Key to the widespread adoption of embedded vision is the ease of developing software that runs efficiently on a diversity of hardware platforms, with high performance, low power consumption and cost-effective system resource needs. In the past, this combination of objectives has been a tall order, since it has historically required significant code optimization for particular device architectures, thereby hampering portability to other architectures. Fortunately, this situation is changing with the maturation of the OpenVX standard created and maintained by the Khronos Group. This article provides implementation details of several design examples that leverage various capabilities of the standard.
OpenVX, an API from the Khronos Group, is an open standard for developing computer vision applications that are portable to a wide variety of computing platforms. It uses the concept of a computation graph to abstract the compute operations and data movement required by an algorithm, so that a broad range of hardware options can be used to execute the algorithm. An OpenVX implementation targeting a particular hardware platform translates the graph created by the application programmer into the instructions needed to execute efficiently on that hardware. Such flexibility means that the programmer will not need to rewrite his or her code when re-targeting new hardware, or to write new code specific to that hardware, making OpenVX a cross-platform API.
A previously published article in this series covered the initial v1.0 OpenVX specification and provided an overview of the standard’s objectives, along with an explanation of its capabilities, as they existed in early 2016. This follow-on article showcases several case study examples of OpenVX implementations in various applications, leveraging multiple hardware platforms along with both traditional and deep learning computer vision algorithms. And it introduces readers to an industry alliance created to help product creators incorporate practical computer vision capabilities into their hardware and software, along with outlining the technical resources that this alliance provides (see sidebar “Additional Developer Assistance“).
A companion article focuses on more recent updates to the OpenVX API, up to and including latest v1.2 of the specification and associated conformance tests, along with the recently published set of extensions that OpenVX implementers can optionally provide. It also discusses the optimization opportunities available with SoCs’ increasingly common heterogeneous computing architectures.
Implementation Case Study: Tiling and Vendor Custom Kernels
As the introductory section of this article notes, one key benefit of OpenVX is its ability to enable the development of computer vision applications that are portable to a wide variety of computing platforms. The following section, authored by Cadence, details an example design that leverages a vision DSP core in conjunction with a vendor-developed custom OpenVX extension for acceleration of traditional computer vision algorithms.
This section provides a detailed case study of how to leverage the graph-based OpenVX API in order to automatically implement tile-based processing, a particularly important optimization for DSP architectures. It describes a commercially available OpenVX v1.1-compliant implementation of automated tile-based processing for Cadence Tensilica Vision DSPs. In addition to automating tiling optimizations for the standard OpenVX kernels, the Cadence Tensilica implementation extends the OpenVX API to enable automated tiling of user-defined kernels that run on the Vision DSP. Tile management is handled entirely by Cadence’s OpenVX extension, so the developer can focus on the kernel computation, not the complexities of memory management and data movement.
Tiling
One of the most important considerations for a DSP, in order to deliver low power consumption and high performance, is to enable it to efficiently handle data movement. In most cases, the DSP includes relatively small, fast, tightly coupled memories (TCM), as well as a set of DMA channels to efficiently handle transfers between system memory (usually DDR SDRAM) and the tightly coupled local memories.
“Tiling” is a key optimization, particularly when processing images. Tiling consists of breaking up each image into a set of sub-images, called tiles. Instead of executing the OpenVX graph at full-image granularity, node after node, the tiling approach instead involves executing the graph tile by tile. This technique allows the DSP to keep intermediate tiles in its TCM; the degree of tiling efficiency therefore heavily depends on the data access pattern of the algorithm.
In general, the union of all tiles needs to cover the entire image surface. In certain situations, however, there will be overlap between tiles of the same image, which means that some pixels may be fetched or computed twice (or more) (Figure 1). Such overlap occurs when larger input tiles are needed to compute an output tile of a given size (the neighborhood kernel property), and this constraint propagates across the graph. A typical example is the NxM convolution kernel, for which generating an output tile of a certain size will require a larger input tile, also encompassing what is commonly called a neighborhood or halo of additional pixels.
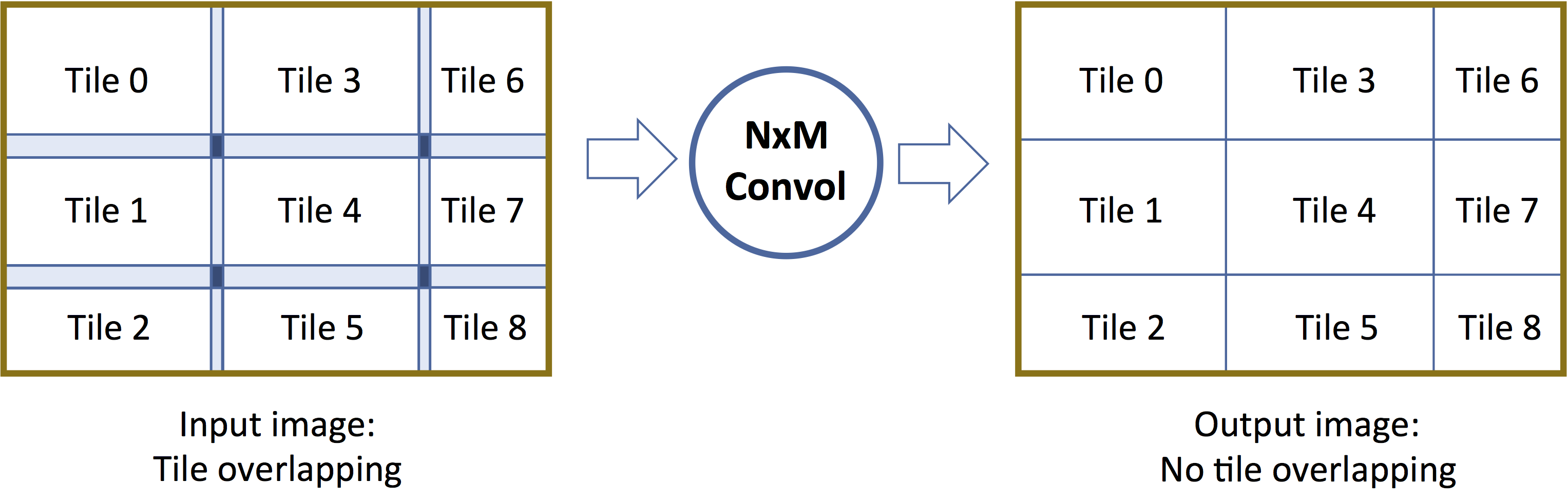
Figure 1. The union of all tiles needs to cover the entire image surface; in certain situations, there will be overlap between tiles (courtesy Cadence).
