This blog post was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks.
Use embeddings with vector databases to perform multi-modal search on images.
Embeddings are a powerful way to represent and capture the semantic meaning and relationships between data points in a vector space. While word embeddings in NLP have become very popular, researchers have developed embedding techniques for images, audio, and other modalities.
In this article, we will explore how we can leverage image embeddings to enable multi-modal search over image datasets. This kind of search takes advantage of a vector database (DB), a special kind of database optimized for fast retrieval over high-dimensional embedding vectors. By indexing image embeddings in a vector database, we can enable semantic search over images — using text queries and image queries.
Lastly, we will showcase how the Tenyks platform employs this approach to enable image search, given a query based on text, images, or cropped-out objects.
Foundations
We begin by defining three of the main building blocks to understand multi-modal search:
Embeddings
Embeddings encode a single data modality, like words, images, audio, etc into a vector space. For example, word embeddings encode words into a semantic vector space. Image embeddings encode images into a visual vector space. These embeddings represent the meaning and relationships between a single type of data.
Multi-modal embeddings
Multi-modal embeddings encode and relate multiple different data modalities into a shared embedding space. As a result, we can represent high-level, semantic relationships and connections across modalities.
The concept of embeddings for a single data type is not novel; clustering CNN image embeddings to find visually similar images has been used for years. New approaches that leverage massive internet data have enabled a new frontier: aligning images and text in a shared vector space.
Powerful models trained on huge datasets have learned a common semantic meaning across modalities (see Figure 1). Images and captions, objects and attributes, even videos and transcripts can now be represented using the same high-level features. Searching with a photo to find related products or news stories is the exciting potential of multi-modal embeddings.

Figure 1. Segment Anything [1] leverages multi-modal embeddings
The real innovation is converting between data types within one model. A system skilled with both pictures and words can translate one into the other, use them together in a job, even create new data types by merging current ones in vector space.

Table 1. Comparing models capable of generating multi-modal embeddings
CLIP [2] is a model developed by OpenAI that can learn joint representations of images and their associated textual descriptions. By training on large-scale datasets containing images and their corresponding captions, CLIP learns to embed images and texts into a shared latent space. Table 1 shows CLIP’s main characteristics next to other similar models.
If interested, Hugging Face has an available implementation of these models: CLIP, VisualBert, and LXMERT.
VectorDBs
A vector database is a special-purpose database to store and manage embeddings. It’s optimized for similarity searching in applications such as image search, recommender systems, and many more.
Dive deeper into what a Vector DB is in our article on that topic.
Search pipeline
Multi-modal embeddings enable natural language search of non-text data. Without manual annotation, a system can understand concepts and semantic relationships across modalities. For instance, querying an image dataset for “taxis” will retrieve only taxi photos, allowing rapid model analysis for that category without extra work.
Why multi-modal search for model debugging
This approach to search powers essential capabilities like model debugging, performance evaluation on specific subsets, and model interpretability. Searching visual data with text illuminates how the model comprehends language and images. The system response suggests captions, labels or attributes it associates with different objects, scenes or attributes, revealing potential model biases or blind spots.
Most model issues emerge at the frontier— for niche cases, minorities, edge scenarios. But evaluating model behaviour for every data corner is infeasible. Multi-modal search provides a mechanism for broad, flexible interrogation of how a model functions, what it captures accurately or omits for different modalities. This meta-analysis, enabled by joint text and image understanding in vector space, is crucial to build trust and safety into AI systems.

