
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica.
Why data is expensive
Data is the bedrock of any AI/ML project, and serves as the vital link between mathematical algorithms and real-world problems. And yet, we often grapple with two common data-related challenges, which are the scarcity of available data and lack of diversity in available data. If not addressed, these issues can significantly hamper the effectiveness of our AI solutions.
These problems are especially prominent in the medical field. Typically, gathering the required data on-site is expensive. For example, a single MRI acquisition usually costs upwards of $1,200, and we need thousands, if not tens of thousands, of scans to build a reliable ML model. However, it is not enough to just have a large pool of data. This data must also be as diverse as possible, in order to account for variations in human bodies, medical equipment, settings and numerous other factors.
The hope for a solution
One potential solution to the problem of the lack of data is to generate synthetic data. You may already be familiar with Generative AI, a powerful branch of ML, because you’ve used ChatGPT (and other chatbots) for text generation or you’ve used Stable Diffusion and Midjourney for image generation. Well, generative models can also produce new data out of thin air.
Recently, one of our regular customers asked us to investigate the current state-of-the-art in relation to GenAI to find out if this technology is mature enough to be applied to medical solutions. In particular, the customer sought to extend their existing dataset of various medical scans (including X-ray, CT, MRI, etc.) with less typical samples.
To be clear, most (but not all) of the medical scans normally acquired in a clinic or hospital are drastically imbalanced, skewing towards particular “most common” combinations. For example, X-ray scans are typically carried out on lungs or limbs, whereas MRI scans are usually limited to the brain and occasionally to internal organs. Each of the body parts is also typically scanned with particular device settings.
Where we are now
While researching the topic, our primary technical goal was to find any existing models that would be able to generate realistic medical scans. Alternatively, we would report back that no such models existed. In particular, the customer was interested in the synthesis of a wide range of body parts in different modalities (for example, X-ray, CT, MRI) and with different device settings. At this stage, the emphasis was not on trying to develop a custom solution for the domain problem, but on seeing what already existed in terms of research papers and off-the-shelf solutions.
Before diving into the research, we identified the three main paths that could be taken to generate any missing medical data:
- Direct use of generative models that are similar to GAN or StableDiffusion
- Augmentation via transformation
- Physical simulation
The latter two approaches are slightly beyond the scope of this post, so let’s expand on the general ideas behind those approaches, and then skip to the anticipated use of Gen AI.
Approach 2: Augmentation via transformation
With particular settings, we can take an existing piece of data, transform it somehow and then obtain a somewhat new data point. The range of ideas is quite vast, but most of them focus on either particular properties of particular types of scans or are applicable only to a narrow subset of end tasks. For example, MRI weighting [ref] is one of the most important defining parameters for such a scan. If you have access to the raw acquisition data (which, frankly, is rarely the case), you can mathematically approximate what the same scan would look like if it were acquired under different conditions. Overall, this approach is more about smaller highly-specialized ideas and can rarely be applied to the task of extending a general dataset.
Approach 3: Physical simulation
This approach is the most straight-forward, but the least feasible. There are plenty of software simulation packages for all sorts of modalities: XRray, MRI, CT, Ultrasound, etc. This software typically takes in a special kind of highly detailed physical 3D model (known as a “phantom”) and outputs a physically accurate raw scan, exactly as if it were generated by a real scanner.
There is only one downside, but it is a huge one. These 3D models are extremely difficult to find, cost a small fortune and provide little-to-no variance per model. Indeed, some post-processing augmentation could be developed to gain the variance, but that would contradict the goal of the research, which was to find the scope of what already exists.
Approach 1: Generative Models
Before talking about the extent to which existing generative models can solve a medical problem, let’s discuss what these models are and how they work. This will help to paint a better picture below.
The goal of any image-generating model is to produce an image that is similar to a particular category of existing images, but is somehow different from all of them. Nowadays, the two most popular architectures for such models are Generative Adversarial Networks (GAN) and Stable Diffusion.
