This blog post was originally published at NVIDIA's website. It is reprinted here with the permission of NVIDIA.
If there’s one constant in AI and deep learning, it’s never-ending optimization to wring every possible bit of performance out of a given platform. Many inference applications benefit from reduced precision, whether it’s mixed precision for recurrent neural networks (RNNs) or INT8 for convolutional neural networks (CNNs), where applications can get 3x+ speedups. NVIDIA’s Turing architecture introduced INT4 precision, which offers yet another speedup opportunity. In addition to computational speedups, using INT4 can also reduce a network’s memory footprint and conserve memory bandwidth, which makes it easier to run multiple ensemble networks on a single GPU.
In addition to being the only company that submitted on all five of MLPerf Inference v0.5’s benchmarks, NVIDIA also submitted in the Open Division an INT4 implementation of ResNet-50v1.5. This implementation delivered a 59% throughput increase with an accuracy loss of less than 1% In this blog, we’ll take you through a brief overview of our INT4 submission, which is derived from earlier research at NVIDIA to assess the performance and accuracy of INT4 inference on Turing.
The code uses a ResNet50 v1.5 pipeline, where the weights have been fine-tuned to allow accurate inference using INT4 residual layers. This code loads the fine-tuned network from the “model” directory used to drive the computation. Internally, the code aggressively fuses layers to produce an efficient high-performance inference engine.
First, we show the performance speedup observed using INT4 precision versus an INT8 baseline. We then describe the model format and computations performed, and finally we’ll describe the process used to fine tune the model weights.
The INT4 Speedup on Turing
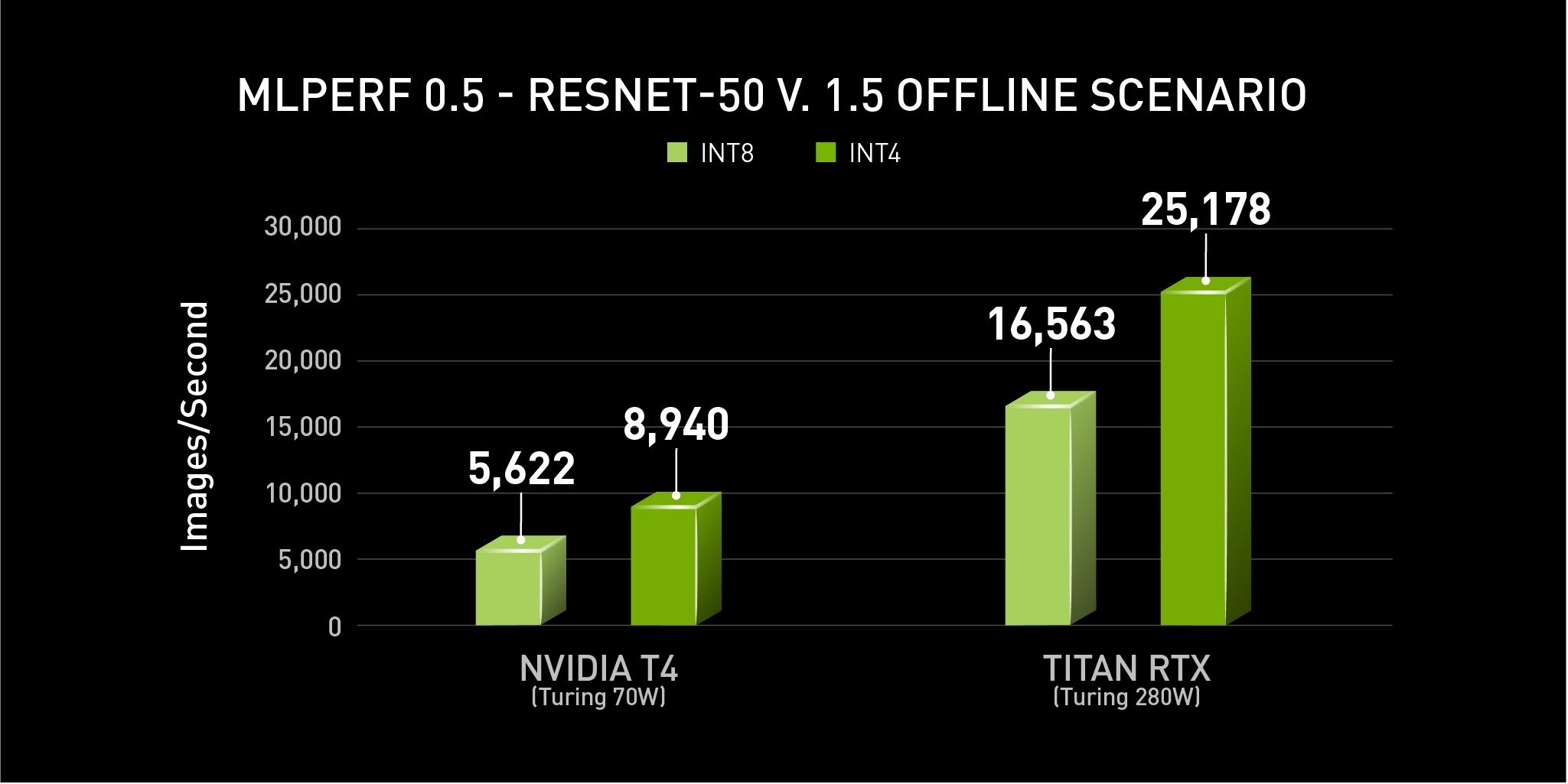
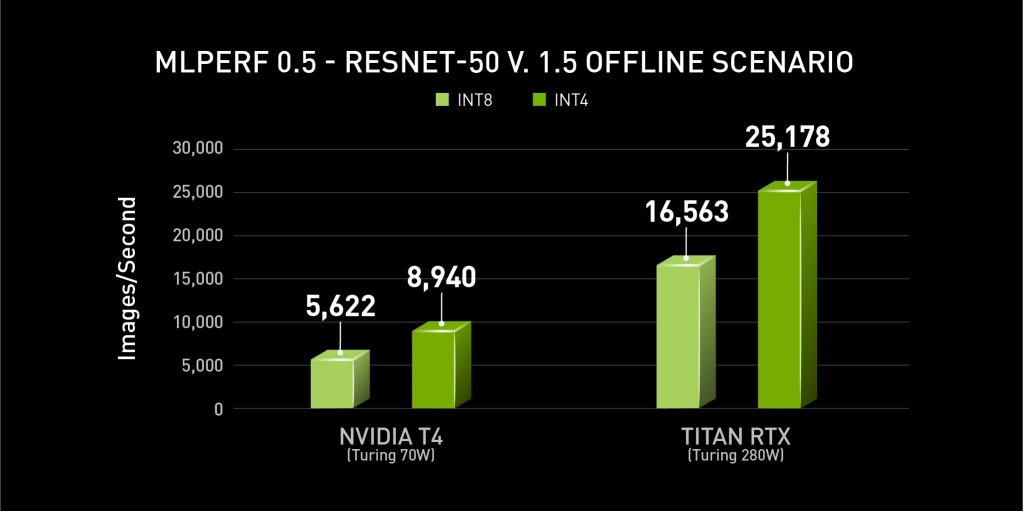
MLPerf v0.5 Inference results for data center server form factors and offline scenario retrieved from www.mlperf.org on Nov. 6, 2019 (Closed Inf-0.5-25 and Inf-0.5-27 for INT8, Open Inf-0.5-460 and Inf-0.5-462 for INT4). Per-processor performance is calculated by dividing the primary metric of total performance by number of accelerators reported. MLPerf name and logo are trademarks.
INT4 netted an additional 59% inference throughput with minimal accuracy loss (~1%) on NVIDIA T4. And on TITAN RTX, the speedup was 52%, yielding over 25,000 images/sec from a single GPU. The performance data shown above were run on servers with multiple GPUs, and the throughput values are derived by taking the server throughput, and dividing by the number of GPUs to show this per-accelerator data.
Model Description
The files needed to run ResNet-50 using INT4 precision can be found here, along with detailed instructions on how to run the harness to reproduce our results.
The INT4 ResNet50 v1.5 network consists of a pipeline of layers, described by files in the “model” directory. At the top level, we have the following layers:
|
Main Pipeline |
|
First Layer Convolution (7×7, with C=3, K=64) |
