
This technical article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
Businesses are constantly overhauling their existing infrastructure and processes to be more efficient, safe, and usable for employees, customers, and the community. With the ongoing pandemic, it’s even more important to have advanced analytics apps and services in place to mitigate risk. For public safety and health, authorities are recommending the use of face masks and coverings to control the spread of COVID-19.
NVIDIA developed NVIDIA Clara Guardian, which is an application framework and partner ecosystem that simplifies the development and deployment of smart sensors with multimodal AI in healthcare facilities. Clara Guardian comes with a collection of healthcare-specific, pretrained models and reference applications that are powered by GPU-accelerated application frameworks, toolkits, and SDKs. You can use NVIDIA Transfer Learning Toolkit (TLT) to develop highly accurate, intelligent video analytics (IVA) models with zero coding and use the NVIDIA DeepStream SDK to deploy multi-platform scalable video analytics.
In this post, we show experiments using TLT to train a face mask detection model and then using the DeepStream SDK to perform efficient, real-time deployment of the trained model. Face mask detection systems are now increasingly important, especially in smart hospitals for effective patient care. They’re also important in stadiums, airports, warehouses, and other crowded spaces where foot traffic is heavy and safety regulations are critical to safeguarding everyone’s health.
This post only outlines the developer recipe. No trained model or datasets are provided by NVIDIA. You can access the recipe and scripts to build your own app using the NVIDIA-AI-IOT/face-mask-detection GitHub repo.
Video 1. AI-based, face mask detector demonstration using the Transfer Learning Toolkit and DeepStream SDK.
Overcoming challenges with building an AI-based workflow
For implementing real-time and accurate deep learning applications on embedded systems, you must effectively optimize models during AI training and inference. The goal here is to train an AI model that is not only accurate but lightweight and performant for real-time inference on the edge. Pruning the model helps reduce the overall size of the model which will result in higher performance. This must be done without losing accuracy as compared to the original model.
The next step in model optimization is weight quantization, transforming floating-point to integer. Training is typically done at FP32/16 precision but for inference you can run inference at INT8 precision. This is very important for edge devices where computing resources are limited. This is done either during training or post- training. TLT provides you with both: quantization-aware training (QAT) and post-training quantization (PTQ) options.
Finally to maximize inference throughput, you must efficiently process streaming video data by minimizing memory copies, using all the hardware acceleration, and using TensorRT for inference.
The NVIDIA Transfer Learning Toolkit (TLT) and NVIDIA DeepStream SDK abstract away complexity associated with building and deploying deep learning models. This end-to-end pipeline helps in reducing overall time to deploy real-time AI/DL applications. TLT and DeepStream are containerized so that you don’t need to install CUDA, cuDNN, Deep Learning frameworks (TensorFlow, Keras or PyTorch), or TensorRT for inference. In this post, we discuss how to use containers on your machine and provide commands on NVIDIA-AI-IOT/face-mask-detection GitHub open-source repo.
To use TLT and DeepStream; you do not necessarily have to know all the concepts in depth, such as transfer learning, pruning, quantization, and so on. These simple toolkits abstract away the complexities, allowing you to focus on your application.
TLT provides a variety of pretrained models, about 13 commonly used image classification models and six object detection models with all 13 classification models as a backbone. For more information about the available pretrained models, see here. You can use these models based on a trade-off between accuracy and complexity (inference FPS). For this experiment, you use DetectNet_v2 with the ResNet-18 backbone.
AI-based face mask detection
The developer recipe shows the high-level workflow of downloading the pretrained model and downloading and converting datasets to the KITTI format to use with TLT. The quantized TLT model is then deployed using DeepStream SDK to detect masked and no-mask faces.

Figure 1. Workflow for developing an AI-based face mask detector.
Transfer Learning Toolkit workflow
The TLT workflow involves downloading the pretrained model, converting the data to the KITTI format, and pruning the model.
