
This blog post was originally published at Tryolabs’ website. It is reprinted here with the permission of Tryolabs.
From Face ID unlocking our phones to counting customers in stores, Computer Vision has already transformed how businesses operate. As Generative AI (GenAI) becomes more compelling and accessible, this tried-and-tested technology is entering a new era of possibilities. The convergence of Computer Vision with GenAI now enables organizations to extract deeper insights and automate more complex tasks, directly impacting operational efficiency and bottom-line results.
While Computer Vision has long excelled at tasks like object detection and classification, Large Language Models (LLMs) bring a new dimension: the ability to understand context, generate natural language descriptions, and make complex inferences from visual data. This combination transforms video content from a passive asset into a strategic source of business intelligence, offering unprecedented insights and automation capabilities.
Let’s explore how Computer Vision has evolved from basic detection to data-driven business solutions. Through technical analysis and real-world examples across industries we’ll examine how organizations are combining Computer Vision with Language Models to transform visual data into actionable insights. Whether you’re considering implementing these technologies or looking to optimize existing solutions, this article will help you understand both the technical foundations and practical business applications.
The technical foundations of Computer Vision
At its core, Computer Vision empowers computers to “see” and interpret visual information; much like the human eye, it involves tasks such as image classification, object detection, and tracking, allowing computers to identify objects, understand scenes, and analyze movements. Traditionally, these capabilities rely on deep neural networks (particularly Convolutional Neural Networks, or CNNs) to process and analyze visual data. The story of how we taught machines to see unfolds through decades of innovative approaches.
From basic detection to Deep Learning
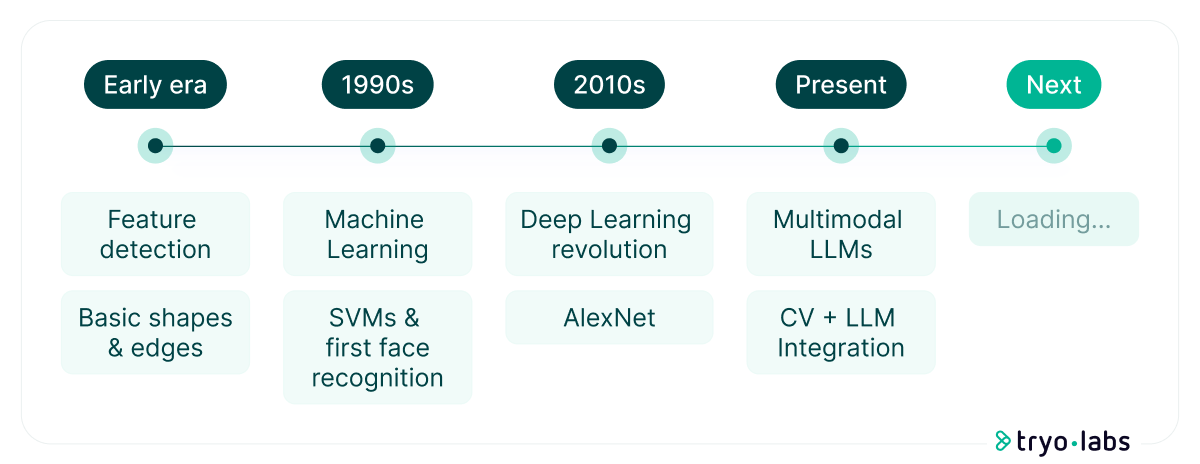
At the dawn of the Computer Vision era, most algorithms focused on feature detection, identifying edges, lines, and basic shapes. These methods were heavily influenced by concepts from Gestalt Theory, Signal Processing, and Statistics, forming the backbone of early Computer Vision systems. In the 1990s, the Machine Learning revolution began with the introduction of methods like Support Vector Machines (SVMs), which enabled the creation of classifiers based on extracted features. This breakthrough led to the first face recognition systems that did not rely on handcrafted features.
The 2010s marked the beginning of the Deep Learning era, fundamentally transforming the field. While Convolutional Neural Networks (CNNs) existed previously, AlexNet revolutionized Computer Vision by demonstrating the power of deep architectures trained on large datasets using GPU acceleration. Its breakthrough performance in the ImageNet competition established deep CNNs as the cornerstone of modern Computer Vision. Subsequent advancements, such as ResNet and EfficientNet, improved both model performance and efficiency, driving widespread adoption across industries. Building these sophisticated Computer Vision solutions required substantial effort and technical expertise. Engineers needed to make critical decisions about network architecture—such as which family to use, the depth and width of the network, whether to apply normalization, and how to fine-tune parameters like dropout rates. They also had to code training pipelines, select optimization algorithms (e.g., Adam vs. SGD), and fine-tune hyperparameters like learning rate and batch size. Preparing datasets was another significant challenge, involving careful annotation, ensuring class balance, verifying that the dataset adequately represented the problem, and defining augmentation techniques to generate more samples. Success demanded not just technical knowledge, but also extensive experimentation and intuition.