GAN models are based on the idea of having two models during the training phase. The first one, the “generator,” attempts to generate a random image. The second one, the “discriminator,” is given two images, where one image is taken from a training set and the other is generated by the “generator” model. The goal of the “discriminator” is to figure out which of the two images is real and which is artificial, while the “generator” is progressively trying to get better at fooling the “discriminator”. The whole process is often compared to how counterfeiters and police compete in the real world. After many iterations, the “generator” model should be able to produce fairly realistic images, at which point the training is stopped and the model is ready to be used.
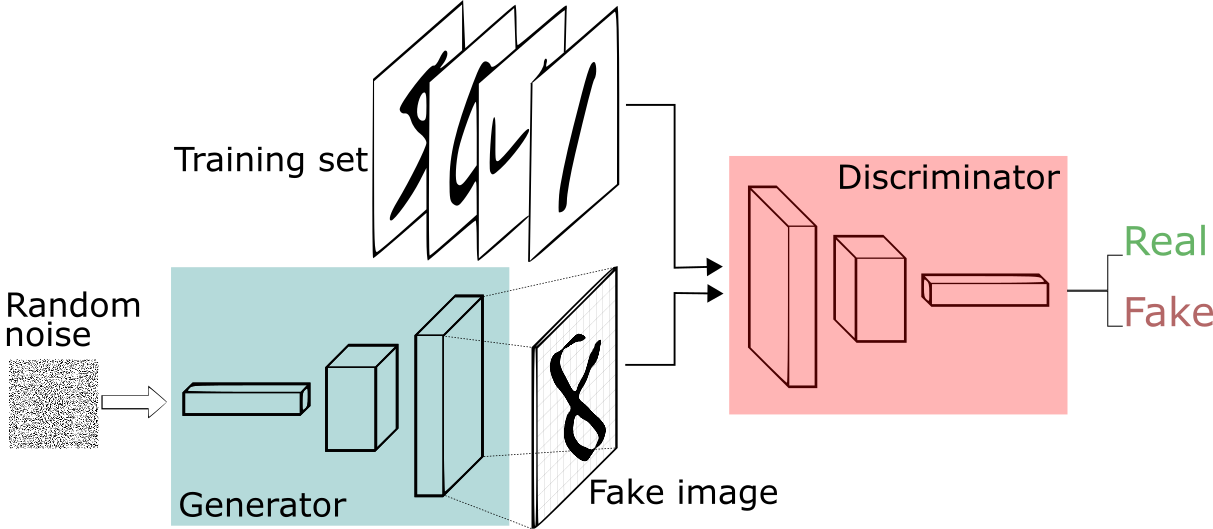 (source: https://sthalles.github.io/intro-to-gans/)
(source: https://sthalles.github.io/intro-to-gans/)
On the other hand, Stable Diffusion is a much more recent approach which takes a completely different path. In this method, we take a real sample image and progressively add noise to it to the point where the source image becomes unrecognizable. Then, the model tries to “restore” the original image from the set of “noise” that was originally an image of, say, a cat.
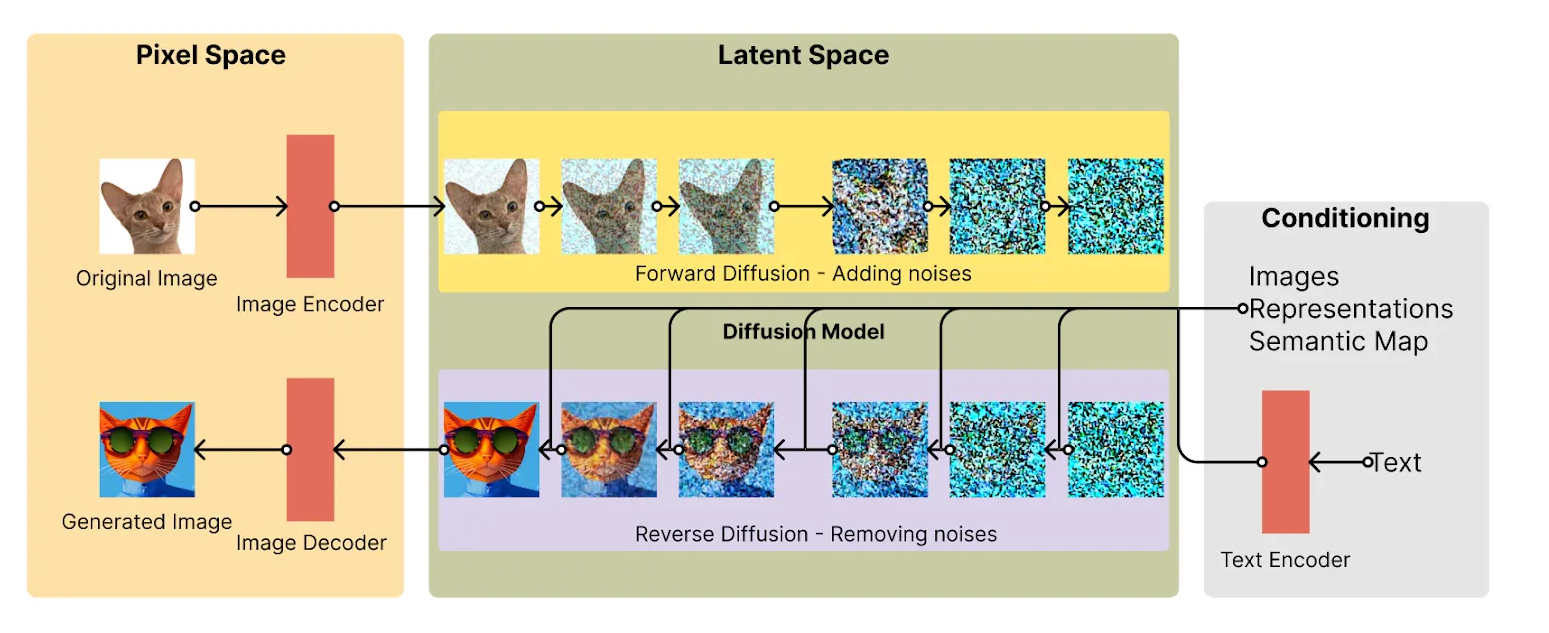 (source:
(source: The methods are not complete mirror images of themselves. For example, it is arguable that GANs are more reliable than SDs in terms of stability. [src]
Both architectures can be relatively easily augmented with text prompts to guide the generation process. And both kinds of models are already being actively used to generate various images, including medical images. However, that’s where reality steps in because all the trained models that we found can be split into two categories:
- Highly-specialized,
- Jacks of all trades.
Let’s consider the specialized category first. These models produce fairly realistic results and tend to hallucinate very little. The tradeoff is that they rarely cover more than one body part and/or one acquisition setting. In practice, this means that there are hundreds of good models, but, all combined, they can produce an extremely limited variety of scans.
For example, while doing the first pass of the investigation, we found a dozen actively maintained MRI models, but all of them covered exclusively brain scans. By contrast, none of them had the capacity to generate, say, a finger. And I will explain below why the reason for this is quite simple.
Next, let’s consider models that claim to generate almost anything. As you would expect, it’s almost impossible to do well at “all” tasks. The question is, on average, how well do these models work. Unfortunately, they don’t work as well as we’d like. One of the first problems is the infamous difficulty of generating the right number of fingers. [imgs from slide deck]. Overall, after carrying out some tests, we had to conclude that these models, despite being promising and sometimes advertised as a panacea, are still far from being good enough to be applied in the medical domain, which has demanding requirements.