Tiling and OpenVX
In OpenVX, many of the kernels that operate on an image are not simple pixel-wise functions. More generally, tiling is a complex task. Multiple parameters require consideration, such as the data access pattern of the algorithm implemented by the OpenVX node (including the neighborhood), the graph connectivity, the fact that some kernels may scale images, and the available local memory size. Some nodes may also not be tilable or are only partially tilable (i.e., the input image is tilable but the output image is not). Also, in computer vision, it is not all about images; other data structures such as arrays (containing keypoints, for example) also find use. In case a neighborhood is required for tiles, some specific actions, depending on the node border mode, must be performed when the tile is at the edge of the image. All of these factors require consideration in order to ensure proper graph execution.
Cadence’s OpenVX implementation supports tiling for standard kernels. In OpenVX, the tiling optimization can be done efficiently, thanks to the graph construct that upfront provides the dataflow relationships of the vision algorithm. This “ahead of time” insight is a fundamental advantage for OpenVX in comparison to other libraries such as OpenCV. The tiling optimization process happens at OpenVX graph verification time. The recent “export and import” OpenVX extension will also optionally enable this optimization process to be performed offline on the workstation (depending on the particular use case, either an online or offline solution may be preferable).
Tiling and Extensibility
Cadence’s Tensilica Vision DSPs are hardware- and instruction set-extensible, and customers may therefore be interested in extending their OpenVX implementations with custom vision kernels. This is the case even though OpenVX v1.2 has significantly expanded the number of standard kernels available; application developers may still want to add their own kernels, either to implement a unique algorithm they’ve developed or (in the case of Tensilica Vision DSPs) to take advantage of hardware they’ve designed and included in the DSP.
The OpenVX standard has from the beginning supported so-called “user-defined kernels.” The API is primarily designed to enable the execution of user kernels on the host (i.e., the CPU). Also, OpenVX user kernels operate at full-image granularity, not at tile-level granularity. The OpenVX working group has published a provisional tiling extension specification, discussed earlier in this article, as an initial effort to standardize an approach that’s more suitable for accelerators such as DSPs and GPUs. However, as currently defined the extension is limited in terms of the scope and types of vision kernel patterns it can model.
In order to support a broader set of computer vision patterns, Cadence has developed a proprietary tilable custom kernel extension, called the vendor custom kernel (VCK), which enables users to create their own kernels running on the DSP, seamlessly integrated with the Cadence OpenVX framework. With VCK, kernels may or may not be tilable, depending on user choice. For tilable kernels, the Cadence implementation of the OpenVX framework handles tile management when these kernels are instantiated as nodes in an OpenVX graph. Automated features include:
- Tile sizing, which is dependent on the OpenVX graph structure and the memory usage by other parts of the system (runtime, other kernels, etc.)
- Communication between the host and the DSP
- DSP local memory allocations
- DMA data copy between system and local memories
- Handling the image border mode
In terms of the OpenVX API, VCK extends the concept of OpenVX user kernels. Standard OpenVX user nodes can still be used to create a kernel to be executed on the host processor. VCK expands the Cadence Tensilica Vision DSP’s capabilities to execute user-defined kernels via the OpenVX API.
Vendor Custom Kernel Model
As with standard user kernels, VCK kernels are registered to the OpenVX framework by defining a set of properties and callbacks. The VCK registration API then follows the same approach as the standard user kernel API, and reuses most of its API. However, two major implementation differences exist:
- VCK kernels have both a host side and accelerator/DSP side form; the kernel registration function takes place on both sides (Figure 2).
