This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica.
Nowadays, no one needs to be convinced of the power and usefulness of deep neural networks. AI solutions based on neural networks have revolutionised almost every area of technology, business, medicine, science and military applications. After the breakthrough win of Geoffrey Hinton’s group in the ImageNet competition in 2012, neural networks have become the most popular machine learning algorithm. Since then, 21st century technology has come to increasingly rely on AI applications. We encounter AI solutions in almost every step of our daily lives – in cutting-age technologies, entertainment systems, business solutions, protective systems, the medical domain and many more areas. In many of these areas, AI solutions work in a way which is self-sufficient and under only little or no human supervision.
“With great power comes great fragility”
The truth behind the above quote has been known to mankind for centuries, and the AI field is no exception. We should remember that, when placing trust in any technology, we have to be aware of its weaknesses and that there will always be someone willing to use (or abuse) those weaknesses to their own advantage. What are the weaknesses of deep neural networks (DNNs). Probably one of the greatest weaknesses of DNNs is how easy it is to fool those networks and, by fooling neural networks, I do not mean making the model misbehave as depicted in the meme below. In today’s blog article, I would like to focus on the problem of deliberately and consciously deceiving neural networks and the dangers of that happening.
There are many well-known methods of fooling a neural network, such as the fast gradient sign method (https://arxiv.org/pdf/1412.6572), the adversarial patch method (https://arxiv.org/pdf/1712.09665), the single-pixel attack method (https://arxiv.org/abs/1710.08864) and creating 3D models by adding adversarial perturbations to them (https://arxiv.org/abs/1707.07397). In today’s article, I will only cover the gradient sign method and the adversarial patches methods. Finally, I will discuss the dangers resulting from deceiving neural networks.
Intriguing properties of neural networks
In 2014, Szegedy et al. presented in their article (https://arxiv.org/pdf/1312.6199) the interesting discovery that machine learning models, including state-of-the-art convolutional neural networks, can be easily deceived. Fooling a neural network is done by using so-called adversarial examples, which are artificially crafted, subtle perturbations added to the original image. To cut a long story short, the researchers demonstrated that, disturbingly, neural networks often misclassified examples taken from a distribution of trained data to which adversarial examples had been added. Since this discovery, numerous studies have been carried out with the aim of misleading machine learning models, and trying to explain the resulting behaviour of those models.
Goodfellow et al. conducted one of the first studies to explain the above phenomenon, and you can read the study at https://arxiv.org/pdf/1412.6572. In that study, the researchers stated that the primary cause of neural networks being vulnerable to adversarial perturbation is their linear nature. In the above article, based on that hypothesis, they proposed the fast gradient sign method of generating successful adversarial examples. In this method, you take the input image and use the gradients of the loss function with respect to the input image to create a new image that maximises the existing loss. In this way, there is an image generated with a change that is almost imperceptible to the human visual system, but at the same time, due to the change, the neural network can perceive a significant difference.

[I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and Harnessing Adversarial Examples”, 2014]
The illustration above depicts not only how easily neural networks can be fooled, but also the difficulty of detecting changes made to the classified image. The authors of the article touched on the topic extensively, and also provided a solution to the problem of adversarial examples, that is, by using adversarial training and specifying when adversarial perturbation is effective, and when this is not effective.
How to become invisible to a neural network?
The next method of deceiving neural networks was discovered by Brown and his team, and described in their article on Adversarial Patch (https://arxiv.org/pdf/1712.09665.pdf) The authors of the paper created a method that, unlike the fast gradient sign method, does not attempt to subtly transform a classified image, but instead generates an image-independent patch that is extremely salient to a neural network. Interestingly, this method causes the classifier to output the target class regardless of the scene. By placing such an adversarial path in any classified scene, and without any prior knowledge of the scene, we can fool the neural network into predicting the class encoded in the patch.
