This article was originally published at Hasty’s website. It is reprinted here with the permission of Hasty.
We cleaned up all 17.120 images of the PASCAL VOC 2012 dataset in a week using Hasty’s AI-powered QC feature. We found that 6.5% of the images in PASCAL had different errors (missing labels, class label errors, etc.). So, we fixed them in record time and improved our model’s performance by 13% mAP. In this blog post, we dive deeper into how we did that and what the results were.
Background
More often than not, poor model performance can be traced back to the insufficient quality of the training data. Even in 2022, with data being one of the most vital assets for modern companies, developers often struggle with its poor quality. In Hasty, we want to simplify and derisk vision AI solutions development by making it much faster and more efficient to clean up data.
We have developed an AI Consensus Scoring (AI CS) feature, a part of the Hasty ecosystem that makes manual consensus scoring a thing of the past. It integrates AI into the Quality Control process, making it faster, cheaper, and scaling in performance the more data you add.
Our previous blog post showed that AI Consensus Scoring makes the QC process 35x cheaper than today’s approaches. Today we want to go even further and share a practical example of what you can achieve by paying considerable attention to Quality Control. In this post, we will use AI CS to improve, update, and upgrade one of the most popular Object Detection benchmark datasets, PASCAL VOC 2012.
If you are not familiar with PASCAL, you should know it is a well-known academic dataset used for benchmarking models for vision AI tasks such as Object Detection and Semantic Segmentation. Even though PASCAL is over a decade old, it’s still frequently used. It was used in 160 papers in 4 recent years. You can also check the results academics achieved on various versions of PASCAL.
The general task seems challenging. The dataset did not change over the past ten years, and research teams worldwide actively use it “AS-IS” for their studies. However, the dataset was annotated a long time ago when the algorithms were not as accurate as today, and the annotation requirements were not as strict. Therefore, the annotators missed some labels that should be in a modern dataset of PASCAL’s caliber.

There is no label for the horse despite the horse being in the foreground and visible. These quality issues are common in PASCAL.
Using a manual workforce to get through the dataset would be costly and incredibly time-consuming, but using AI to do the quality control and improve the quality of PASCAL, we wanted to test if having better data results in better models. To perform this test, we set an experiment that consisted of the following steps:
- Cleaning PASCAL VOC 2012 using AI Consensus Scoring on the Hasty platform;
- Training a custom model on the original PASCAL training set using the Faster R-CNN architecture;
- Preparing a custom model on the cleaned-up PASCAL training set using the same Faster R-CNN architecture and parameters;
- Drawing our conclusions.
Cleaning PASCAL VOC 2012
Our top priority was to improve the dataset. We got it from Kaggle, uploaded it to the Hasty platform, imported the annotations, and scheduled two AI CS runs. For those unfamiliar with our AI Consensus Scoring capabilities, the feature supports Class, Object Detection, and Instance Segmentation reviews, so it checks annotations’ class labels, bounding boxes, polygons, and masks. Doing the review, AI CS looks for extra or missing labels, artifacts, annotations with the wrong class, and bounding boxes or instances with imprecise shapes.
PASCAL VOC 2012 consists of 17.120 images and ~37.700 labels of 20 different classes. We have run the Object Detection and Class reviews for our task that highlighted 28.900 (OD) and 1.320 (Class) potential errors.

With our AI consensus scoring, you can use AI to find potential issues. Then, you can focus on fixing errors instead of spending days (or weeks) finding them first.
Our goal was to review these potential errors and resolve them while trying to be more accurate than the original annotators. In simple words, it means that:
- We tried to fix all possible issues on every image where our AI CS predicted at least one potential error;
- We did not go deep into the background and did not aim to annotate every object possible. If the annotation missed an object and was in the foreground and/or visible by a human eye without zoom, we labeled it;
- We tried to make our bounding boxes pixel-perfect;
- We also annotated partials (unlabeled parts of the dataset’s class object) because the original dataset features them.
With the cleaning strategy outlined and the goal clear, we embarked upon the fascinating journey of improving PASCAL.
- We started by reviewing the Class review run that checked existing annotations’ class labels, trying to find potential mistakes. More than 60% of AI CS suggestions were of great use as they helped identify the not immediately apparent issues of the original dataset. As an example, the annotators used the sofa and chair classes interchangeably. We fixed that by relabelling more than 500 labels across the dataset;

An example of the original annotations. There are two sofas and two armchairs. One of the two armchairs is labeled a sofa, whereas the other is annotated as a chair. Something weird is going on – it needs to be fixed.