- VCK supports the notion of tilable images
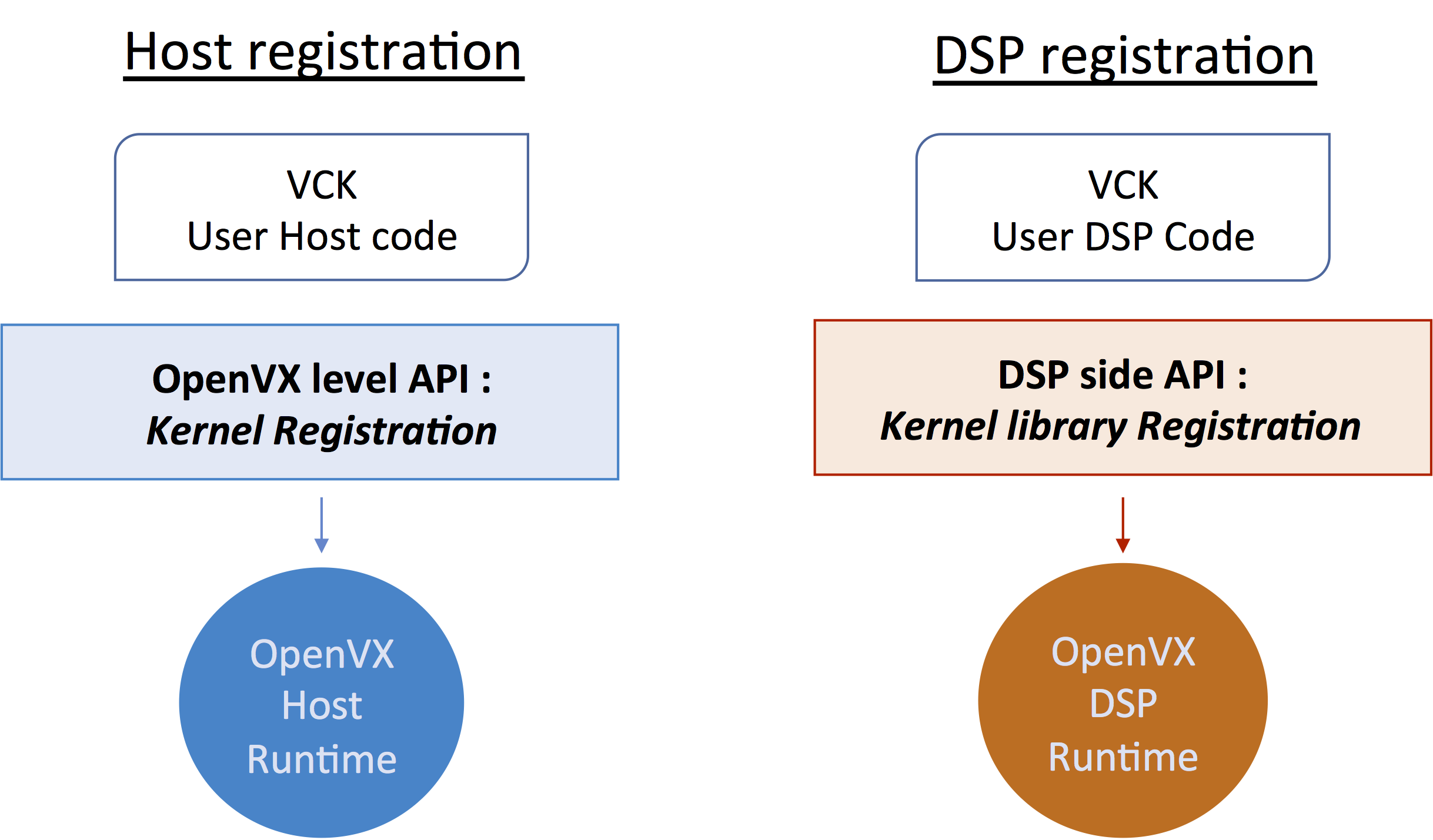
Figure 3. VCK kernel registration occurs on both the host and accelerator/DSP side forms (courtesy Cadence).
On the Vision DSP, VCK kernels are implemented with a set of callback functions that will be called at OpenVX graph execution time (Figure 3):
- The main “processing” function: Its purpose is to process input tiles and generate output tiles.
- An (optional) ‘start’ function: It’s called at graph execution, before any of the tiles start to be processed. It allows for initialization.
- An (optional) ‘end’ function: It’s called at graph execution, after all tile processing has completed. It allows for post-processing, such as when the VCK kernel implements a reduction algorithm.

Figure 3. VCK kernels are implemented with a set of callback functions called at OpenVX graph execution time (courtesy Cadence).
In addition, the VCK developer must provide a kernel dispatch function that will be common to all VCK kernels. The role of this dispatch function is to provide the address of the callback corresponding to an identifier. This way, the Vision DSP OpenVX runtime knows how to call ‘start’, ‘process’ and ‘end’ callbacks when the OpenVX graph is executed.
The VCK kernel is registered on the host, similar to the OpenVX user kernel, before instantiating it as a node in an OpenVX graph. As part of registration, a user needs to provide the following:
- A unique identifier and name
- The list of kernel parameters, their type, their direction, and whether they are mandatory or optional
- A parameter validation callback
- (Optionally) a valid region computation callback
- (Optionally) init and deinit callbacks
In comparison to the OpenVX user kernel, VCK includes some additions:
- Tilable parameters: When the parameter of the kernel is declared with type TENVX_TYPE_TILABLE_IMAGE, this indicates that the image is tilable. For tilable input parameters, a neighborhood region can also be optionally declared. It specifies how many extra pixels on each side of the tile are needed to compute the output. This can be set as the kernel parameter attribute, TENVX_KERNEL_PARAM_TILE_NEIGHBORHOOD. The OpenVX framework will always ensure that this neighborhood region is correctly allocated and initialized, taking into account the case when a border mode is requested for the node.
- Local memory: The execution of a VCK may require some fast temporary memory, which Cadence refers to as “local memory,” on the DSP side. Local memory is allocated by the OpenVX implementation and provided at the execution of the VCK node callbacks. This memory is always allocated in the Vision DSP’s TCM, not in external system memory. The DSP local memory request is done by setting the standard VX_KERNEL_LOCAL_DATA_SIZE kernel attribute if the amount is constant, or by VX_NODE_LOCAL_DATA_SIZE if the amount depends on some aspect(s) of the node parameters (such as the width or height of the input image). Local memory is persistent across the node execution; the same memory will be given to the start, process and end DSP callback functions.
- “Start” and “end” identifiers: Each callback on the DSP side has a unique identifier. In case the VCK kernel includes a “start” and/or “end” DSP callback, the additional identifier(s) need(s) to be provided.
VCK Code Example
The following example implements a simple S16 erode kernel that computes each output pixel as the minimum pixel value of a 5×3 box centered on the same pixel coordinate in the input image.
