This blog post was originally published at videantis' website. It is reprinted here with the permission of videantis.
For decades, algorithms engineers have been trying to make computers “see” as well as we do. That’s no small feat: though today’s smartphone cameras provide about the same high-resolution image sensing ability as the human eye—seven megapixels or so—the computer that processes that data is nowhere near a match for the human brain.  Consider that roughly half the neurons in the human cortex are devoted to visual processing, and it’s no surprise it’s a pretty hard task for a computer too.
Consider that roughly half the neurons in the human cortex are devoted to visual processing, and it’s no surprise it’s a pretty hard task for a computer too.
Algorithms engineers have been trying to make computer vision perform as well as our brain for decades, developing increasingly sophisticated algorithms to help machine vision inch its way forward. This process was primarily one of trial and error. In order to make a computer understand a picture, algorithms engineers tried to figure out what kinds of features to look for in the images. Should it look for colors, edges, points, gradients, histograms, or even complex combinations of those? These detected features were then fed into classical machine learning algorithms such as SVM, AdaBoost, and random forests to train them. The results were pretty good — but not really good enough.
Then, in 2012, three developments came together to turbocharge computer vision progress.
First, Princeton University released ImageNet in 2010. ImageNet is a vast collection of millions of images, each one labeled by hand to indicate the objects that are pictured and their corresponding categories. The ImageNet team also launched the Large Scale Visual Recognition Competition (ILSVRC) to see whose algorithms could best match the images to their categories. Since 2010, many computer vision researchers have made winning this competition their focus.
Second, a new kind of algorithm called a convolutional neural network (CNN) had been developed. Compared to traditional computer vision techniques, these “deep” CNNs provide much higher recognition accuracy. But there’s no such thing as a free lunch: CNNs are very much brute force and require lots of compute power and memory.
Third, high-end graphics processors, or GPUs, had evolved far enough to provide ample compute power for the CNN approach. This meant that the millions of images needed to train a CNN could be processed much, much faster than a general-purpose computer could manage at the time—days instead of weeks.
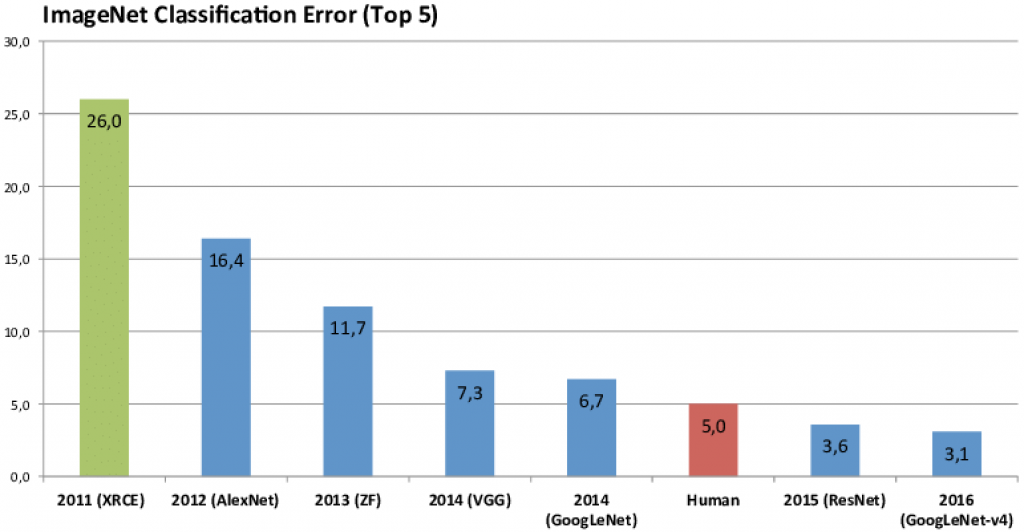
In 2012, Alex Krizhevsky and his team brought these three things together. They fed the labeled ImageNet pictures into powerful GPUs to train a new CNN they called AlexNet. Instead of computer scientists trying to figure out by hand which features to look for in an image, AlexNet figured out what to look for itself. AlexNet entered the ILSVRC and beat the whole field by a whopping 41% margin. Since 2012, every algorithm that’s won the ILSVRC has been based on the same principles.
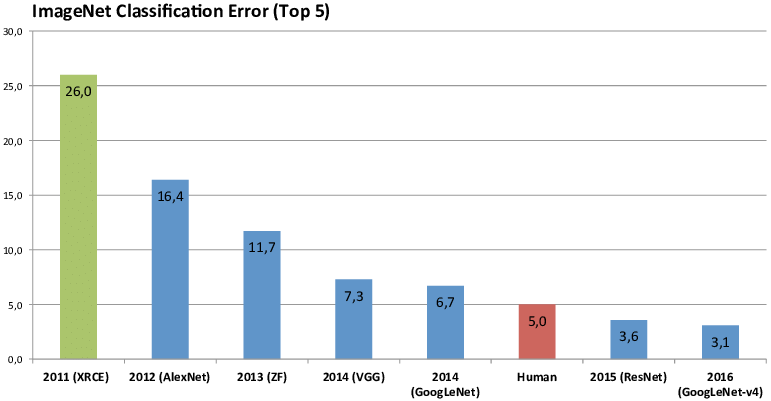
AlexNet was the start of a revolution—not just for computer vision, but for artificial intelligence in general. Researchers working on speech recognition, natural language processing, and every other kind of intelligent data analysis have adopted approaches similar to AlexNet’s.
