This blog post was originally published at Alliance partner organization Khronos' website. It is reprinted here with the permission of the Khronos Group.
There is a wide range of open-source deep learning training networks available today offering researchers and designers plenty of choice when they are setting up their project. Caffe, Tensorflow, Chainer, Theano, Caffe2, the list goes on and is getting longer all the time.
This diversity is great for encouraging innovation, as the different approaches taken by the various frameworks make it possible to access a very wide range of capabilities, and, of course, to add functionality that’s then given back to the community. This helps to drive the virtuous cycle of innovation.
The downside of this, is that all these frameworks advance at different rates with no common way of representing the network structures, the datatypes used, or the weights in the case of the trained network. In fact, there isn’t an agreement on what training data should look like, or how it is represented, even within similar problem domains — but that’s a different (although still important) issue.
This lack of commonality becomes a problem whenever an attempt is made to move a network, trained or otherwise, between frameworks. And, we already know that movement between frameworks is a demonstrated need. There is the issue of whether the actual functionality present in one framework is present in the other, but that has to be addressed in the decision process of whether to attempt the transfer; however, once that has been addressed, there is still the problem of format conversion.
With the many-to-many mapping that exists today, any decision to move to a new framework comes with the headache of making sure a translator exists; it’s not an insurmountable problem, but an overhead that discourages movement and slows down product development. Once you have written the translator, who is to say that the framework representation won’t change, and you’ll have to do it all again? It’s a buzz kill when you have to do it once; it’s a significant problem when you multiply that by all the possible combinations
To that problem, let’s add the rapidly emerging ecosystem of accelerated inference engines in edge devices. The diversity of these devices is huge: we have the whole range from GPU compute through dedicated Vision Processors ( VPUs) to reconfigurable FPGAs and dedicated hardware. The semiconductor industry is entering a period of explosive innovation that is revisiting massively parallel architectures in a big way, and everyone needs to be able to take advantage of these — or they risk being left in the dust. How can they do that in a wild-west environment, where no two accelerators are the same and network representations change at the whim of the framework designers?

Figure 1. Neural Network Ecosystem Fragmentation
Take a step back and recall the early days of the smartphone: the App Store and Google Play drove smartphone success. Without them, we wouldn’t have the world we have today, so, it’s useful to remember that it was the existence of a common platform that made it economically feasible. Among the huge variety of Android phones and even on the iPhone, the underlying platform was essentially the same: an ARM instruction set with the OpenGL® ES graphics API from Khronos™. This was — and, with some additions — is still the glue holding together the entire smartphone app ecosystem.
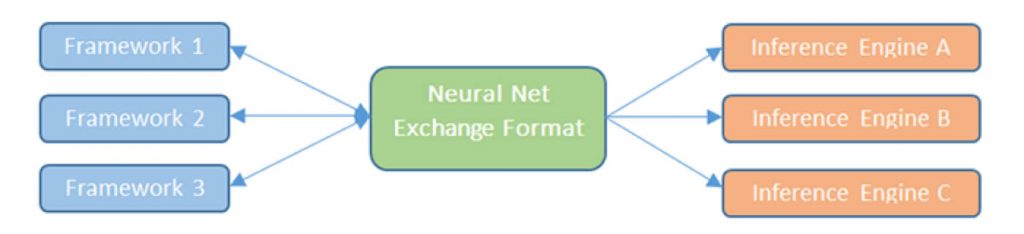
To repeat that success, we need to create an equivalent platform for accelerated machine learning. It’s already important for the training frameworks, but it’s life-or-death critical for the inference engines operating at the edge. This realization drives the linked standards coming from the Khronos Group — the Neural Network Exchange Format (NNEF™) and the OpenVX™ graph-based vision/inferencing API.
NNEF is a universal standard that the whole ecosystem will be able to depend on — a “neural-net pdf” that researchers will be able to use to move networks between frameworks, and for developers to deploy networks onto inference engines. It will neatly solve both problems outlined above by creating a way to describe networks and their weights independently of framework and implementation. Khronos plans to make the new standard available before the end of this year on a royalty-free basis and will support it with open source tools for syntax checking and parsing, plus exporters from various frameworks and an example implementation of an inference engine leveraging OpenVX.

Figure 2. Neural Network Exchange Format – NNEF
OpenVX itself has been available for some time, enjoying rapid adoption among application processor and IoT chip vendors. It standardizes the most common vision functions and was recently extended to allow the inclusion of neural networks as a node within a traditional vision pipeline. OpenVX will be able to import NNEF networks once NNEF 1.0 is released. Together, NNEF and OpenVX provide a standard deployment path for machine learning based apps onto edge devices.
Both OpenVX and NNEF are being developed by the Khronos Group, with its well-proven, open, multi-company governance framework. Any company is welcome to join Khronos and have an equal voice and vote in the evolution of any Khronos standard. More information on joining Khronos is here: https://www.khronos.org/members/.