The kernel identifier must be derived from a kernel library identifier, itself being derived from the company vendor ID. In case the VCK kernel also has a Vision DSP init and end callback, a separate ID should also be allocated for each of them.
Kernel identifiers
// Pick a library ID
#define MY_LIB_VCK (VX_KERNEL_BASE(MY_VENDOR_ID, 0))
// Allocate kernel and DSP callback IDs
enum VCK_SIMPLE_EXAMPLE_KERNEL_IDS {
// XI lib interop example
MY_KERNEL_ERODE_5X3_S16 = MY_LIB_VCK,
};
The kernel host registration differs from standard OpenVX user nodes in that it uses a different registration function (tenvxAddVCKernel), a different parameter type (TENVX_TYPE_IMAGE_TILABLE) and an extra kernel attribute set (TENVX_KERNEL_PARAM_TILE_NEIGHBORHOOD and TENVX_KERNEL_REQ_BORDER). The parameter validation callback, called at OpenVX graph verification time, is the same for VCK and standard user kernels (it is not described in detail here).
#define ERODE_X (5 / 2)
#define ERODE_Y (3 / 2)
kernel_erode = tenvxAddVCKernel(context,
TENVX_TARGET_VISION_XI,
“my.company.vck.erode_5x3_s16”,
MY_KERNEL_ERODE_5X3_S16,
2, // Two parameters
node_parameter_validation, NULL,
NULL, // No host init/deinit
TENVX_KERNEL_NO_ENTRY, TENVX_KERNEL_NO_ENTRY // No DSP start/end
);
// Register kernel parameters
vxAddParameterToKernel(kernel_erode, 0, VX_INPUT, TENVX_TYPE_IMAGE_TILABLE, VX_PARAMETER_STATE_REQUIRED);
vxAddParameterToKernel(kernel_erode, 1, VX_OUTPUT, TENVX_TYPE_IMAGE_TILABLE, VX_PARAMETER_STATE_REQUIRED);
// Request a neighborhood to the tile corresponding to the erode properties
tenvx_neighborhood_size_t nbh;
nbh.left = nbh.right = ERODE_X; nbh.top = nbh.bottom = ERODE_Y;
tenvxSetKernelParamAttribute(kernel_erode, 0, TENVX_KERNEL_PARAM_TILE_NEIGHBORHOOD, &nbh, sizeof(nbh));
// Request the Replicate border mode
vx_border_t border;
border.mode = VX_BORDER_REPLICATE;
vxSetKernelAttribute(kernel_erode, TENVX_KERNEL_REQ_BORDER, &border, sizeof(border));
// Finalize the kernel registration
vxFinalizeKernel(kernel_erode);
As with standard OpenVX user nodes, VCKs are instantiated as OpenVX nodes by calling vxCreateGenericNode and setting parameters one by one. To simplify the use of such nodes, it is usual to provide a node creation function.
vx_node erode5x3S16Node(vx_graph graph, vx_image in, vx_image out) {
vx_node node = vxCreateGenericNode(graph, kernel_erode);
if (vxGetStatus((vx_reference)node) == VX_SUCCESS) {
vxSetParameterByIndex(node, 0, (vx_reference)in);
vxSetParameterByIndex(node, 1, (vx_reference)out);
}
return node;
}
The main Vision DSP callback function takes an array of void * elements as input. It is the responsibility of the user code to cast this address to the type corresponding to the kernel parameter type.
#define ERODE_X (5 / 2)
#define ERODE_Y (3 / 2)
vx_status erode_process(void **args) {
vck_vxTile in = (vck_vxTile)args[0];
vck_vxTile out = (vck_vxTile)args[1];
// Input and output images have the same format, tiles then have the same size and position in their respective image
vx_uint32 tile_width = vck_vxGetTileWidth(in, 0);
vx_uint32 tile_height = vck_vxGetTileHeight(in, 0);
// Perform the Erode operation
int x, y, xx, yy;
vx_uint8 *line_in_ptr8 = (vx_uint8 *)vck_vxGetTilePtr(in, 0);
vx_size tilePitchIn = vck_vxGetTilePitch(in, 0); // In bytes
vx_uint8 *line_out_ptr8 = (vx_uint8 *)vck_vxGetTilePtr(out, 0);
vx_size tilePitchOut = vck_vxGetTilePitch(out, 0); // In bytes
for (y = 0; y < tile_height; y++) {
vx_uint8 *pixel_in_ptr8 = line_in_ptr8;
vx_int16 *pixel_out_ptr16 = (vx_int16 *)line_out_ptr8;
for (x = 0; x < tile_width; x++) {
// Compute the output value
vx_int16 value = 0x7FFF;
for (yy = -ERODE_Y; yy <= ERODE_Y; yy++) {
for (xx = -ERODE_X; xx <= ERODE_X; xx++) {
vx_int16 *pixel_ptr = ((vx_int16 *)(pixel_in_ptr8 + yy * tilePitchIn)) + xx;
value = *pixel_ptr < value ? *pixel_ptr : value;
}
}
// Write the output pixel
*pixel_out_ptr16 = value;
// Next pixel
pixel_in_ptr8 += sizeof(vx_int16);
pixel_out_ptr16++;
}
// Next line
line_in_ptr8 += tilePitchIn;
line_out_ptr8 += tilePitchOut;
}
return VX_SUCCESS;
}
The registration of kernel callbacks is done by registering a dispatch callback with the VCK kernel library via the vck_vxRegisterDispatchCallback function, prior to the application calling any OpenVX API functions. The registered callback will be called whenever a kernel with an ID derived from the library ID needs to be executed.
