This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
New research aims to revolutionize video accessibility for blind or low-vision (BLV) viewers with an AI-powered system that gives users the ability to explore content interactively. The innovative system, detailed in a recent paper, addresses significant gaps in conventional audio descriptions (AD), offering an enriched and immersive video viewing experience.
“Although videos have become an important medium to access information and entertain, BLV people often find them less accessible,” said lead author Zheng Ning, a PhD in Computer Science and Engineering at the University of Notre Dame. “With AI, we can build an interactive system to extract layered information from videos and enable users to take an active role in consuming video content through their limited vision, auditory perception, and tactility.”
ADs provide spoken narration of visual elements in videos and are crucial for accessibility. However, conventional static descriptions often leave out details and focus primarily on providing information that helps users understand the content, rather than experience it. Plus, simultaneously consuming and processing the original sound and the audio from ADs can be mentally taxing, reducing user engagement.
Researchers from the University of Notre Dame, University of California San Diego, University of Texas at Dallas, and University of Wisconsin-Madison developed a new AI-powered system addressing these challenges.
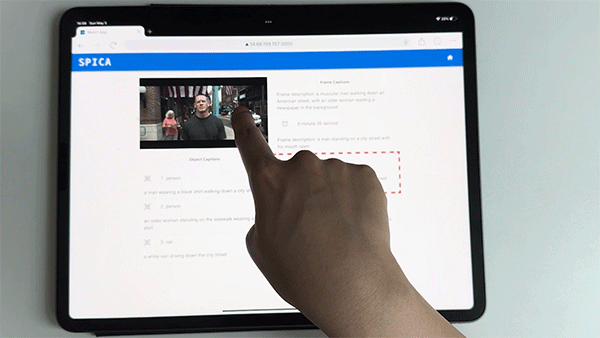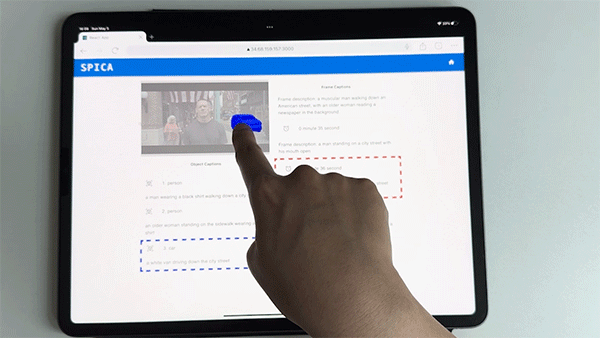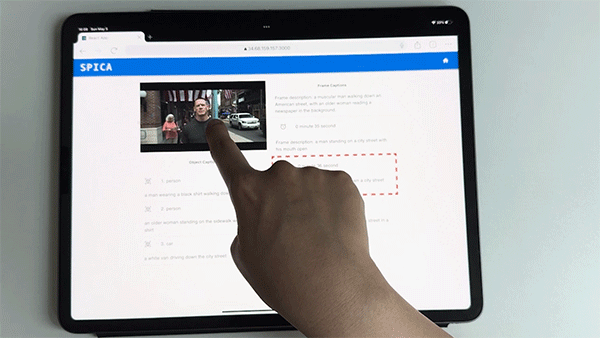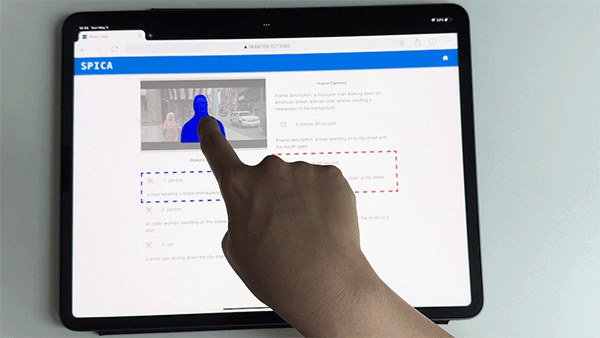
Called the System for Providing Interactive Content for Accessibility (SPICA), the tool enables users to interactively explore video content through layered ADs and spatial sound effects.
The machine learning pipeline begins with scene analysis to identify key frames, followed by object detection and segmentation to pinpoint significant objects within each frame. These objects are then described in detail using a refined image captioning model and GPT-4 for consistency and comprehensiveness.
The pipeline also retrieves spatial sound effects for each object, using their 3D positions to enhance spatial awareness. Depth estimation further refines the 3D positioning of objects, and the frontend interface enables users to explore these frames and objects interactively, using touch or keyboard inputs, with high-contrast overlays aiding those with residual vision.
 Figure 1. The machine learning pipeline consists of several modules for producing layered frame-level descriptions, object-level descriptions, high-contrast color masks, and spatial sound effects
Figure 1. The machine learning pipeline consists of several modules for producing layered frame-level descriptions, object-level descriptions, high-contrast color masks, and spatial sound effects
SPICA runs on an NVIDIA RTX A6000 GPU, which the team was awarded as a recipient of the NVIDIA Academic Hardware Grant Program.
“NVIDIA technology is a crucial component behind the system, offering a stable and efficient platform for running these computational models, significantly reducing the time and effort to implement the system,” said Ning.
This advanced integration of computer vision and natural language processing techniques enables BLV users to engage with video content in a more detailed, flexible, and immersive way. Rather than being given predefined ADs per frame, users actively explore individual objects within the frame through a touch interface or a screen reader.
SPICA also augments existing ADs with interactive elements, spatial sound effects, and detailed object descriptions, all generated through an audio-visual machine-learning pipeline.
SPICA is an AI-powered system that enables BLV users to interactively explore video content
During the development of SPICA, the researchers used BLV video consumption studies to align the system with user needs and preferences. The team conducted a user study with 14 BLV participants to evaluate usability and usefulness. The participants found the system easy to use and effective in providing additional information that improved their understanding and immersion in video content.
According to the researchers, the insights gained from the user study highlight the potential for further research, including improving AI models for accurate and contextually rich generated descriptions. Additionally, there’s potential for exploring using haptic feedback and other sensory channels to augment video consumption for BLV users.
The team plans to pursue future research using AI to help BLV individuals with physical tasks in their daily lives, seeing potential with recent breakthroughs in large generative models.
Michelle Horton
Senior Developer Communications Manager, NVIDIA
The AI for Good blog series showcases AI’s transformative power in solving pressing global challenges. Learn how researchers and developers leverage groundbreaking technology and launch innovative projects using AI to create positive change for people and the planet.
This content was partially crafted with the assistance of generative AI and LLMs. It underwent careful review by the researchers and was edited by the NVIDIA Technical Blog team to ensure precision, accuracy, and quality. Quotes are original.