This is how we fixed the issue. The armchair is a chair, and the sofa is a sofa.
- When analyzing OD and Class reviews, we found out that PASCAL’s most prominent issue is not misclassified annotations, weird bounding boxes, or extra labels. The most significant problem it has is the absence of many potential annotations. It is hard to estimate the exact number, but we feel like the there are thousands of unlabeled objects that should have been labeled;
- The OD review went through the dataset, looking for extra or missing labels and bounding boxes of the wrong shape. Not all of the absent annotations were highlighted by AI CS, but we have tried to do our best to improve all the pictures that had at least one missing label predicted by AI CS. As a result, the OD review helped us find 6.600 missing annotations across 1.140 images;
An example of how we reviewed images and resolved errors
- We spent roughly 80 person-hours reviewing all the suggestions and cleaning up the dataset. It is a fantastic result. Many R&D and Data Science teams that use the conventional approach of manual QC would have killed for an opportunity to review 17.120 images in that timeframe.
Excellent, we did the most challenging task with some significant improvement stats, so it was time to chill and enjoy training some neural networks to prove that you can get better models with better data.
The custom model trained on the original PASCAL
As mentioned above, we decided to set up two experiments – train two models – one on the initial PASCAL and the other on the cleaned version of PASCAL. To do the NNs training, we used another Hasty feature known as Model Playground, a no-code solution allowing you to build AI models in a simplified UI while keeping control over architecture and every crucial NN parameter.
Before jumping to training, we looked out for articles featuring PASCAL to understand better the mean Average Precision metric value achievable on this dataset. We stopped our search on the Faster R-CNN article as we have Faster R-CNN implemented in Model Playground. In the paper, with the help of the Faster R-CNN architecture, researchers achieved ~45-55 COCO mAP (IoU in the range of 0.5 to 1.0 with a step size of 0.1) on PASCAL VOC 2012. We will not compete with them or draw a direct comparison between the models. We will keep in mind 45-55 COCO mAP as a potential metric value we want to achieve with our solution. We used the PASCAL VOC 2012 train set; for validation, we used the PASCAL VOC 2012 validation set.
We went through several iterations of the model throughout the work, trying to find the best hyperparameters for the task. In the end, we opted for:
- Faster R-CNN architecture with ResNet101 FPN as a backbone;
- R101-FPN COCO weights were used for model initialization;
- Blur, Horizontal Flip, Random Crop, Rotate, and Color Jitter as augmentations;
- AdamW was the solver, and ReduceLROnPlateau was the scheduler;
- Just like in every other OD task, a combination of losses was used (RPN Bounding Box loss, RPN Classification loss, final Bounding Box regression loss, and final Classification loss);
- As a metric, we had COCO mAP. Fortunately, it is directly implemented in Model Playground.
It took the model about a day and a half to train. Assuming the depth of the architecture, the number of images the network was processing, the number of scheduled training iterations (10.000), and the fact that COCO mAP was calculated every 50 iterations across 5.000 pictures, it did not take too long. Here are the results the model achieved.

AverageLoss graph across the training iterations for the original model.