// VCK kernel library dispatch callback
static vck_vx_kernel_f vck_kernellib_callback(vx_enum kernel_id) {
switch (kernel_id) {
// Only one kernel in this simple example
case MY_KERNEL_ERODE_5X3_S16:
return &erode_process;
default:
return NULL;
}
}
// VCK kernel library registration
void register_vck_lib(void) {
vck_vxRegisterDispatchCallback(MY_LIB_VCK, &vck_kernellib_callback);
}
The previous discussion and code samples show one example of how the OpenVX API can be used to enable programmers to efficiently leverage powerful and highly optimized hardware without writing extensive hardware-specific (i.e., non-portable) code. Developers who are unfamiliar with a given architecture (in this case, Cadence Tensilica Vision DSPs with tightly-coupled memories and DMA engines) can nonetheless reap the benefits of high performance and efficient architectures via the OpenVX API. This combination of efficiency and portability is made possible by the OpenVX API’s graph-based nature.
Thierry Lepley
Software Architect, Cadence Design Systems
Implementation Case Study: Deep Learning Inference Acceleration
Newer versions of both the base OpenVX specification and its extensions include support for the increasingly popular deep learning-based methods of computer vision algorithm development. The following section, authored by VeriSilicon, details an example design that leverages hardware acceleration of deep learning inference for computer vision
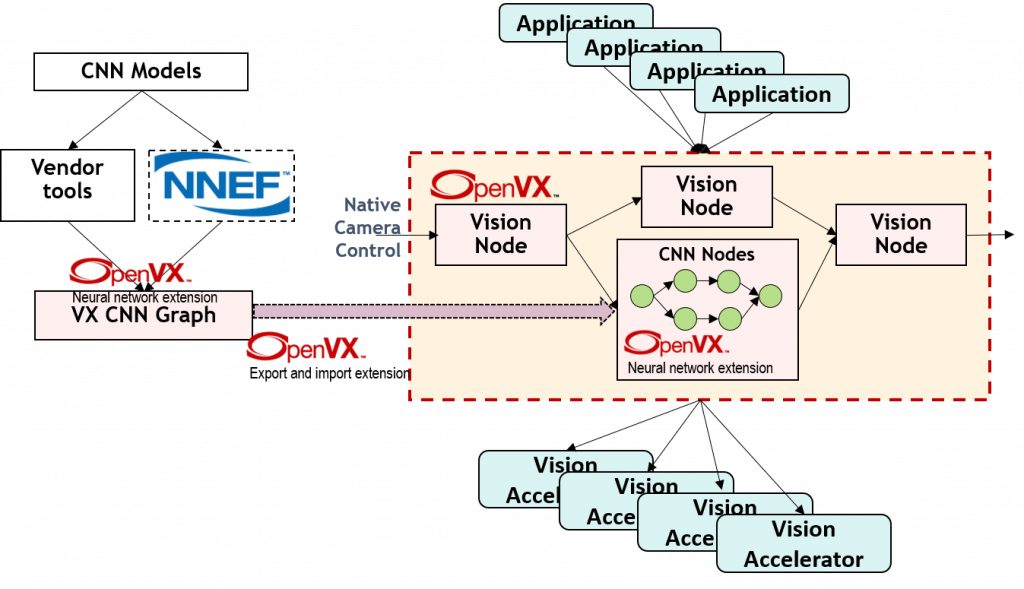
Deep learning support is one of the major focuses for Khronos, beginning with OpenVX v1.2. CNN inferencing for computer vision is a common use case. Using the Faster R-CNN model as an example, this section will explore how OpenVX in combination with an embedded processor, such as one of VeriSilicon’s VIP cores, enables CNN inference acceleration (Figure 4).
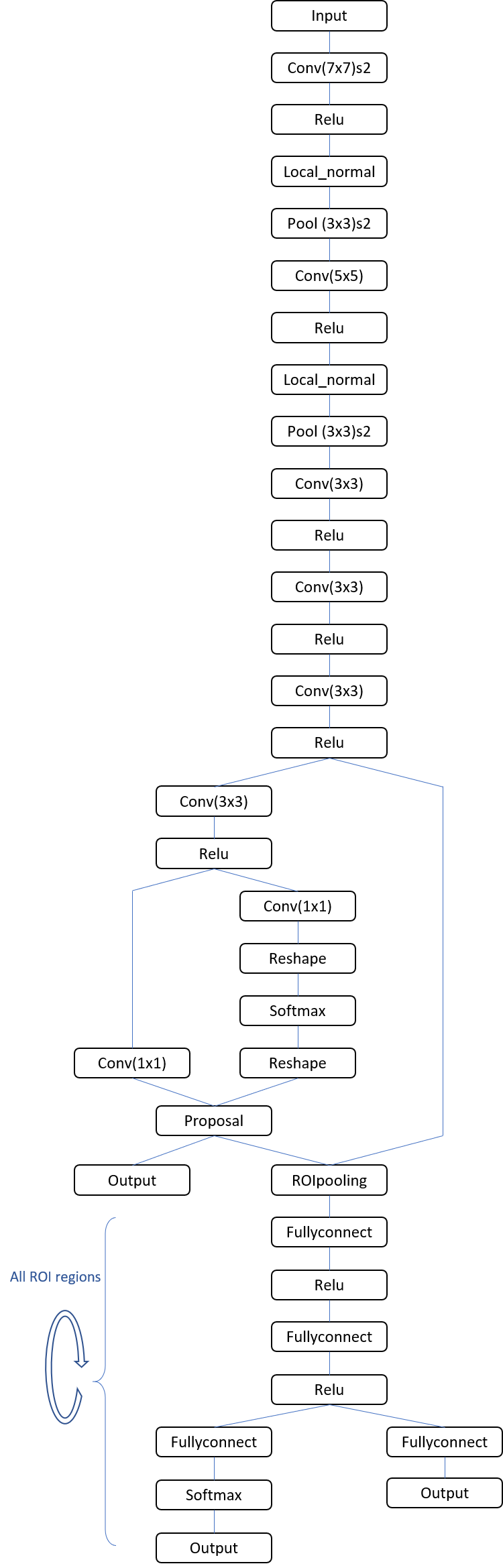
Figure 4. A Faster R-CNN model exemplifies how OpenVX, in combination with a GPU, enables CNN inference acceleration (courtesy Khronos).