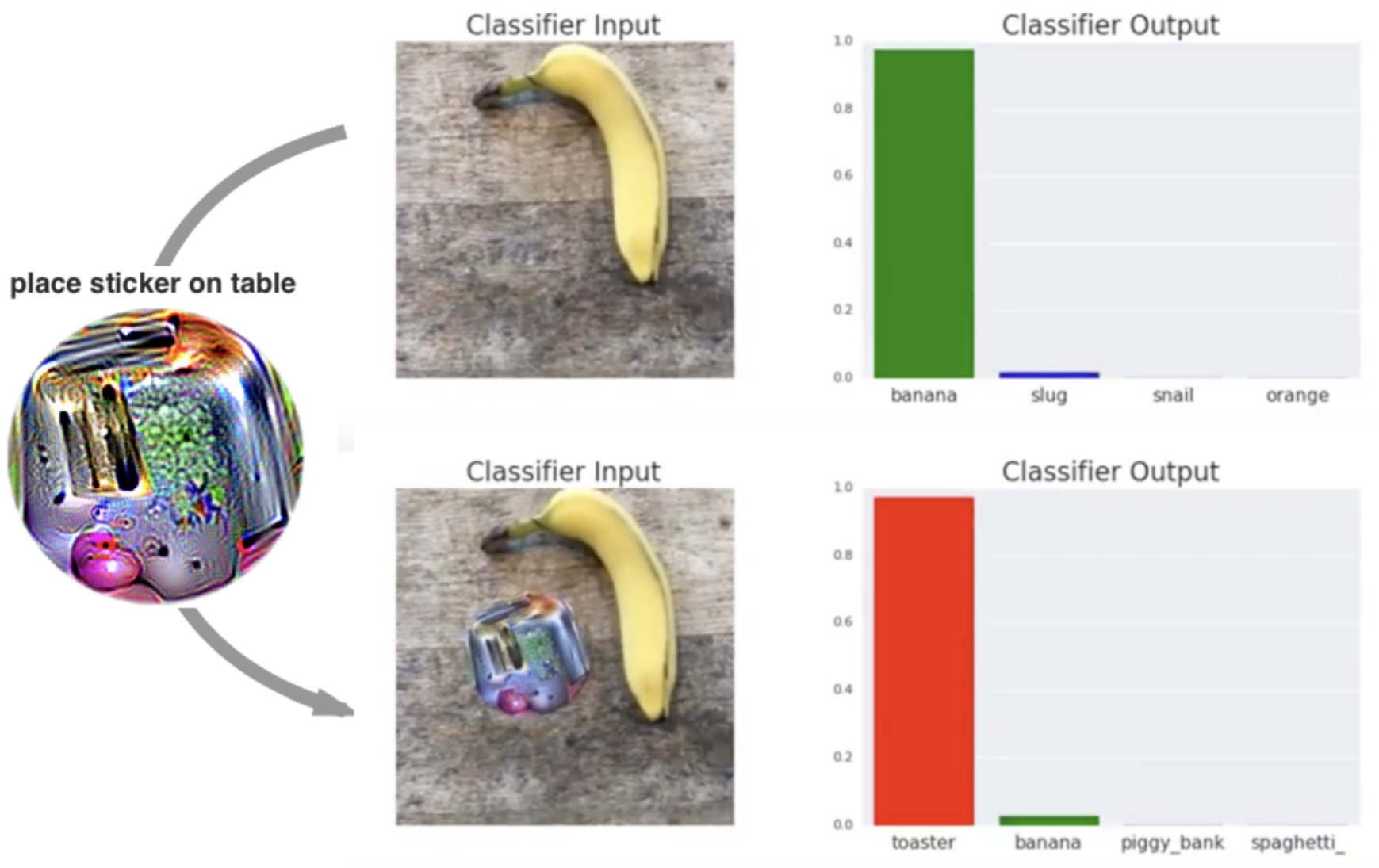
[Tom B. Brown, Dandelion Mané, Aurko Roy, Martín Abadi, Justin Gilmer, “Adversarial Patch”, 2017]
The above figure comes from a video (https://www.youtube.com/watch?v=i1sp4X57TL4), which was made by the authors of the article. The video shows that, by introducing an adversarial patch which represents a toaster class into the scene, we can, with almost 100% confidence, fool the neural network model into predicting incorrectly the toaster class.
Now imagine if we were to create an adversarial patch encoding the “Brad Pit” class in the shape of a pair of glasses, then put the glasses on our face, and that this would fool the face recognition system. Well, someone has already described that method here: https://dl.acm.org/doi/pdf/10.1145/2976749.2978392. Thanks to this method, we can be “invisible” to any face detection system. As scary as it might sound, the authors of the article proposed a solution to this problem that involves augmenting the detected adversarial patch with the silence map method in such a way that the patch loses its power, as can be seen in the figure below.
