This blog post was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks.
In the field of artificial intelligence, vector databases are an emerging database technology that is transforming how we represent and analyze data by using vectors — multi-dimensional numerical arrays — to capture the semantic relationships between data points.
In this article, we begin by defining what is a vector database. We compare some of the top companies offering vector database solutions. Then, we highlight how vector databases differ from relational, NoSQL and graph databases. We illustrate with an example how vector databases work in action. Finally, we discuss what might be on the horizon for this technology.
What is a Vector DB
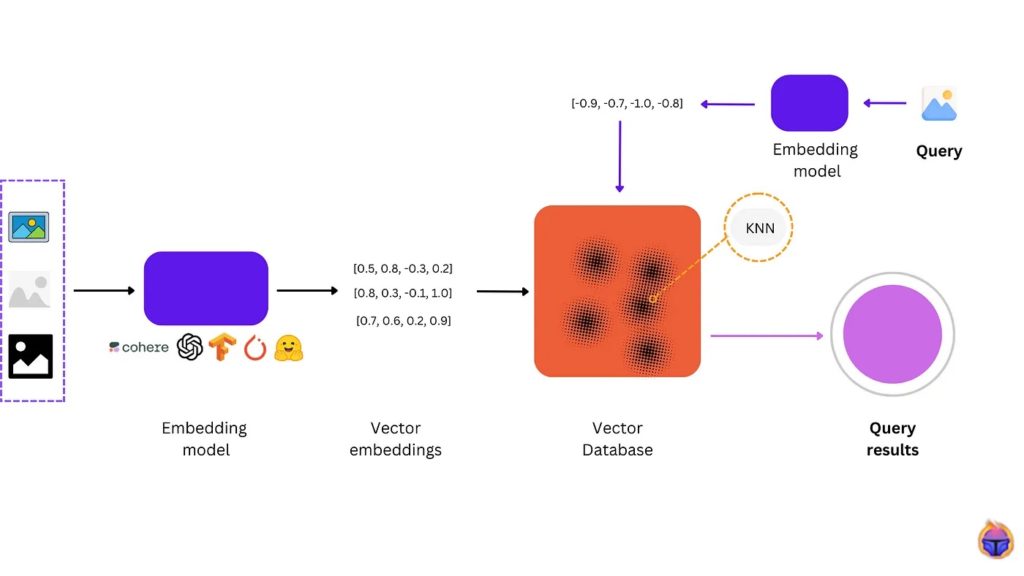
In essence, a vector database is a special-purpose database to store and manage embedding vectors. It’s optimized for fast similarity searching and relationship detection in applications such as image search, recommender systems, text understanding and many more.
Machine learning has enabled the transformation of unstructured data into vector representations that capture meaningful relationships within the data. These vector representations, called embeddings, are used for data analysis and power many machine learning applications.
For instance, [10] highlights how recommender systems commonly use vector embedding techniques like item2vec [1], word2vec [2], doc2vec [3] and graph2vec [4] to convert items into vectors of numeric features. Recommendations are then generated by identifying the items with the most similar vector representations. Images [5] and natural language also have inherent vector-based representations due to their numeric pixel and word components.
Vector databases originate from vector similarity search, where early systems [6, 7] were capable of similarity queries but lacked performance at scale with dynamic vector data. The first solutions for similarity search were either algorithms (i.e. libraries) [8] or systems [9]. The former (e.g. FAISS from Facebook) handle large volumes of data poorly, assuming all data and indexes fit into main memory. The latter (e.g. Alibaba AnalyticDB-V) are not a good fit for vector data and do not really focus on vectors as first-class data types.
Given these issues, purpose-built vector database solutions emerged, such as Milvus [10]. Milvus is a vector data management system built on top of FAISS that overcomes previous solutions’ shortcomings. It is designed specifically for large-scale vector data and treats vectors as a native data type.
Unlike a traditional relational database (i.e. MySQL), a vector database represents information as vectors — geometric objects that encode the relationship between data points.
Microsoft defines a Vector DB as follows:
A vector database is a type of database that stores data as high-dimensional vectors, which are mathematical representations of features or attributes. Each vector has a certain number of dimensions, which can range from tens to thousands, depending on the complexity and granularity of the data.
Why are relational databases not enough? Relational databases are ill-suited for modern machine learning applications that require fast, complex pattern analysis across large datasets. While relational databases excel at table-based storage and querying, their tabular data model cannot capture the semantic relationships between data points required for ML.
To have a complete picture of a vector database, it’s helpful to define what is a vector embedding and a vector model.
Vector embedding
Vector embeddings are the representations of data stored and analyzed in vector databases. These vectors place semantically similar items close together in space, and dissimilar items far apart.
These (vector) embeddings can be produced for any kind of information — words, phrases, sentences, images, nodes in a network, etc. Once you have vector embeddings for your data, algorithms can detect patterns, group similar items, find logical relationships, and make predictions.

