This market research report was originally published at Tractica's website. It is reprinted here with the permission of Tractica.
The world is moving quickly when it comes to AI algorithms and applications. In less than 3 years, the complexity of neural networks (NNs) has increased from single-digit layers to 10s or even 100s of layers, each one requiring compute-intensive convolution and operations such as ReLU and Tanh. Digital signal processing (DSP)-based classic computer vision techniques are becoming outdated and are being replaced by NNs. Increasing numbers of NNs are being used in different stages of the AI application pipeline, further increasing the complexity. Judging by today’s indications, more NNs are expected to appear in the future. This trend has translated into a need for chipsets with large compute capacity, and many players have emerged in recent years that are promising to accelerate AI algorithms.
Fundamentally, the acceleration of AI algorithms boils down to the acceleration of deep neural networks (DNNs). In the case of NN acceleration, at a very basic level, many events take place:
- The weights are typically stored in a file or database (on permanent memory such as Flash) and brought into RAM (that is near the compute engine) as and when needed.
- The chipset performs compute operations on the data and weight as dictated by the algorithm.
- The intermediate results are stored in RAM or written to Flash if RAM is full.
The process is then repeated for every calculation until the result is generated. While the flow is more complicated for training, as there is also a backward pass involved, the point is that there is compute (to perform operations), memory/storage access (for storing weights), and network (for transferring data) involved. To realize true AI application acceleration, all compute, storage, and network need to be enhanced simultaneously.
Understanding the Three Key Parts
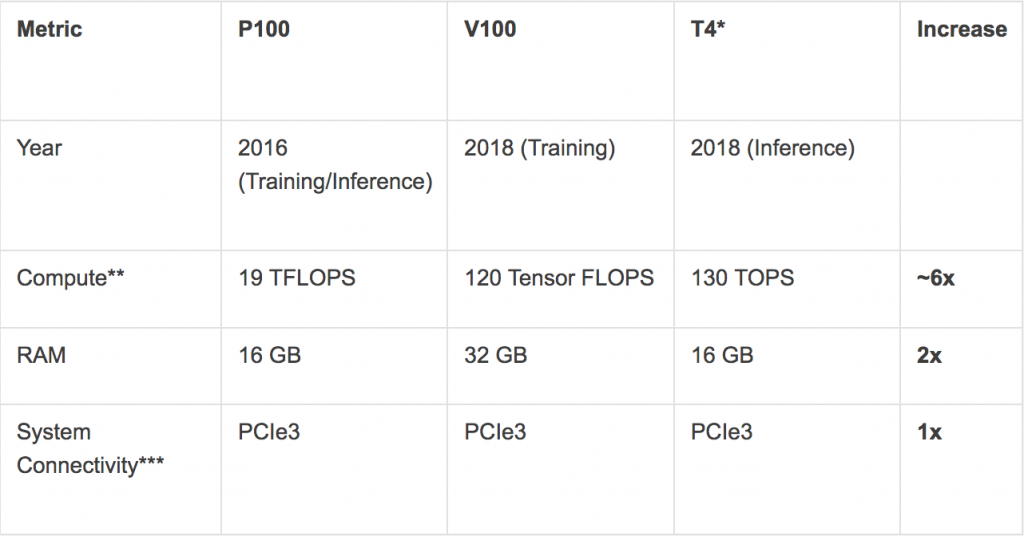
This need for all three parts to work together has not been directly translated into the products available today for AI acceleration. If we consider the products NVIDIA has introduced in the past 2 years (P100, V100, and T4 – see table below), the compute has increased by almost 6x whereas the RAM has increased 2x. There has been little – if any – change in the network or system connectivity.
| Metric | P100 | V100 | T4* |
Increase |
| Year | 2016 (Training/Inference) | 2018 (Training) | 2018 (Inference) | |
| Compute** | 19 TFLOPS | 120 Tensor FLOPS | 130 TOPS | ~6x |
| RAM | 16 GB | 32 GB | 16 GB | 2x |
| System Connectivity*** | PCIe3 | PCIe3 | PCIe3 | 1x |
Select NVIDIA Products: Compute, RAM, and System Connectivity (Sources: Tractica, NVIDIA)
* T4 is targeted toward inferencing, so it doesn’t exactly compare to P100 or V100 but is an interesting comparison point.
** The compute capacity is not an apples-to-apples comparison but we have considered peak capacity.
*** To NVIDIA’s credit, it also has an NVLink version, which offers better speed. However, it’s not considered here because it is proprietary and only works with selected vendors.
AI application is similar to any other IT application used in the industry today. It requires all the different parts of the system – compute, storage, and network – to work in unison to achieve the specified performance requirement. Because compute is always used to describe the performance of AI hardware, all kinds of active debates are occurring within the community. To truly improve application performance, all three would need to be improved.
Correcting the Issue
The industry has noticed this issue, and steps are being taken to correct it. There have been two prominent announcements along these lines. NVIDIA’s acquisition of Mellanox is aimed at solving the network problem, and a new chip introduced by startup Habana includes Ethernet connectivity on the chip. NVIDIA has also introduced NVLink, which is aimed at accelerating the communications onboard, and is shipping products based on it.
The problem gets even more complicated at the system level. The data has to pass through multiple layers of storage and system networks, and there are no benchmarks today to indicate how the scaling might affect overall hardware performance. Most of the applications with AI are in the development and prototyping phase today and we are just starting to understand the combined impact of compute, storage, and network on the production environment.
The increasing complexity of software has been a driver for higher capacity compute and improvements in the semiconductor chipset industry for decades. The complexity of AI algorithms will continue to increase, and the computer architecture will have to keep up. We are at the beginning of the AI revolution, and only time will tell what works best for AI applications.
Anand Joshi
Principal Analyst, Tractica