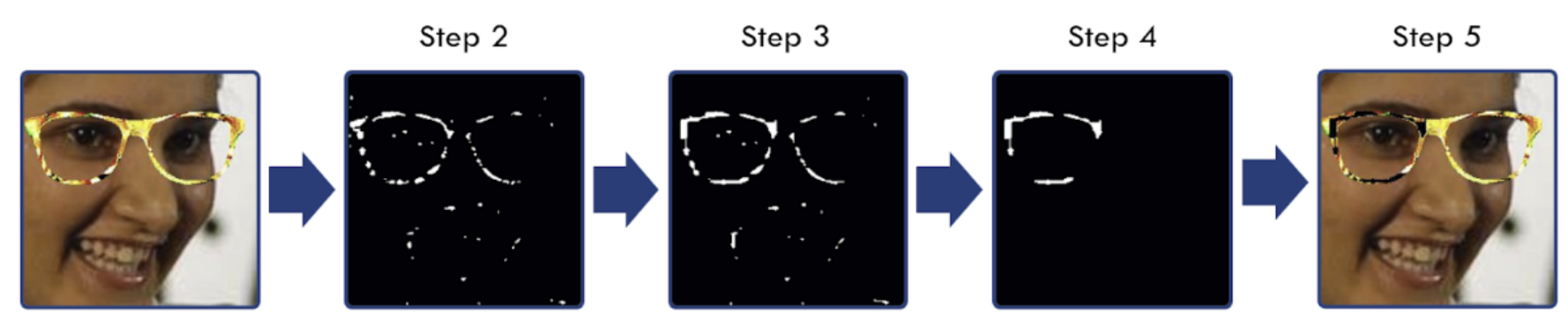
[Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, Michael K. Reiter, “Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition”, 2016]
Danger of adversarial attacks
Firstly, let us consider whether people also can be fooled by adversarial examples? Take a look at the picture below. In your opinion, are those lines parallel?

This is an adversarial example. In this case, we see things which we should not see in the images which are looking at. Unfortunately, our human visual system can also be fooled by particular examples, although it is clear that humans are less susceptible to the adverse effects of adversarial examples that can deceive neural networks.
By now you are probably aware that these methods clearly put many existing systems at risk of functioning incorrectly. Yes, maybe making the classifier predict a toaster class instead of a banana class is not a scary example, but let us consider something more serious. One of the most exciting artificial intelligence solutions in edge-technology is autonomous vehicles. The first autonomous taxis are already operating in some cities. Let’s imagine the situation in which some kind of adversarial attack on such a vehicle then results in fooling the neural network into incorrectly recognising a sign as showing a speed limit of 100 km/h instead of correctly recognizing the sign as a STOP sign.
One article (https://arxiv.org/pdf/1707.08945.pdf) presents and discusses such examples from the physical world. For example, we can regard road-sign graffiti as a factor which may lead to fooling neural networks, as shown in the figure below. The authors of the article proved that a neural network model can be fooled by both adversarial perturbations and road-sign graffiti.

[Eykholt, Kevin & Evtimov, Ivan & Fernandes, Earlence & Li, Bo & Rahmati, Amir & Xiao, Chaowei & Prakash, Atul & Kohno, Tadayoshi & Song, Dawn, “Robust Physical-World Attacks on Deep Learning Visual Classification”, 2018]
Of course, that doesn’t mean that all neural networks are doomed to failure. It should also be emphasised that, in order to carry out an attack using adversarial examples, the person carrying out an attack would have to have access to the architecture of the model and its trained weights. Although adversarial patches are not bound to the given scene and model architecture, such patches are easily recognised by our visual system, and there are solutions to defend against adversarial patches, for example, as described in: https://arxiv.org/pdf/2005.10884.pdf.
Conclusions
The concept of deep neural networks has revolutionised many fields of our daily life and is undoubtedly very powerful. Nevertheless, this concept is not perfect and has some weaknesses. In today’s blog article, I have shown how easy it can be to deceive neural networks, which means that, when developing technology, we must carefully consider a given technology’s strengths and weaknesses. Fortunately, the research studies which I have mentioned above demonstrate ways of recognizing and preventing potential blind spots in neural networks.
Mateusz Papierz
Data Scientist/Machine Learning Engineer, Digica