So what’s a neural network?
Artificial neural networks (ANNs) are loosely modeled on the human brain. An ANN has “neurons” (nodes) that receive input, process it, and send the result to other “neurons.” There can be several layers of nodes, and each layer manipulates its input in a different way. The simplest network has an input layer and an output layer. More complex ANNs have inner (“hidden”) layers. Networks with lots of hidden layers are called “deep.”
What’s a CNN, then?
CNNs are a type of deep ANN that primarily use convolutional operations, or small image filters, in its nodes. The input to a typical CNN is an image; the output is a list of numbers between 0 and 1. These numbers are the CNN’s confidence level for each class of objects it can recognize. If the network has been trained to detect, say, 100 different kinds of objects, it’ll output a list of 100 numbers, most of which will be close to 0 and one of which will be close to 1, for the object it recognized. (A CNN can also recognize more than one object in an image, but we’ll keep things simple here.)
How does a CNN recognize the objects in an image?
The first step is to run the image through a layer of nodes, or filters, that each examine a small section of the image at a time. (This step uses convolutional filters, which is where the name comes from.) Each filter is looking for a specific kind of feature—say, a curve. It outputs an image called a feature map, reporting information about the specific feature it was looking for in the original image. The size and number of filters varies from one CNN to the next. For example, AlexNet uses 96 filters that examine 11×11-pixel blocks, outputting 96 feature maps.
The next step is to perform a nonlinear operation on the feature maps, which “likes” or “dislikes” the results so far. A commonly used operator is ReLU, short for Rectified Linear Unit, which simply sets any negative data to zero and doesn’t touch the other data.
Another layer then performs pooling, which reduces the size of the filtered images. To scale the feature map it received down by a factor of (say) 2, the pooling node looks at each 2×2 group of pixels in the image and calculates a single value from them. (Max pooling is a common approach; it simply takes the maximum value of the group.)
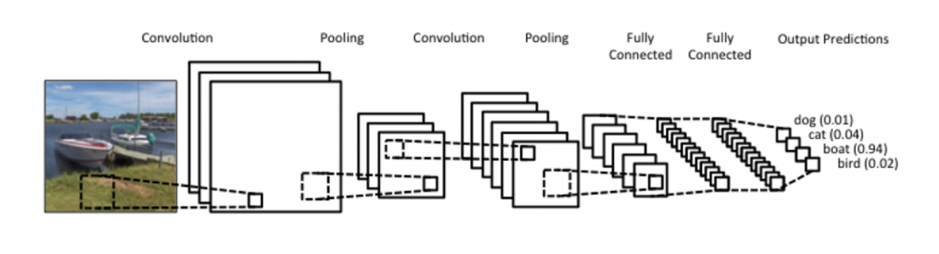
A typical CNN repeats this three-layer process multiple times before finally combining all the data into a single list — the list of confidence levels, where each number in the list corresponds to a single category of objects the CNN is able to recognize.
The types, sizes, depth, and connectivity of the CNN’s different layers determine its detection accuracy, processing load, and memory and bandwidth requirements. With dozens of layers and hundreds or thousands of filters per layer, the computational complexity quickly adds up. Of course, all the filter weights and intermediate data also have to be stored in memory somewhere. Typical CNNs require many billions or even trillions of operations per image, and tens or hundreds of megabytes to store the filter weights and intermediate data.
How does a CNN learn which objects to recognize?
Before a CNN can identify the objects in an image, you have to train it. First, you initialize the CNN by putting in random values for the weights at each node. Then you feed the CNN many image examples along with the expected output. (For example, you might give a CNN you’re training to identify different fruits a picture of a strawberry and an output list that has a zero everywhere except in the “strawberry” position, where it has a 1.) The CNN will process the input picture to create its own output list; then it will calculate the error between its output and the expected output. It uses this information to adjust all the filter weights in every layer, then repeats the whole process, over and over, until it gets the picture right. Clearly, training requires orders of magnitude more processing than recognition.
So far we’ve discussed using CNNs to recognize objects, but there are other vision-related tasks a network might do. For example, a CNN might segment a picture, determining whether pixels belong to the foreground or background. And CNNs can be more complex than we’ve described above, skipping layers or feeding their own output back into the network.
We’re still not there yet
As we noted above, CNNs are vastly better at recognizing objects than are traditional computer vision techniques, but that accuracy comes at a price: lots of compute power, memory, and bandwidth. GPUs seem to be a natural target for CNNs, but their compute density is still much too low to bring real-time object recognition to embedded low-power devices like your smartphone or intelligent cameras in your car.
What’s more, CNN architecture is still an extremely active field of research. Most researchers are looking to beat the current state of the art and reach even higher accuracy, making more complex networks that require even more compute power. Some researchers are working to shrink CNNs for use on embedded platforms, but this usually impacts the network’s accuracy.
But we’re moving forward! Specialized hardware to run CNNs can really help. There’s a clear need for software-programmable and flexible processor architectures that meet the low-power and high-performance requirements to put CNNs into consumers’ hands. That’s exactly what we’ve built at videantis. We’re happy to be working with our customers to bring deep learning technology to your car, your AR or VR headset, and your phone, for starters.
Links
- An intuitive explanation of CNNs by Ujjwal Karn, about 4000 words
- Play around with neural networks in your browser in the TensorFlow playground
Marco Jacobs
Vice President of Marketing, videantis