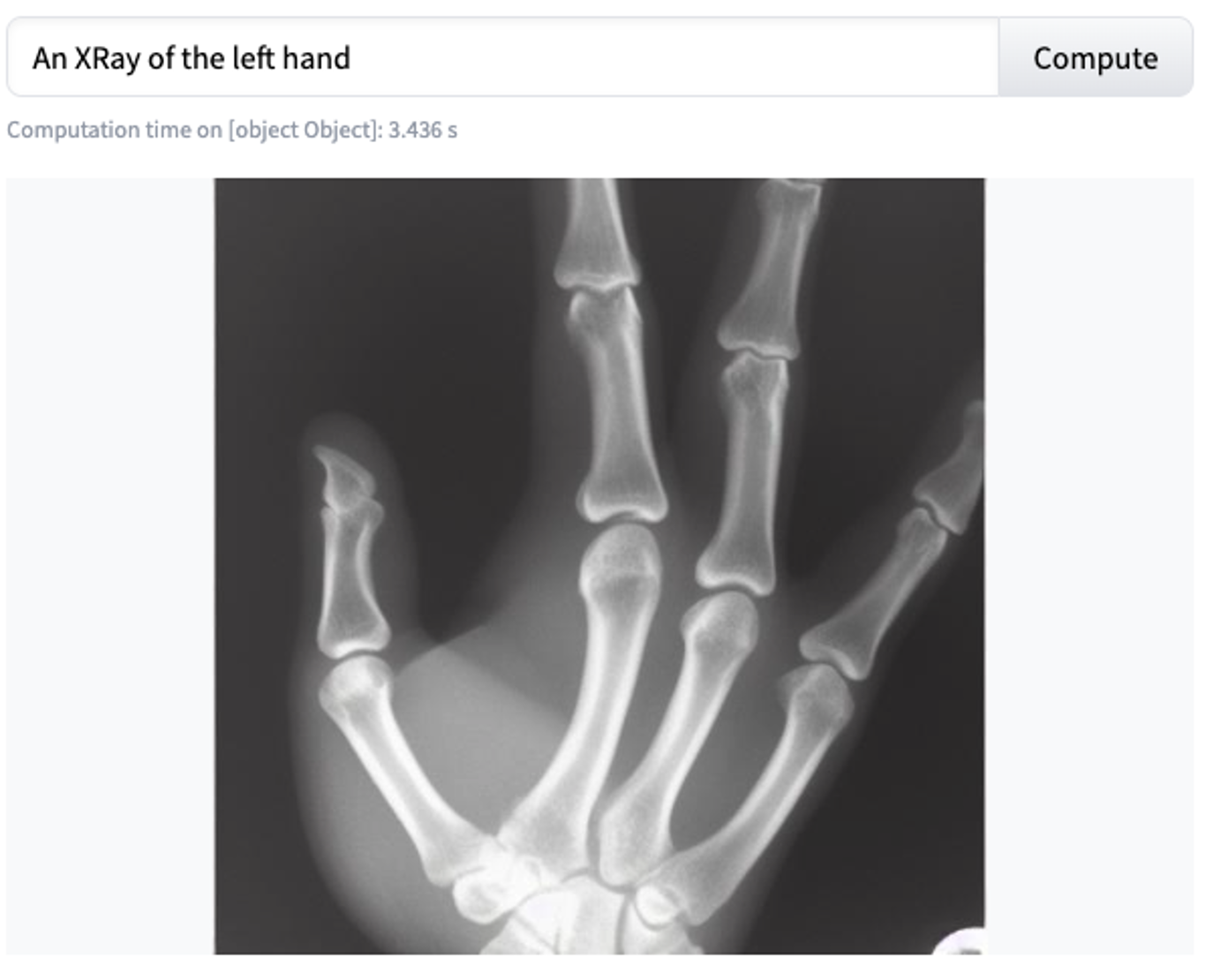 |
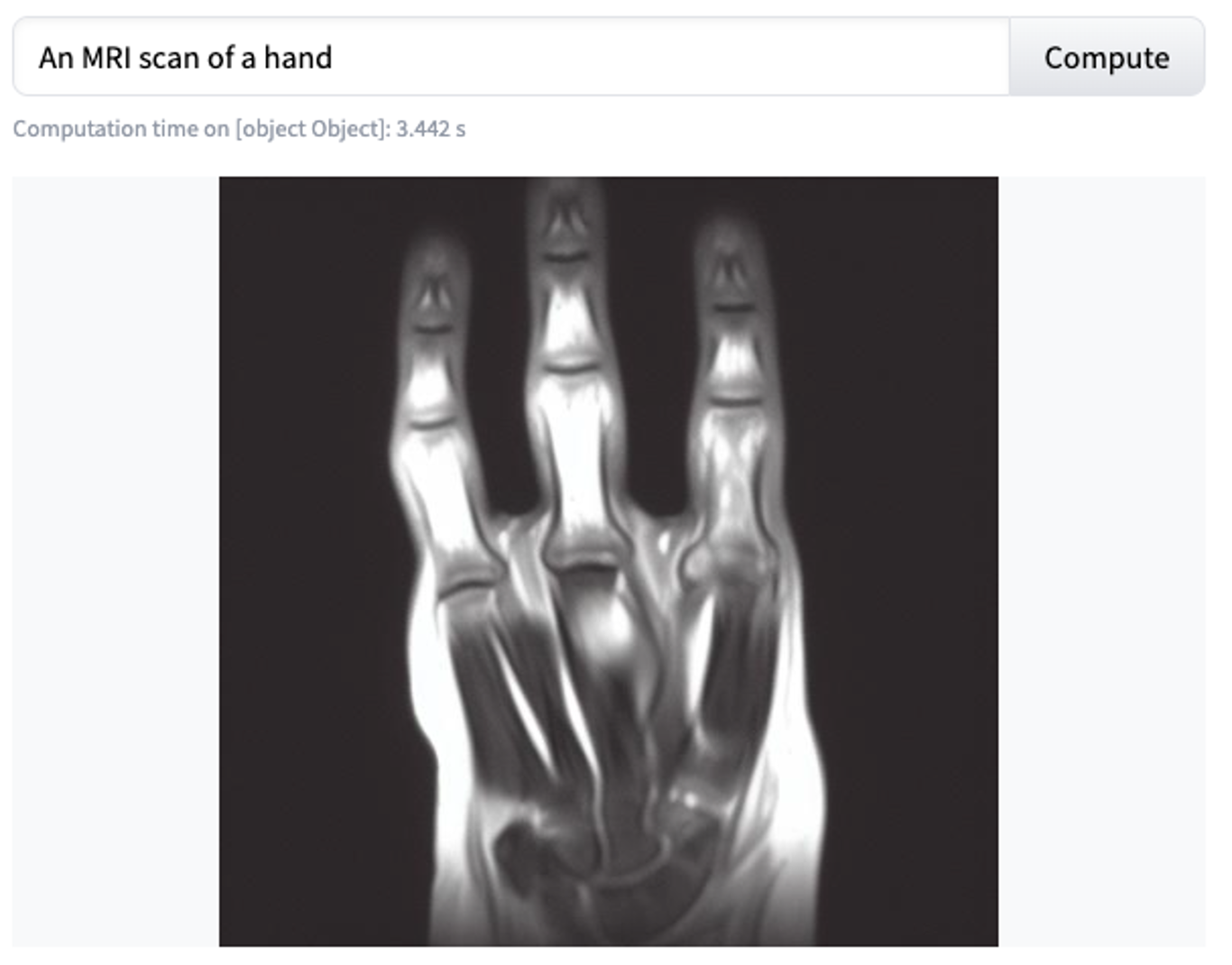 |
The bigger problem
In addition to the not-so-promising tradeoff between the quality of the output and the variety of images a model can generate, there’s a much bigger problem. All of the models that we tested provide either no external control (that is, they always generate a random image) or control is limited to a text-based prompt. At this time, no model provides meaningful and deterministic user input about the setup in which the supposed scan was acquired. This means that, even when we have a decent dataset of, say, T1-weighted brain MRIs, there’s no reliable way to augment it to synthetically generate, for example, T2-weighted brain MRIs. That is, unless you managed to find a specialized model for that purpose, which is usually not possible or feasible. This problem doesn’t exist in the world of physics-based simulations, but as discussed above, that approach also has serious problems.
Conclusion
Whether we like it or not, generative models are still ML models. And the main fuel for an ML model is the data. The lack of good and reliable medical models stems not from the immaturity of the technology or lack of powerful hardware, but from the simple fact that it is extremely difficult to find diverse and high-quality medical datasets. There are many reasons why this is the case, but the key ones, amongst others, are privacy concerns and the overall lack of organised data handling in most medical facilities.
At Digica, we’re actively working on multiple projects that aim to drastically ease and improve the whole process of data collection, management and storage. We hope and believe that these improvements will have a positive effect on the entire medical AI market and kickstart more advancements in AI healthcare.
To conclude the description of the current state of Generative AI in the medical domain, we’re sad to say that it is not yet ready for such an important task. Although individual models can and are being applied to particular problems, we’re still looking to the future for GenAI to become more mature. Until then, Digica is happy to provide its services and vast experience to help you build your custom solution to change the world 🙂
Vladimir Kirilenko
Senior Data Scientist, Digica