| LETTER FROM THE EDITOR |
|
Dear Colleague,
If you're creating algorithms and software that enable systems to see and understand the world around them and want to quickly come up to speed on using the popular TensorFlow framework, don't miss our full-day, hands-on training class next month: Deep Learning for Computer Vision with TensorFlow. It takes place on July 13, 2017 in Santa Clara, California. Time is running out: use promo code EARLYBIRD by June 15th for a 15% discount! Learn more and register at https://tensorflow.embedded-vision.com.
If you're interested in creating efficient computer vision software for embedded applications, check out next week's (Wednesday, June 14, 10 am PT) free webinar, "Develop Smart Computer Vision Solutions Faster," delivered by Intel and organized by the Embedded Vision Alliance. Learn how to optimize for high performance and power efficiency, then integrate visual understanding by accelerating deep learning inference and classical computer vision operations with free expert software tools. Take advantage of an API, algorithms, custom kernels, code samples, and how-to examples that speed your development. Ensure you tap into the full power of Intel processors that you use today! To register, see the event page.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
| GPUS FOR VISION ACCELERATION |
|
Using SGEMM and FFTs to Accelerate Deep Learning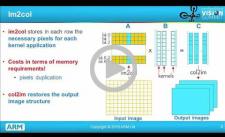
Matrix multiplication and the Fast Fourier Transform are numerical foundation stones for a wide range of scientific algorithms. With the emergence of deep learning, they are becoming even more important, particularly as use cases extend into mobile and embedded devices. In this presentation, Gian Marco Iodice, Software Engineer at ARM, discusses and analyzes how these two key, computationally-intensive algorithms can be used to gain significant performance improvements for convolutional neural network (CNN) implementations. After a brief introduction to the nature of CNN computations, Iodice explores the use of GEMM (General Matrix Multiplication) and mixed-radix FFTs to accelerate 3D convolution. He shows examples of OpenCL implementations of these functions and highlights their advantages, limitations and trade-offs. Central to the techniques explored is an emphasis on cache-efficient memory accesses and the crucial role of reduced-precision data types.
Efficient Convolutional Neural Network Inference on Mobile GPUs
GPUs have become established as a key tool for training of deep learning algorithms. Deploying those algorithms on end devices is a key enabler to their commercial success and mobile GPUs are proving to be an efficient target processor that is readily available in end devices today. This talk from Paul Brasnett, Principal Research Engineer at Imagination Technologies, looks at how to approach the task of deploying convolutional neural networks (CNNs) on mobile GPUs today. Brasnett explores the key primitives for CNN inference, along with strategies for implementation. He works through alternative options and trade-offs, and provides reference performance analysis on mobile GPUs, using the PowerVR architecture as a case study.
|
| VISION PROCESSOR OPPORTUNITIES |
|
Programming Embedded Vision Processors Using OpenVX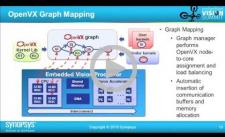
OpenVX, a new Khronos standard for embedded computer vision processing, defines a higher level of abstraction for algorithm specification, with the goal of enabling platform and tool innovation. The end result is a standard way for vision application developers to express vision algorithms while respecting the significant power and performance constraints of embedded systems. Pierre Paulin, Senior R&D Director for Embedded Vision at Synopsys, explores the challenges of realizing these goals when confronted with real-world examples and architectures. A video surveillance application example illustrates typical issues that can arise when applying the OpenVX programming model, as well as difficulties that must be overcome when mapping on a real system.
Fast Deployment of Low-power Deep Learning on Vision Processors
Image recognition capabilities enabled by deep learning are benefitting more and more applications, including automotive safety, surveillance and drones. This is driving a shift towards running neural networks inside embedded devices. But, there are numerous challenges in squeezing deep learning into resource-limited devices. This presentation from Yair Siegel, Director of Segment Marketing at CEVA, details a fast path for taking a neural network from research into an embedded implementation on a CEVA vision processor core, making use of CEVA’s neural network software framework. Siegel explains how the CEVA framework integrates with existing deep learning development environments like Caffe, and how it can be used to create low-power embedded systems with neural network capabilities.
|
| UPCOMING INDUSTRY EVENTS |
|
Intel Webinar – Develop Smart Computer Vision Solutions Faster: June 14, 2017, 10:00 am PT
Sensors Expo & Conference: June 27-29, 2017, San Jose, California
AIA Webinar – The Future of Embedded Vision Systems: July 11, 2017, 9:00 am PT
Xilinx Webinar Series – OpenCV on Zynq: Accelerating 4k60 Dense Optical Flow and Stereo Vision: July 12, 2017, 10:00 am PT
TensorFlow Training Class: July 13, 2017, Santa Clara, California
TensorFlow Training Class: September 7, 2017, Hamburg, Germany
More Events
|
| FEATURED NEWS |
|
Allied Vision Introduces High-bandwidth Cameras with CoaXPress Interface
ON Semiconductor Improves Imaging Performance for High Resolution Industrial Applications
Inuitive Unveils New Reference Design Featuring Widest Field of View on the Market Today
ARM is Accelerating AI Experiences from Edge to Cloud
XIMEA Awarded the Highest Platinum Level in Vision Systems Design 2017 Innovators Awards Program
More News
|