Converting Floating-point CNN Models to 8-bit Integer CNN Models
Today’s CNN frameworks primarily focus on floating-point data types, whereas most embedded devices favor integer data in order to achieve higher performance and lower power consumption, as well as to require lower bandwidth and storage capacity. The OpenVX vx_tensor object has been developed to naturally support the dynamic fixed-point integer data type. Specifically, the 8-bit dynamic fixed-point integer data type has been widely adopted by the industry for CNN inference acceleration.
The OpenVX neural network extension is an inference-dedicated execution API focusing on embedded devices, with 8-bit integer required as the mandatory data type. In this example, the original Faster R-CNN model, using the float data type, is created by the Caffe framework. Subsequent model quantization from float32 to int8 requires additional tools, provided by silicon vendors and/or 3rd party developers. A slight accuracy loss compared to the original float model is to be expected due to quantization. Supplemental tools and techniques (such as re-training) can restore some amount of accuracy; these particular topics are not, however, currently within the OpenVX Working Group’s scope of attention.
Port CNN Models to OpenVX CNN Graphs
The graph is a fundamental algorithm structure common to both OpenVX and CNN frameworks. The OpenVX neural network extension defines standard neural network nodes to build CNN graphs. Application developers can, if they choose, write OpenVX applications that include CNN graphs built from scratch, using OpenVX neural network extension nodes.
Alternatively, it’s possible to port conventional CNN models, pre-trained using CNN frameworks, to OpenVX CNN graphs (Figure 5 and Table 1). The OpenVX export and import extension is then used to load (as a subgraph) each resultant OpenVX CNN graph, merging it into an OpenVX application global graph.
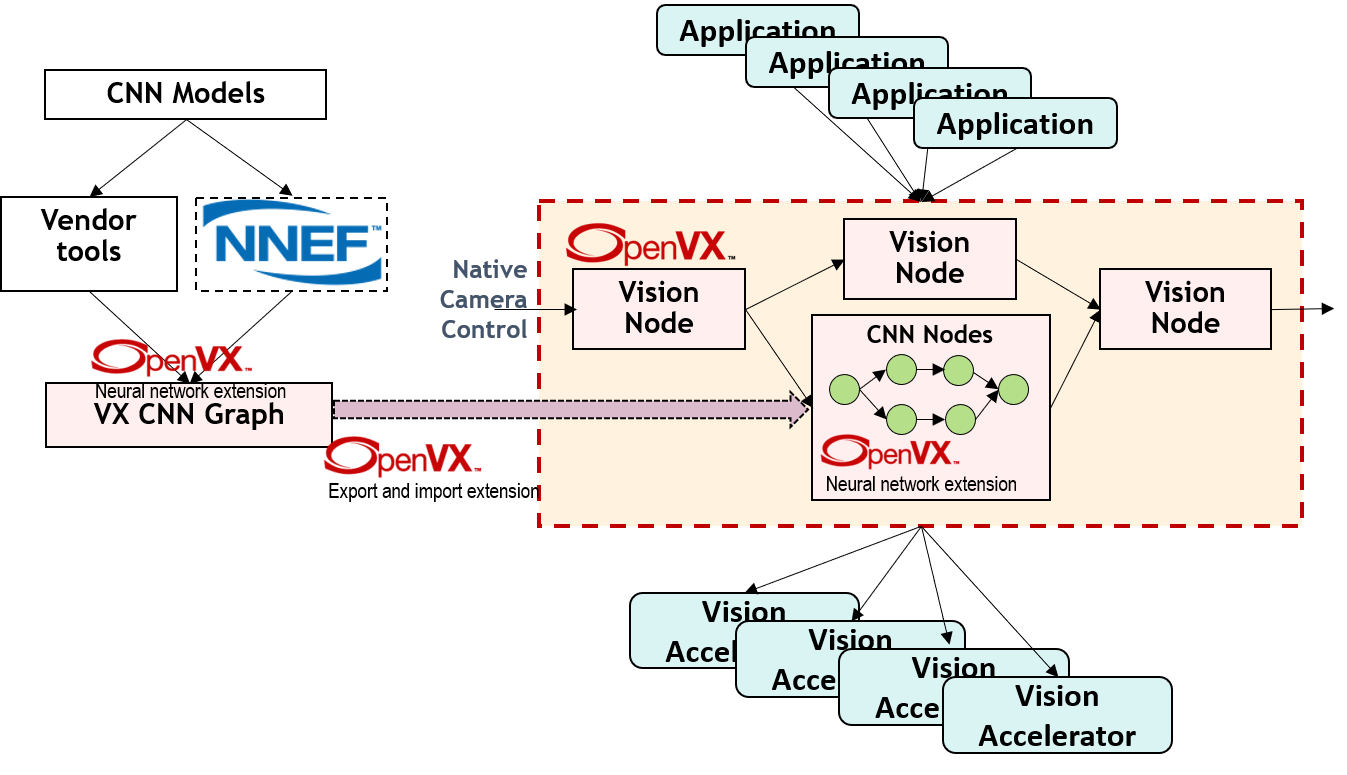
Figure 5. Khronos extensions and interoperability standards are key elements in porting CNN models to OpenVX CNN graphs (courtesy Khronos).
