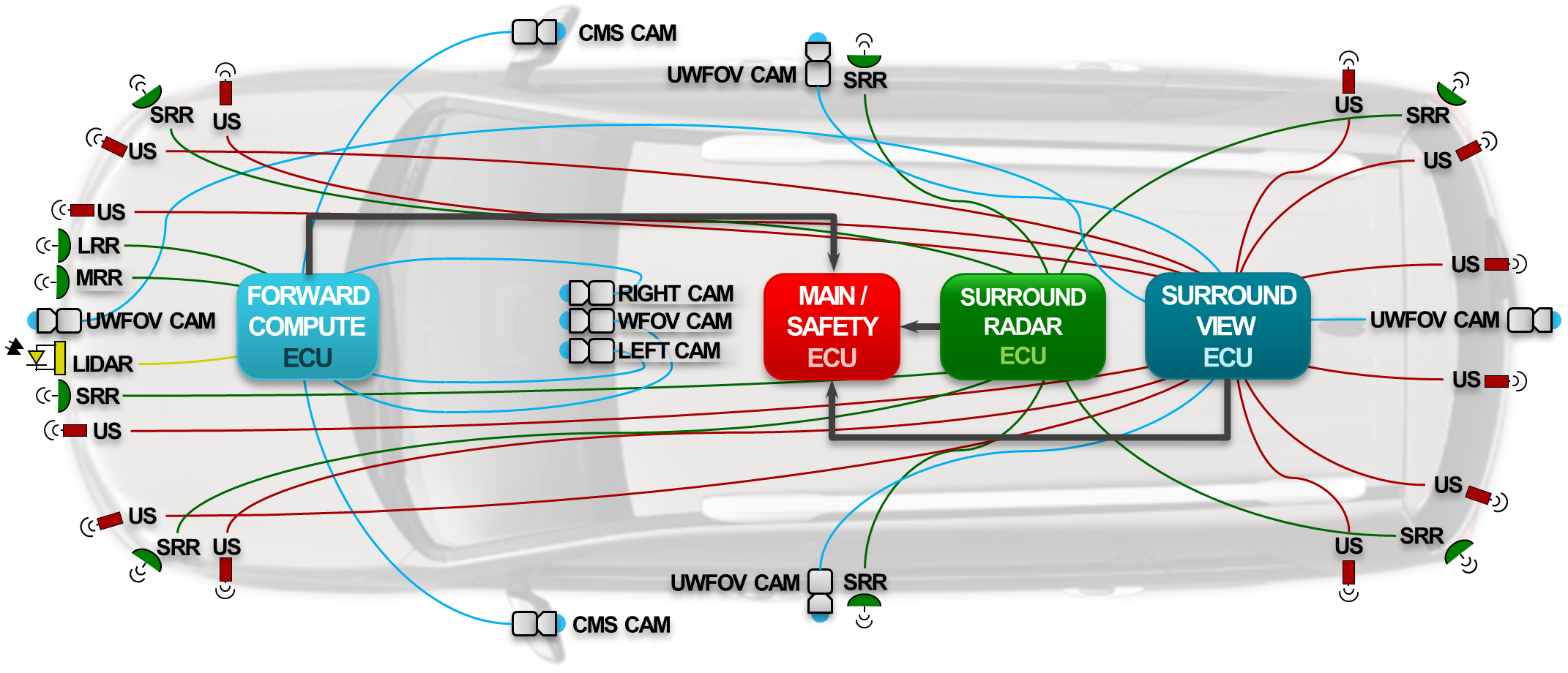
Figure C. The same sensor suite can alternatively be processed using a distributed compute topology, consisting of multiple ECUs, each tailored to handle specific functions (courtesy Texas Instruments).
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. Tend Insights, Texas Instruments and Xilinx, the co-authors of this article, are members of the Embedded Vision Alliance. The Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other deep learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance and its member companies periodically deliver webinars on a variety of technical topics. Access to on-demand archive webinars, along with information about upcoming live webinars, is available on the Alliance website. Also, beginning on July 13, 2017 in Santa Clara, California and expanding to other U.S. and international locations in subsequent months, the Embedded Vision Alliance will offer "Deep Learning for Computer Vision with TensorFlow," a full-day technical training class. See the Alliance website for additional information and online registration.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, is intended for product creators interested in incorporating visual intelligence into electronic systems and software. The Embedded Vision Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Embedded Vision Summit is intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit took place in Santa Clara, California on May 1-3, 2017; a slide set along with both demonstration and presentation videos from the event are now in the process of being published on the Alliance website. The next Embedded Vision Summit is scheduled for May 22-24, 2018, again in Santa Clara, California; mark your calendars and plan to attend.