|
ReLU |
|
Quantize 1 |
|
MaxPool |
|
Layer 1 (sequence of 3 residual networks) |
|
Layer 2 (sequence of 4 residual networks) |
|
Layer 3 (Sequence of 6 residual networks) |
|
Layer 4 (Sequence of 3 residual networks) |
|
AvgPool |
|
Fully Connected |
|
Scale Layer |
Layers 1 through 4 represent sequences of residual networks, where each residual network consists of the following:
|
Residual Network |
|
Resample/Downsample Pipeline |
|
Conv1 (1×1 conv, typically with C=4*K) |
|
ReLU layer |
|
Quantize 1 |
|
Conv2 (3×3 conv, with C=K) |
|
ReLU layer |
|
Quantize 2 |
|
Conv3 (1×1 conv, with 4*C=K) |
|
Eltwise Add |
|
ReLU Layer |
|
Quantize 3 |
The Resample/Downsample pipeline consists of three layers:
|
Optional Convolution Layer |
|
Optional ReLU Layer |
|
Quantize/Dequantize Layer |
For each layer, there is a text file that describes the layer structure and then within the “model/npdata” directory, there are files with actual filter weight, scale and bias values. Additional details about each layer are available here.
Fine-Tuning the Model
Our approach does not require complete retraining the model. We augment the pre-trained FP32 model from torchvision with FP32 quantization layers. The initial parameters for these layers are set using range data collected from running a calibration set through the original model. Then we run training epochs to fine tune the network and quantization layers. The process works as follows:
- Run the calibration dataset through the “quantized” FP32 model and collect histogram data
- Use the histograms to find the 99.999th percentile range value for all tensors
- Adjust the quantization layers in the model with the new ranges
- Run an epoch of the training dataset through the quantized model and back propagate the errors, using a Straight Through Estimator (STE) for the quantization layers. Continue training until the accuracy reaches acceptable levels.
In our case, we used 15 epochs. Once complete, the model is fine tuned and a quantized INT4 model can be generated using the range data from the “fake” quantization layers.
For more information about the fine tuning process, see two papers:
- “Estimating or Propagating Gradients Through Stocahstic Neurons for Conditional Computation“, Bengio et al, http://arxiv.org/abs/1308.3432, Aug 2018.
- “Quantizing deep convolutional networks for efficient inference: A whitepaper“, R. Krishnamoorthi, https://arxiv.org/abs/1806.08342, Jun 2018.
It’s early days for INT4, which can also be accessed through NVIDIA’s CUTLASS library, available on GitHub. Reduced precision for AI inference represents another interesting area where optimizations can yield more performance from the same hardware with minimal accuracy loss. Further areas of investigation include applying INT4 precision to other image-focused networks.
To reproduce the results, download the MLPerf Inference v0.5 Int4 submission code and binaries here
Dave Salvator
Senior Product Marketing Manager, Tesla Group, NVIDIA
Hao Wu
Senior GPU Compute Architect, NVIDIA
Milind Kulkarni
NVIDIA
Niall Emmart
NVIDIA