
This article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
Some of the biggest challenges in deploying an AI-based application are the accuracy of the model and being able to extract insights in real time. There’s a trade-off between accuracy and inference throughput. Making the model more accurate makes the model larger which reduces the inference throughput.
This post series addresses both challenges. In part 1, you train an accurate, deep learning model using a large public dataset and PyTorch. Then, you optimize and infer the RetinaNet model with TensorRT and NVIDIA DeepStream. In part 2, you deploy the model on the edge for real-time inference using DeepStream.
For this post, we trained the deep learning model to find faces using a large public dataset, and then optimized it for fast inference using NVIDIA TensorRT. The output of the application is shown below:
Video: Before redaction. Faces can be clearly seen.
Video: After redaction. We are redacting four copies of the video simultaneously on a Jetson AGX Xavier edge device.
Prerequisites
This post uses the following resources:
- A PyTorch container from NGC for GPU-accelerated training using PyTorch
- The NVIDIA PyTorch implementation of RetinaNet
- Pre-trained RetinaNet model with ResNet34 backbone
- The Open Images v5 dataset [1]
- NVIDIA DGX-1 with eight V100 GPUs to train the model. These cards are available on all major cloud service providers. You can train this using other NVIDIA GPUs, but the training time will vary.
Training
In this post, you learn how to train a RetinaNet network with a ResNet34 backbone for object detection. ResNet34 provides accuracy while being small enough to infer in real time at the edge. We provide a step-by-step guide, covering pulling a container, preparing the dataset, tuning the hyperparameters and training the model. Training uses mixed precision, a technique that dramatically accelerates training without compromising accuracy.
RetinaNet uses focal loss [2], a loss function that increases the influence of difficulty to classify objects. Focal loss emphasizes the harder, misclassified examples. In the graph shown below [Figure 1], between probability of ground truth class versus loss, increasing the gamma value yields a smaller loss for well-classified examples. In the training run, we chose γ=2, but this is one of the hyperparameters that can be tuned for your dataset.
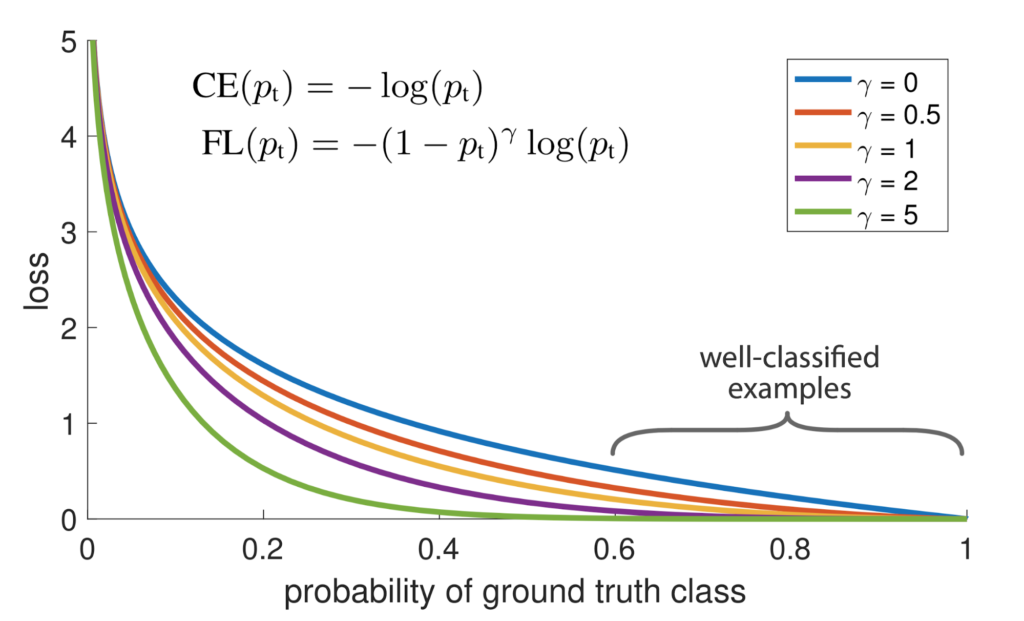
Figure 1: By adding the focal loss, well-classified examples contribute less to the loss than harder examples.
(Image from https://arxiv.org/abs/1708.02002)
Another way to increase accuracy (especially for faces at different scales) is by using a Feature Pyramid Network (FPN) [3]. This is important in detecting faces close to the camera, as well as faces in crowds.