| Faster R-CNN layers (graph nodes) | OpenVX NN nodes |
| convolution | vxConvolutionLayer() |
| Relu activation | vxActivationLayer() |
| Local normalization | vxNormalizationLayer() |
| Pooling | vxPoolingLayer() |
| Softmax | vxSoftmaxLayer() |
| FullyConnect | vxFullyConnectedLayer() |
Table 1. Mapping Faster R-CNN graph nodes to OpenVX neural network extension node functions
Each framework has unique model files used to describe the topology graph and associated weight/bias binaries. Khronos’ NNEF (neural network extension format) standard is designed to act as a bridge between various model descriptions. Intermediary NNEF models can be ported to OpenVX CNN graphs by using Khronos-supplied tools. Some vendors also provide tools which support direct (no NNEF bridge required) porting from frameworks’ CNN models to OpenVX CNN graphs
Deep learning is a fast-paced, rapidly evolving technology area. It should not be a surprise, therefore, to encounter neural network nodes beyond the scope of existing OpenVX neural network extension definitions (Table 2). Some special neural network nodes might also be suitable for CPUs, for example. Fortunately, OpenVX comprehends vendor-customized kernels and user kernels in order to support additional neural network nodes.
| Faster R-CNN layers (graph nodes) | Vendor/User node functions |
| Reshape | Vendor node. A function to change memory layout. |
| Region Proposal | User node. A function including sorting, suitable for CPUs. |
| Dropout | Training-only. A no-op function for inferencing. |
Table 2. Example Faster R-CNN graph nodes beyond the scope of OpenVX v1.2’s neural network extension
OpenVX CNN Graph Optimization
Two general types of graph optimizations are possible: at the application development level, and at the vendor implementation level. Vendor-level optimizations are usually more device-specific, relying on sophisticated graph analysis and leveraging proprietary hardware acceleration capabilities. Application-level optimizations conversely are more use-case specific, relying on deeper knowledge about application tasks. It’s generally recommended to begin optimization work at the application level.
General-purpose OpenVX graph optimization techniques can also benefit CNN graphs. The following CNN-specific graph optimization techniques continue this case study’s use of the Faster R-CNN model example. A conventional Faster R-CNN graph, for example, includes Dropout nodes. Dropout can be disregarded, however, by the inferencing process. The OpenVX Faster R-CNN graph can therefore remove dropout nodes as a simplification step.
The CNN graph node is designed to process tensor type data objects. Tensor fragments are not amenable to vendor implementation-level optimizations, however. Therefore, at the application graph level, developers should as much as possible merge nodes that share the same input. In the Faster R-CNN graph example, the last two fully connected nodes share the same input, and can alternatively be merged as a single fully connected node (Figure 6). In this optimized configuration, the soft-max node can operate on the partial output tensor of the merged fully connected node. Such node merges also can reduce bandwidth requirements.
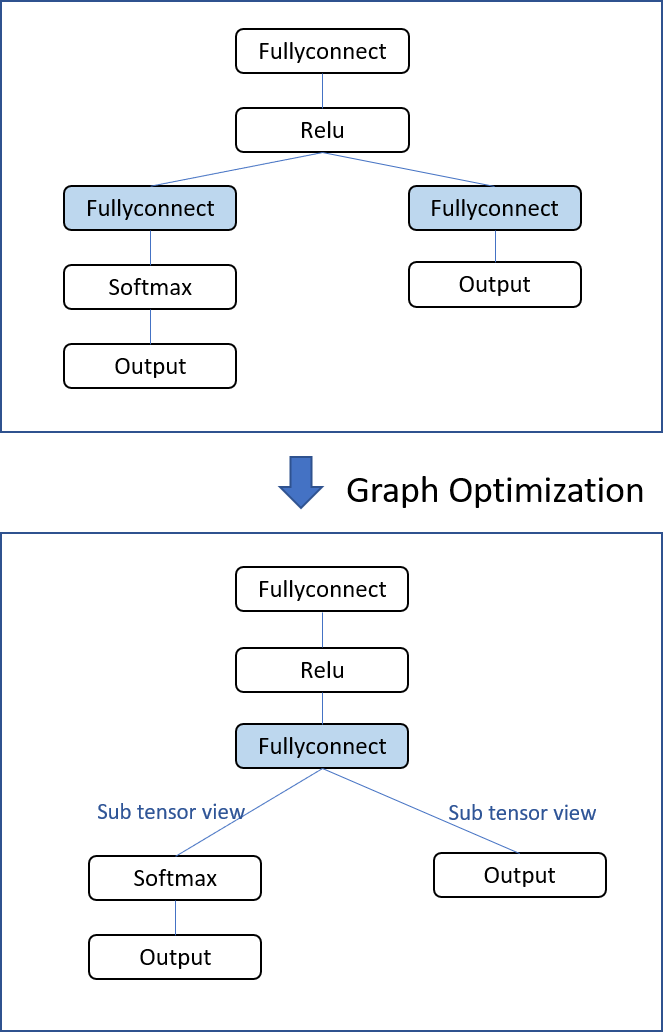
Figure 6. Merging two fully connected nodes is one example of a Faster R-CNN graph optimization (courtesy Khronos).
Packed tensors can also enable more straightforward optimizations at the subsequent vendor implementation level. And the tensor packing concept can be more broadly applied to all Faster R-CNN fully-connected nodes. Without such optimizations, Faster R-CNN fully-connection nodes sequentially apply to individual ROI (region of interest) 1-D tensors, one by one, in a repeating loop (Figure 7). The more efficient alternative approach packs all ROIs together as a 2-D tensor, with repeating fully connected operations consequently equivalent to one-time 1×1 convolution operation. Performance can therefore be significantly improved.
