
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica.
The attention mechanism made big changes in deep learning.
Thanks to this, models can achieve better results. This mechanism was also the inspiration for perceivers and also transformer neural networks . And transformers led to the development of models such as Bidirectional Encoder Representations from Transformers ( BERT) and Generative Pre-trained Transformer (GPT), which are used in Natural Language Processing (NLP).
Attention mechanism was initially used in machine translations. There are two mechanisms of attention that can be found in the TensorFlow framework, which are implemented as Layer Attention (a.k.a. Luong-style attention) and Additive Attention (a.k.a. Bahdanau-style attention). In this article, I’m going to focus on explaining the two different attention mechanisms.
Bahdanau introduced an attention mechanism for improvement in machine translation from English to French. The whole mechanism is based on recurrent neural network’s auto-encoders. At the beginning, hidden states are produced for inputs from an encoder, by a function that takes into account previous hidden states, previous input and contextual vectors for each word (which came from input to the model).
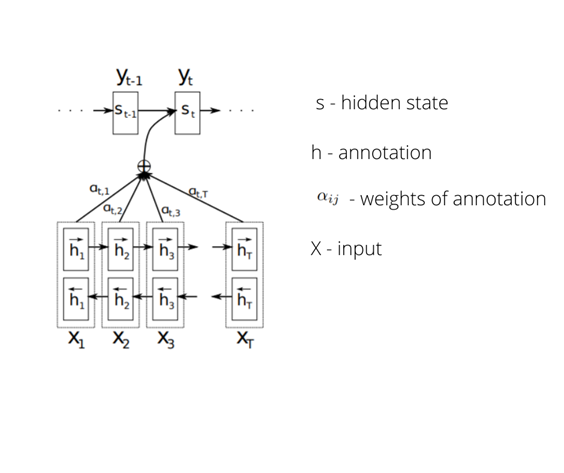
Illustration of attention mechanism from Bahdanau’s paper https://arxiv.org/pdf/1409.0473.pdf
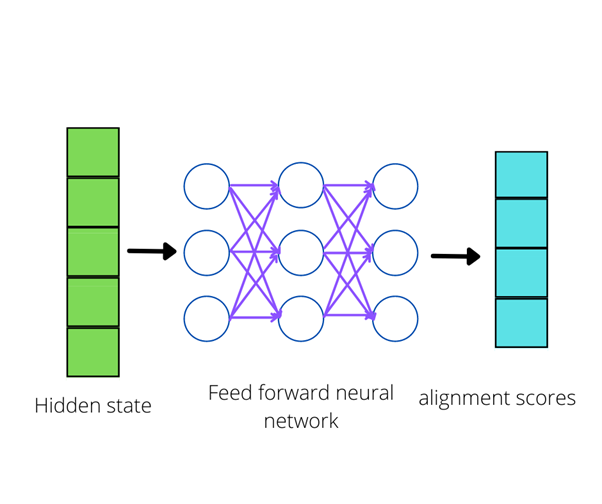
The next step is creating an alignment model, which scores how well the match is between input around position j and output around position i. The score is based on the hidden state and the j annotation unit of the input sentence. The alignment model is a feedforward neutral network which is jointly trained with all the other components of the system. After getting alignment scores, the softmax function is calculated.
Next, the context vector is calculated from the weighted sum of the annotations (encoder outputs). If the alignment of objects is close to 1, it means that the object has a high influence on the decoder output. Finally, the context vector is concatenated to the output and fed to the decoder model.
Luong’s attention mechanism differs in where the attention is focused and how the alignment score is calculated. With this method, you can use the concatenation of the forward and backward source hidden states in the bi-directional encoder and target hidden states in the decoder. There are also three ways of measuring the alignment score:
The first one involves the simple multiplication of hidden states in the encoder with hidden states in decoder. The second one involves multiplication as in the first version, but also includes weights. The last method is slightly similar to the way that alignment scores are calculated using Bahdanau’s attention mechanism, but the decoder hidden state is added to the encoder hidden states.

Conclusion
Attention mechanisms created a big revolution, especially in Natural Language Processing, which has allowed us to build better models, like BERT, for embedding words or phrases. This mechanism is also used in computer vision, which will be discussed in the next part of this article. This mechanism helps the model to “remember” all the inputted factors and to focus on specific parts of inputting e.g. concentrating on words when formulating a response or decision.
Joanna Piwko
Data Scientist, Digica