Training overview
This post has the following subsections:
- Data preparation
- Model training
- Model export
The data preparation section covers the steps required to download the data, and then convert it into the required format. In the model training step, we go over the steps to train and evaluate the RetinaNet model. Finally, in the model export step, we show you how to export the model to the popular ONNX format. The ONNX model is used for deployment.

Figure 2: Training workflow
Data preparation
The Open Images v5 dataset is used for training the object detection model. In this section, you trim the dataset to contain only the human face class. Then, you convert the dataset into the COCO format. The data conversion code can be found in the GitHub repo.
1. Clone the repo
git clone https://github.com/NVIDIA-AI-IOT/retinanet_for_redaction_with_deepstream.git
cd retinanet_for_redaction_with_deepstream
This is your working directory.
2. Run the NGC PyTorch container
For training, you need an NGC account. If you do not have one, sign up for a free account and create an API key.
Log in to nvcr.io:
docker login nvcr.io
Run the container:
DATA_DIR=<path to your intended data dir>
WORKING_DIR=<path to working directory>
docker run -it --gpus all --rm --ipc=host -v $DATA_DIR:/data -v $WORKING_DIR:/src -w /src nvcr.io/nvidia/pytorch:19.09-py3
cd /src
From this point, all commands are executed from within the container.
3. Download Open Images
cd /data/open_images
bash /src/open_images/download_open_images.sh
bash /src/open_images/unzip_open_images.sh
4. Convert the validation annotations to JSON
The code in this section can be found in open_images/open_image_to_json.py.
Start by defining the Open Images validation images and annotation files, and by choosing a location to save your annotations.
images_dir = '/data/open_images/validation'
annotation_csv = '/data/open_images/validation-annotations-bbox.csv'
category_csv = '/data/open_images/class-descriptions-boxable.csv'
output_json = '/data/open_images/processed_val/val_faces.json'
# Read the Open Images categories and parse the data.
import open_images.open_image_to_json as oij catmid2name = oij.read
catMIDtoname(category_csv) # Read the category names
oidata = oij.parse_open_images(annotation_csv) # This is a representation of our dataset.
# Next, remove all the images that do not contain the class ‘human face’.
set1 = oij.reduce_data(oidata, catmid2name, keep_classes=['Human face'])
# Finally convert this data to COCO format, using this as an opportunity to exclude two sorts of annotations:
# 1. If the images were to be resized so that the longest edge was 864 pixels (set by the max_size parameter), then exclude any annotations smaller than 2 x 2 pixels (min_ann_size parameter).
# 2. Exclude any annotations (and the images they are associated with) if the width to height ratio exceeds 2.0, set by the min_ratio parameter. This filters out annotations that cover a large crowd of many faces.
# The annotations are not resized: RetinaNet handles that for you.
cocodata = oij.openimages2coco(set1, catmid2name, images_dir,
desc="Open Image validation data, set 1.",
output_class_ids={'Human face': 1},
max_size=864, # Does not resize annotations!
min_ann_size=(2,2),
min_ratio=2.0)
oij.write_json_data(cocodata, output_json)
5. Convert training annotation to JSON
Run the same process from step 4 to produce the training data. For detailed instructions, see the data README. The final dataset contains over 161K images, with over 500K faces annotated.
6. Copy the training and validation images
You must also copy the images used for validation to a new directory so that they can be processed by RetinaNet.
import open_images.open_image_to_json as oij
oij.copy_images('/data/open_images/val_faces.json',
'/data/open_images/validation', '/data/open_images/val_faces')
images_dir = ['/data/open_images/train_0%i'%oo for oo in range(9)] # There are nine image directories.
oij.copy_images('/data/open_images/train_faces.json', images_dir,
'/data/open_images/train_faces')
Training the RetinaNet model
Now that the data is in the correct format, most of the hard work is done. Before installing RetinaNet, make minor changes by tuning hyperparameters to improve performance.
1. Clone RetinaNet from the NVIDIA GitHub repo
First, pull the RetinaNet code:
git clone https://github.com/NVIDIA/retinanet-examples.git
cd retinanet-examples
2. Tune hyperparameters
Adjust anchor box scales. Human faces are typically a lot smaller than objects in the COCO dataset, so reduce the size of the smallest anchor boxes by changing model.py to the following value:
self.scales = [2.0, 3.5, 6.0]
Change the optimizer in train.py to use the Adam optimizer instead of the default SGD, and increase the amount of L2 regularization.
from torch.optim import Adam
optimizer = Adam(model.parameters(), lr=lr, weight_decay=0.0004, amsgrad=True)
3. Install RetinaNet
Run pip install with local copies of the file modified in step 2.
pip install --no-cache-dir .