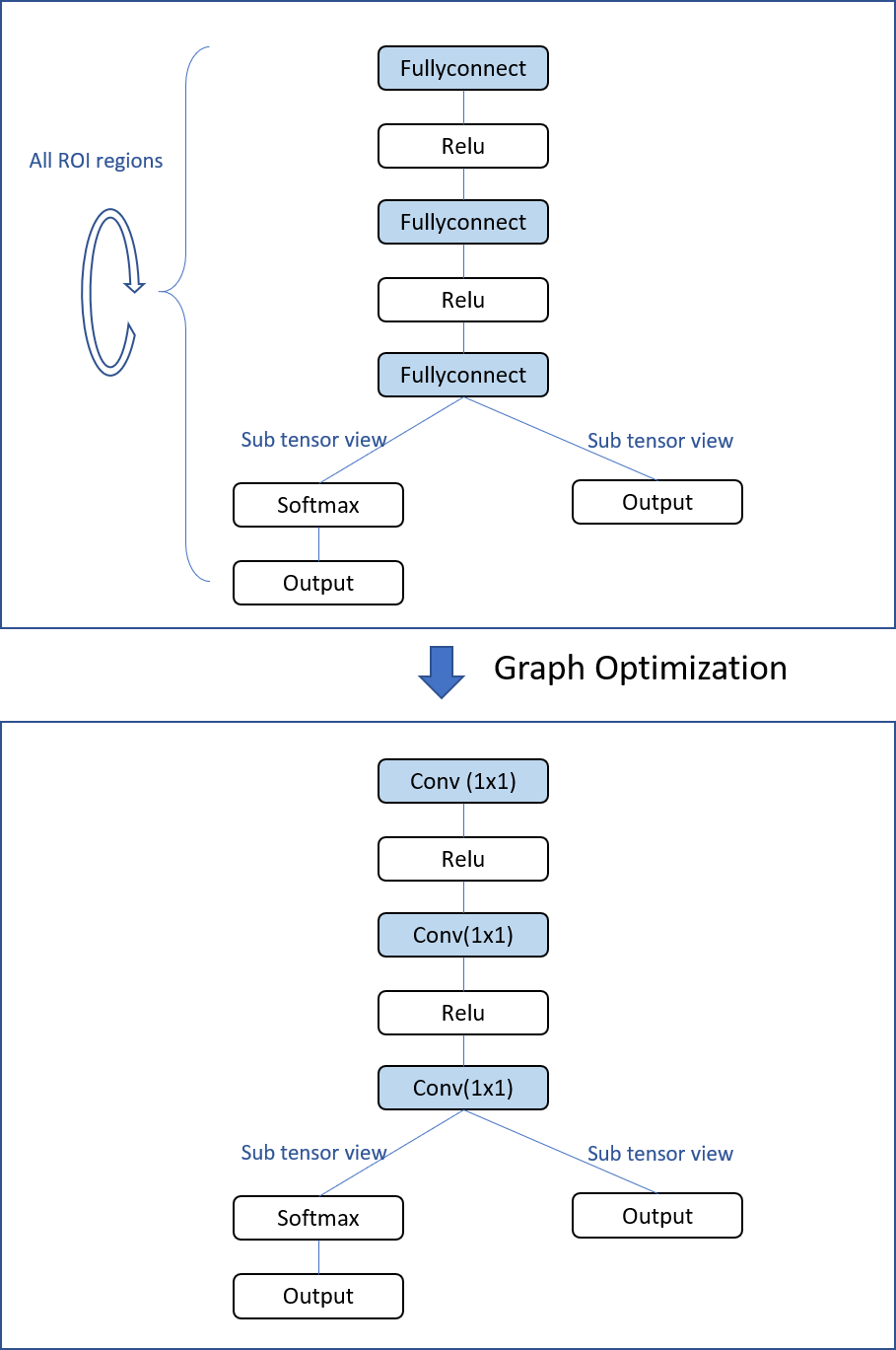
Figure 7. Additional Faster R-CNN graph optimization opportunities come from replacing repeating fully-connected nodes with 1×1 convolution nodes (courtesy Khronos).
Node merging and graph tiling are typical techniques undertaken at the vendor implementation level. Compared to traditional vision processing graphs, CNN graphs typically exhibit well-defined backbone structures with duplicated primitives. Therefore, node merging and tiling optimizations can be relatively straightforward to implement at the vendor implementation level. Performance can also be accurately predicted with the use of vendor profiling tools.
Xin Wang
Senior Director, Vision Architecture, VeriSilicon
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products, and can provide significant new markets for hardware, software and semiconductor suppliers. Key to the widespread adoption of embedded vision is the ease of developing software that runs efficiently on a diversity of hardware platforms, with high performance, low power consumption and cost-effective system resource needs. In the past, this combination of objectives has been challenging, since it has historically required significant code optimization for particular device architectures, thereby hampering portability to other architectures. Fortunately, this situation is changing with the maturation of the OpenVX standard created and maintained by the Khronos Group.
Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Senior Analyst, BDTI
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. Cadence Design Systems, Intel, NXP Semiconductors and VeriSilicon, the co-authors of this series of articles, are members of the Embedded Vision Alliance. The Embedded Vision Alliance’s mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, is intended for product creators interested in incorporating visual intelligence into electronic systems and software. The Embedded Vision Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Embedded Vision Summit is intended to inspire attendees’ imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. The next Embedded Vision Summit is scheduled for May 20-23, 2019 in Santa Clara, California. Mark your calendars and plan to attend; more information, including online registration, will be available on the Embedded Vision Alliance website in the coming months.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other machine learning frameworks. Access is free to all through a simple registration process. And the Embedded Vision Alliance and its member companies also periodically deliver webinars on a variety of technical topics. Access to on-demand archive webinars, along with information about upcoming live webinars, is available on the Embedded Vision Alliance website.