COCO mAP graph across the validation iterations for the original model.
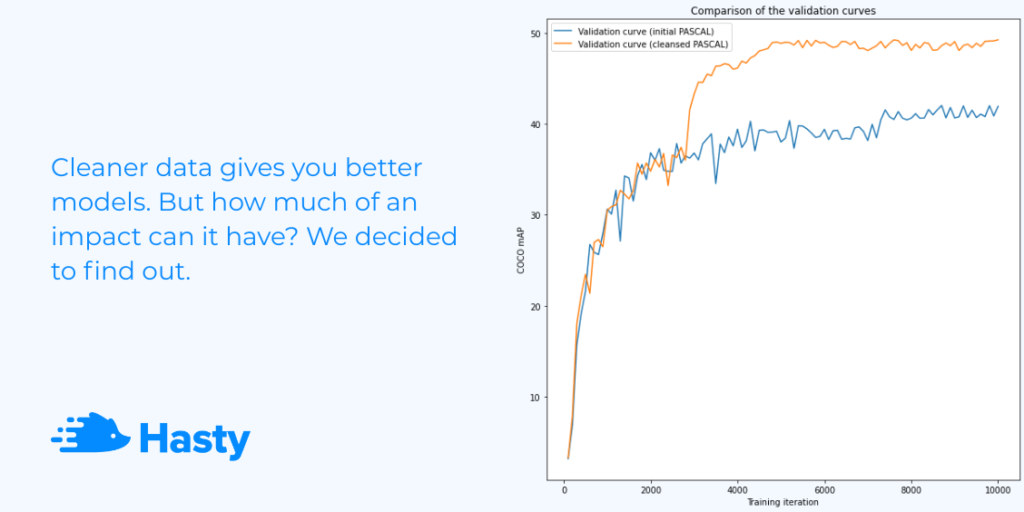
The final COCO mAP result we achieved with this architecture was 0.42 mAP on validation. So the model trained on the original PASCAL does not perform as well as the state-of-the-art architectures. Still, it is not a bad result given the low amount of time and effort we spent building the model (we went through 3 iterations with only one person-hour spent on each). In any case, such a value makes our experiment more interesting. Let’s see if we can get to the desired metric value by improving the data without tuning the model’s parameters.
The custom model trained on the updated PASCAL
We took the same images for training and validation to train the following model as the baseline. The only difference was that the data in the split was better (more labels added and some labels fixed).
Unfortunately, the original dataset does not feature each of the 17.120 images in its train/test split. Some pictures are left out. So, despite adding 6.600 labels to the original dataset, in the train/test split, we got only ~ 3.000 new labels and ~190 fixed ones.
Nevertheless, we proceeded and used the improved train/test split of the PASCAL VOC 2012 to train and validate the model.

AverageLoss graph across the training iterations for the updated model.

COCO mAP graph across the validation iterations for the updated model.

Head to head comparison
As you can see, the new model performs better than the original one. It achieved 0.49 COCO mAP on validation compared to the 0.42 value of the previous model. At this point, it is evident that our experiment was successful.
Fantastic, the result is within 45-55 COCO mAP, which means the updated model works better than the original one and delivers the desired metric value. It is time to draw some conclusions and discuss what we have just witnessed.
Conclusions
We have shown you the concept of data-centric AI development in the post. The idea is to improve the data to get a better model, precisely what we achieved. Nowadays, when you start hitting that upper roof of model performance, it might be challenging and expensive to improve results beyond 1-2% on your key metric by tweaking the model. However, it would be best if you never forgot that your success does not rest only on your model’s shoulders. There are two crucial components – the algorithm and the data.
An AI solution is as good as the data it was trained on. In Hasty, we take this to heart, believe that it is the core reason for success, and aim to assist by giving you all the necessary capabilities to produce better data. Sure, you should not give up on improving your model, but it might be worth it to take a step back and see if your data is any good.
In this post, we did not try to beat any SOTA or get results better than the previous researchers. We wanted to show you that some time spent improving your data benefits your model’s performance. And we hope that our case, which gave us the 13% COCO mAP increase by adding 3.000 missing labels, was convincing enough and encourages you to find and fix some issues in your own data.
The results you can get by cleaning your data and adding more labels to images are hard to predict. They depend greatly on your task, NN parameters, and many other factors. Even in our case, we cannot be sure that 3.000 more labels will give us another 13% mAP increase (probably not ). Still, the results speak for themselves. Even though it is sometimes hard to determine the upper roof for improving model metrics through having better data, you should give it a shot if you get stuck with an unsatisfactory metric value. Data Science is not only about NN parameters tuning. As the name suggests – it is also about the data, and you should keep that in mind.
How Hasty can help (aka a shameless plug)
At Hasty, we’re experts in building vision AI in an economically viable way. With our unique methodology enabled by our platform, we helped 100s of companies to:
- deploy vision AI solutions in weeks,
- stay on budget,
- and move the needle for their business.
If you are looking to replicate such fascinating results as you’ve seen in this post. Please, book a demo.
If you are interested in the clean data asset. Using the following links, you can download the clean version of PASCAL VOC 2012:
For the raw data, you can go to Kaggle directly.
Vladimir Lyashenko
Content Manager, Hasty