4. Train
Use the retinanet train command for training.
Note: This model trained in 8 hours 43 minutes on DGX-1. The following hyperparameters worked well on NVIDIA DGX-1, but you should adjust them for your system. Training times may vary depending on your model and the type of GPUs used.
retinanet train redaction.pth --backbone ResNet34FPN \
--fine-tune retinanet_rn34fpn.pth --classes 1 --lr 0.00003 \
--batch 80 --images /data/open_images/train_faces \
--annotations /data/open_images/train_faces.json \
--val-images /data/open_images/validation \
--val-annotations /data/open_images/val_faces.json --val-iters 3000 \
--resize 800 --max-size 880 --iters 60000 \
--milestones 30000 45000 | tee redaction.log
A description of some of the hyperparameters:
- The model is trained for 60,000 iterations (
--iters), with a batch size of 80 samples (--batch). - Images are resized so that the shorter side is 800 pixels (
--resize), however the longer side must never exceed 880 pixels (--max-size). - We are using an adjustable learning rate which starts at 0.00003 (–lr), and is then divided by 10 after 30,000 iterations, and then again after 45,000 iterations, specified by
--milestonesoptions. - This training uses a pre-trained RetinaNet model with ResNet34 backbone (
--fine-tune).
The following graph shows the training losses (focal and box) and the validation accuracy. We chose to train for 60K iterations, but you may get a good model after fewer iterations.
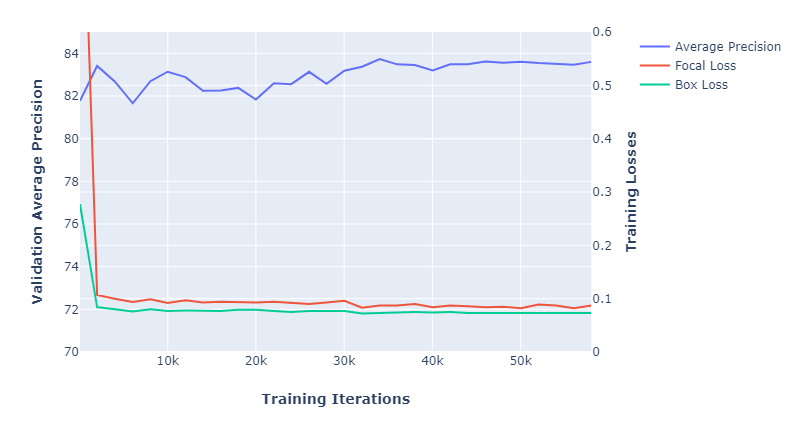
Figure 3: Training loss and validation accuracy
5. Evaluate
Use the retinanet infer command to evaluate the model:
retinanet infer redaction.pth --images /data/open_images/validation --annotations /data/open_images/val_faces.json
This gave a final average precision (measured at IOU=50%) of 83.6% on our validation set.
Export to ONNX
Now that the model is trained and evaluated, the final step is to export the model. After the model is exported, it can be used on an edge device for deployment. Export the model to the Open Neural Network Exchange (ONNX) standard, which can then be processed by any NVIDIA GPU device. ONNX format makes it easy to convert to TensorRT engine file for inferencing.
You can export the model using FP32, FP16, or INT8 precision. The default is FP16, which is used for this model. The input resolution of the model is 864×512 pixels.
retinanet export redaction.pth redaction.onnx --size 512 864 --batch 4
To export at a different precision, see the retinanet repo README, or run the help command.
retinanet export --help
Next steps
To continue with this tutorial, see Building a Real-time Redaction App Using NVIDIA DeepStream, Part 2: Deployment.
Get started with RetinaNet examples >>
Download NVIDIA DeepStream >>
Free online course on DeepStream SDK
If you are a student or a developer interested in learning more about intelligent video analytics and gaining hands-on experience using DeepStream, we have a free self-paced online Deep Learning Institute (DLI) course available.
Enroll in the free DLI course on DeepStream >>
References
- https://storage.googleapis.com/openimages/web/index.html
- https://arxiv.org/abs/1708.02002
- https://arxiv.org/abs/1612.03144
Chintan Shah
Product Manager, NVIDIA
James Skinner
Solutions Architect, NVIDIA
Jin Li
Data Scientist, Solutions Architect Group, NVIDIA