Vector embedding example using Star Wars characters
The previous figure shows an embedding representation of Star Wars characters, learned from analyzing patterns in dozens of Star Wars books. This embedding space could be used as follows:
- Cluster characters into groups like “Jedi”, “Sith”, “ Droids” etc. based on vector proximity.
- For a character like Yoda, the nearest neighbors in the vector space may be other Jedi masters (i.e. Luke), indicating an affiliation we could infer even with no label for the given cluster.
- Find edge-cases, e.g. Anakin Skywalker can be on the intersection of Jedi & Sith -even though we know his final form is more akin to Sith & Droid when he is fully led into to the dark side.
Different embeddings will compute different underlying similarity measures, see the following figure. For example, CLIP can compute the high-level semantic similarity of concepts like “Jedi” and “Sith”, whereas other embeddings, such as PCA, may compute lower-level similarities, such as shapes or colours.

A different vector embedding space of the same Star Wars characters
Embedding model
Vector databases use embedding models as a key component for translating data into vector formats optimized for similarity search and pattern analysis. The embedding models produce the vector representations that vector databases are built to store, query and analyze.
Some ways embedding models work with vector databases include:
- Vector databases rely on embedding models to encode data such as words, images, knowledge graphs, etc. into numeric vector representations.
- Because embedding models map semantically related items close together in vector space, vector databases can perform rapid vector similarity searches.
- Embedding models map sparse data into lower-dimensional dense vectors, which vector databases are optimized to work with.
Vector embeddings, embedding models and vector databases work together to provide an end-to-end solution for generating, storing, and using vector data to power AI applications.
Top Vector DB technology providers

Top Vector database providers available in the market
Weaviate is an open-source vector database. It allows you to store data objects and vector embeddings from your favorite ML-models, and scale seamlessly into billions of data objects.
Elastic is a distributed, free and open search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured.
Milvus is a vector database created in 2019 with a singular goal: store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models.
Qdrant is a vector database & vector similarity search engine. It deploys as an API service providing search for the nearest high-dimensional vectors.
Pinecone is a vector database that makes it easy to build high-performance vector search applications. Developer-friendly, fully managed, and easily scalable without infrastructure hassles.
Chroma is a database for building AI applications with embeddings. It comes with everything you need to get started built in, and runs on your machine.
How Vector DBs compare to other kinds of DBs
Vector databases excel in its particular niche: handling embedding vectors at scale. The following table shows some of the differences between Vector DBs and other types of databases.

Comparing Vector databases with other kinds of databases
Bear in mind that while this table provides a general overview, there can be specific databases within each category that have unique features and characteristics.
A practical showcase on Vector DB
At Tenyks we rely on vector databases to store millions of embeddings entries in our system. As we help companies in identifying edge cases and outliers, we depend on vector embeddings to represent their data for these use cases.
Vector databases are a perfect complement to state-of-the-art models like CLIP that produce rich, information-dense vector embeddings. These embeddings frequently have hundreds of dimensions to capture complex relationships, but vector databases can search and analyze them with ease.
The Tenyks platform performs lightning-fast semantic searches across enormous volumes of vector data. This powers capabilities such as rapid embedding search for image/text similarity.
Here’s (video download link) an example of a use case of vector databases in action. Using the BDD dataset, a driving dataset, we are interested in finding images of white cars. The snippet shows how the Tenyks platform allows you to find similar images given certain input in the form of text. In this case, after entering the text: “white car” on the search input bar, our similarity feature outputs images from this dataset that contain white cars.
Future outlook
Vector databases are likely to become commodities as demand grows for managing machine learning vector data at scale. They provide the performance, scale, and flexibility that AI applications require across industries.
Unlike other databases, vector databases were created specifically for vector embeddings and neural networks applications. They introduce a vector-native data model and query language providing functionality beyond SQL or graphs. As machine learning enriches use-cases that understand the world through vectors, vector databases deliver the data solution to gain insights from them.
Vector databases exhibit characteristics of both commodities and novel technologies. They are becoming commonplace for enterprises developing AI but represent a new database with a vector-first architecture no other technology provides.
References
- Item2Vec: Neural Item Embedding for Collaborative Filtering
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Sentences and Documents
- graph2vec: Learning Distributed Representations of Graphs
- Efficient Indexing of Billion-Scale datasets of deep descriptors
- SPTAG: A library for fast approximate nearest neighbor search
- Db2 event store: a purpose-built IoT database engine
- Billion-scale similarity search with GPUs
- AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data
- Milvus: A Purpose-Built Vector Data Management System
Authors: Jose Gabriel Islas Montero, Dmitry Kazhdan