Download the pretrained model
TLT provides pretrained models for image classification, instance segmentation, and object detection on NVIDIA NGC. TLT provides a simple and intuitive command line interface to download models of your choice. It also provides purpose-built pruned models such as PeopleNet, TrafficCamNet, DashCamNet, FaceDetect-IR, VehicleTypeNet, and VehicleMakeNet for popular use cases, such as counting people and identifying vehicles at toll booths and traffic intersections, and more.
Convert the dataset to the KITTI format
For object detection models, input images and labels must be in KITTI annotations format and all input images need to have same size (that is, multiple resolution is not allowed). In the GitHub repo referenced in this post, we provided KITTI format conversion scripts for four publicly available dataset sizes: FDDB, WiderFace, MaFA, and Kaggle Medical Mask Dataset. You can get these from the NVIDIA-AI-IOT/face-mask-detection GitHub repo.
Train and prune the model
After the input data is processed, you use a downloaded, pretrained model to perform transfer learning. Model pruning not only reduces model parameters, but also in some cases helps reduce overfitting. It gives better accuracy compared to unpruned models and improves inference performance. Model pruning can be considered as an important task for running large and complex object detection models on embedded platforms. For more information, see Pruning Models with NVIDIA Transfer Learning Toolkit.
Figure 2 shows the effect of pruning on the overall throughput of the face mask detection application.
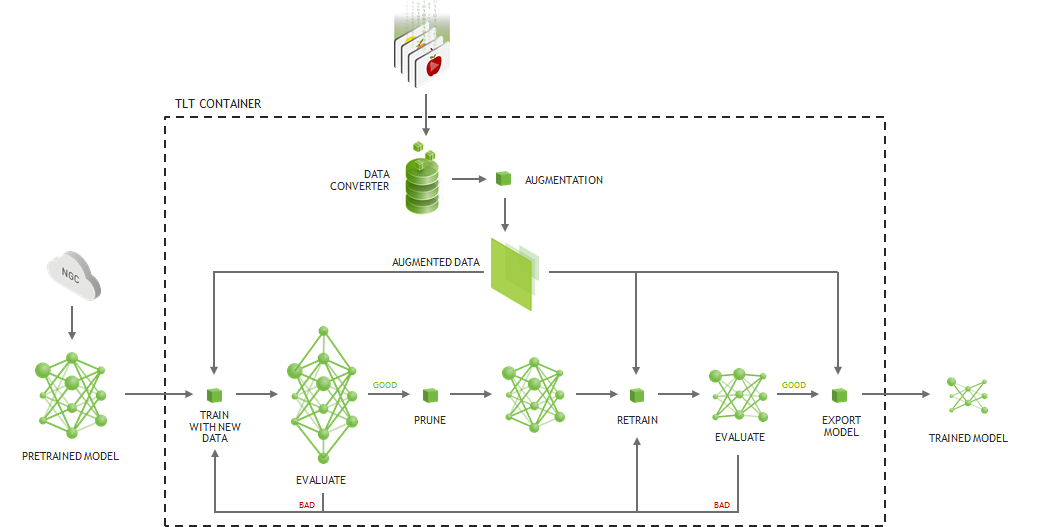
Figure 2. Recommended TLT workflow.
After you achieve satisfactory accuracy for the pruned model, it is ready for deployment. We suggest deployment in FP16 or INT8 format for the best performance. NVIDIA Jetson AGX Xavier and Jetson Xavier NX allow the use of INT8 precision for GPU as well as with the NVIDIA Deep Learning Accelerator (NVDLA). In the case of INT8 precision, tlt-export generates a calibration file that is used to reduce loss of information due to quantization error, that is, moving from FP32 to INT8.
We also provide a visualization function so that you can visualize the evaluated output and TensorRT deployment output on test images.
Real-time deployment using DeepStream
The DeepStream SDK allows you to build and deploy real-time video analytics pipelines for highest throughput. After you export the model from TLT to an encoded TLT model file (.etlt), you can convert the model to a TensorRT engine file using tlt-converter and deploy on the NVIDIA Jetson platform. Generated TensorRT engine can be used as an input to DeepStream SDK. Alternatively, you can also use the .etlt model directly with DeepStream.