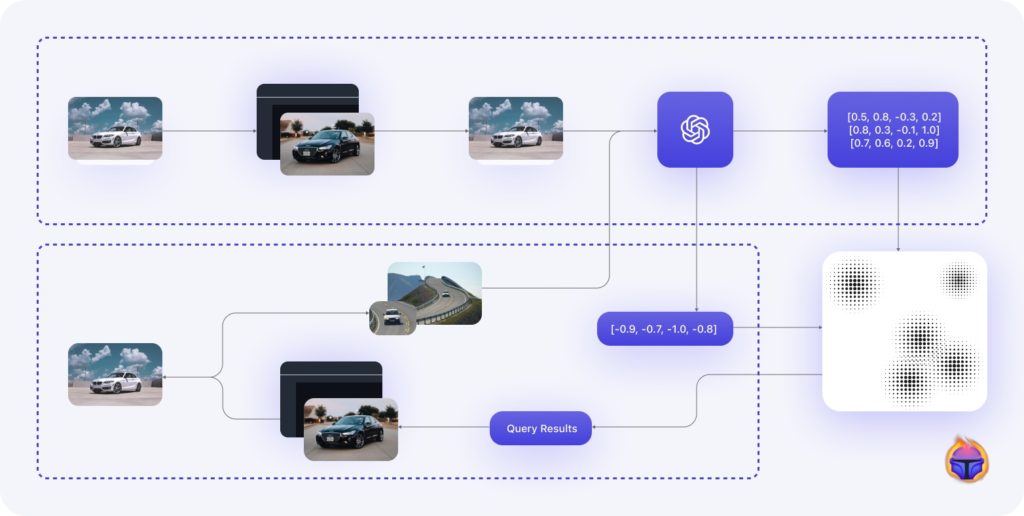
Figure 2. More detailed view of search pipeline in the Tenyks platform
Tenyks search pipeline
At Tenyks we take advantage of embeddings to enable multi-modal search. Figure 2 shows at a high-level Tenyk’s multi-modal search pipeline.
- After you upload a dataset, we use a number of embedding models (e.g. CLIP), depending on the use-case, to extract the embedding of each image in your dataset
- These embeddings are stored (i.e. indexed) in a vector database, which is responsible of handling and managing all the operations related to the embeddings (i.e. create or edit records).
Both, 1 and 2 comprise the indexing stage of the search pipeline. All the remaining steps correspond to the search stage. - A user in the Tenyks platform inputs a query by:
- Image: simply selects one of the images in the dataset.
- Text: a phrase such as: “find images of cars waiting for pedestrians to cross the street”.
- Cropped-out object: this corresponds to bounding box objects in a particular image
- The embedding model (e.g. CLIP) takes the query as input, and yields its embedding as output.
- The vector database receives the embedding (i.e the query), applies a similarity search algorithm (e.g. cosine similarity) to find the most similar indexed embeddings to the given query.
- The nearest neighbour results from the vector database are organized based on relevance/similarity score, where the top ranked images are returned as the search results for the given query.
- The user can see on the Tenyks platform the result of her/his query.
Multi-modal image search in action
At Tenyks, we perform lightning-fast image searches across large volumes of vector data.
Here’s an example of a use case of multi-modal search in action. Using the BDD dataset, a driving dataset, we are interested in searching for images based on three different modalities.
Text search
We can start by finding images of taxis by querying using the text: “Taxis”. As shown in Figure 3, after typing the desired text query, we obtain a set of images, each of which contains at least one taxi.
Figure 3. Searching for images using text
Image search
Next, we can also provide a given image as input. Figure 4 demonstrates how, after selecting an image containing crosswalks, the search engine retrieves a set of images that also displays crosswalks.
Figure 4. Given an image, we can use multi-modal search to retrieve similar images
Object-level search
Lastly, suppose you are interested in conducting a more granular search. Instead of searching by selecting a whole image, we can do object-level search. Figure 5 illustrates how, by intentionally selecting an object from the Bus class, the search results contain images with objects of the class Bus.
Figure 5. Multi-modal search in the Tenyks platform given a cropped-out object (i.e. Bus class)
Summary
Using a vector database optimized for similarity search over embeddings enables the Tenyks platform to do multi-modal image search at very large scale, with tens of thousands of images indexed and queries taking just milliseconds. The end result is a search experience where the results are ranked based on semantic visual similarity rather than just keywords or metadata.
References
[1] Segment Anything
[2<] Learning Transferable Visual Models From Natural Language Supervision/a>
Authors: Jose Gabriel Islas Montero, Dmitry Kazhdan