In the GitHub repo, we provide configuration files to set up input for deepstream-app so that you can take advantage of the video analytics pipeline and TensorRT integration for inference. For a better understanding of updating configuration files according to camera input and video files stored on Jetson, we provide two different configuration files for deepstream-app.
Results and assumptions
Table 1 shows the inference performance with DeepStream SDK on Jetson Nano, Jetson Xavier NX, and Jetson AGX Xavier. All the results are with NVIDIA DetectNet_v2 object detection model with ResNet-18 model as backbone, and input image resolution of 960×544 (Width x Height).
For this developer recipe, we chose to show training accuracy performance on 27,000 images from the FDDB and WiderFace datasets for faces without masks and the MaFA and Kaggle Medical mask datasets for faces with masks. We also show performance on 4,000 images, using cherry-picked images from the WiderFace dataset for faces without masks and the entire FDDB and Kaggle Medical Mask datasets for faces with masks.
Our experiments showed that we could achieve better accuracy on faces without masks using a lower number of images; as the WiderFace dataset involves a variety of data points where a person is about 25 feet away from the camera and with various camera perspectives. We encourage you to do further experiments with such datasets and try to get better results.
| Dataset size | mAP (Mask/No-Mask) (%) |
| 27K | 78.98 (91.77, 66.19) |
| 4K | 86.12 (87.59, 84.65) |
Table 1. Training accuracy evaluations with respect to dataset usage, experiments were run with batch size=16.
Table 2 shows the effect of the TLT pruning and re-training methodology. You can see from the table that the accuracy of the detector decreases by less than 1%; however, the application FPS improves tremendously. The result in table 2 is generated using the model trained on 4K images from table 1. The pruning ratio is the ratio of the pruned model size to the original model size. In this experiment, we reduced the model size by 8x, which resulted in a more than 2x increase in performance.
| Pruned | mAP(%) |
Inference Evaluations on Nano GPU (FPS) |
Inference Evaluations on Xavier NX GPU DLA |
Inference Evaluations on AGX Xavier GPU DLA |
||
| No | 86.12 | 6.5 | 125.36 | 30.31 | 269.04 | 61.96 |
| Yes | 85.50 | 21.25 | 279 | 116.2 | 508.32 | 155.5 |
Table 2. Results for the end-to-end face mask detection application using the DeepStream SDK.
Some notes on reporting:
- Inference time on Jetson Nano is reported with FP16 precision, whereas Jetson AGX Xavier and Jetson Xavier NX is with INT8 precision.
- There are two deep learning accelerators (DLA) on Jetson AGX Xavier and Jetson Xavier NX. While running inference on one DLA, GPU and the other DLA are free, so you can use those hardware resources to run other applications.
- The inference time for DeepStream was measured while each stream was running at about 30 FPS (real-time). For example, in the second row, the pruned model on the Jetson Xavier NX GPU had nine input streams at 34.8 FPS each stream and DLA with three input streams at 38.6 FPS each stream.
Model limitations
- The model accuracy was tested on a live camera feed from 5 feet away. We have not evaluated model accuracy at 10 feet and 15 feet.
- The camera must be mounted between 4 to 7 feet away. An overlooking camera perspective has not been tested.
- The dataset largely consisted of faces with surgical masks, so the accuracy on other masks is a bit lower.
Next steps
This developer recipe is available now, so you can get started today. The following resources are in the NVIDIA-AI-IOT/face-mask-detection GitHub repo:
- TLT scripts:
- Dataset downloading links
- Dataset preprocessing script to convert it to KITTI format
- Jupyter notebook for easy experiments
- Specification files for configuring tlt-train, tlt-prune, tlt-evaluate
- DeepStream scripts:
- deepstream-app config files, for the face mask detection demo on a single stream camera and on stored video files
Amey Kulkarni
Developer Technology Engineer, NVIDIA
Amulya Vishwanath
Developer Marketing Lead, Deep Learning and Vision AI, NVIDIA
Chintan Shah
Product Manager, NVIDIA