While these systems achieved impressive accuracy in identifying objects, tracking movement, and segmenting images, they operated like a skilled observer who could identify what they saw but couldn’t explain why it mattered. In 2012, Andrej Karpathy reflected on this limitation, suggesting that computers might need years of real-world experience to truly understand visual scenes – a daunting challenge at the time. Fast forward to today, the integration of Large Language Models has helped bridge this gap between perception and understanding, transforming raw visual data into actionable insights.
Large Language Models transforms raw visual data into actionable insights.
Computer Vision core capabilities
Building on decades of research and technological advancement, Computer Vision systems have evolved to handle increasingly complex visual tasks through three main capabilities:
 |
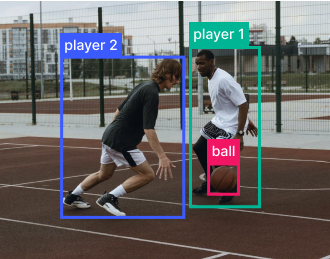 |
Object detection and recognition:
Modern architectures like YOLO (You Only Look Once) and Faster R-CNN can detect multiple objects in real-time, providing bounding boxes and confidence scores for each detection.
Scene understanding:
Going beyond individual object detection, this involves semantic segmentation, where each pixel is classified into categories (like “player” or “ball”), and instance segmentation that distinguishes between different instances of the same object class.
Video analysis:
These capabilities extend to temporal dimensions, enabling object tracking across frames, motion detection, and activity recognition, while handling challenges like occlusion and varying lighting conditions.
Explore our guide to dive deep into Computer Vision fundamentals.
How LLMs transform Computer Vision’s potential
The integration of Computer Vision and LLMs has given rise to multimodal or vision-language models (VLMs). These systems represent a significant advance over traditional Computer Vision that only outputs structured data like bounding boxes and labels. While Computer Vision provides the “eyes” to see and detect, LLMs add the ability to understand context and communicate insights in natural language.
This integration offers several key capabilities:
Natural Language descriptions
Instead of merely reporting “person detected at (x1, y1, x2, y2),” a vision-language model can generate richer insights—for example, “An elderly person is walking slowly with a cane on a crowded sidewalk, possibly needing assistance.”
Contextual and reasoning capabilities
Multimodal LLMs can infer relationships and context beyond basic object detection. For instance, they can connect cultural references, identify emotional expressions, or generate hypotheses about a scene. This enables functionalities like Visual Question Answering (VQA), where users ask questions in plain English and receive responses about the content of an image or video.
Streamlined user interaction
These models allow for user-friendly “prompt-based” queries. An operator or analyst can type, “Show all instances where a person is running”, and the system can return timestamped video segments or annotated images matching this description—without the user needing to write complex code.
Business impact and real-world applications
The convergence of Computer Vision and LLMs is revolutionizing how organizations extract and act on visual data. This integration drives transformation across four key dimensions:
- Enhanced data analysis: Generating actionable insights from visual information
- Intelligent automation: Creating self-improving workflows for complex visual tasks
- Strategic workforce evolution: Transforming how organizations deploy human talent
- Market innovation: Enabling entirely new products and services
Let’s explore how organizations are leveraging these capabilities to create measurable impact.
Consider how a major luxury consignment marketplace transformed their authentication process. Their specialists were spending 25% of their time manually transcribing product attributes from clothing tags – a $2M annual expense that also introduced risks of human error. By implementing an intelligent automation system that captures and processes diverse luxury tag formats, they not only eliminated this cost but fundamentally reshaped their workforce utilization. This exemplifies how organizations can elevate human expertise – freeing specialists from routine tasks to focus on critical verification work that demands their judgment and experience.
The impact of CV + LLMs integration extends far beyond automation. In the security space, we’re seeing how this technology enables sophisticated anomaly detection that enhances human decision-making. Working with a surveillance camera manufacturer, we developed a system combining Computer Vision with Google’s Gemini model to achieve 95% recall in rapid detection. The system provides contextual insights that security personnel can immediately act upon, demonstrating how AI can amplify rather than replace human expertise.
The result is a fundamental shift in how organizations approach visual data – from isolated analysis to integrated intelligence that drives decision-making across all levels of operation. This transformation isn’t just about automating existing processes; it’s about reimagining what’s possible when machines can both see and communicate their insights effectively.
This integration enables a powerful cycle: Computer Vision captures visual data, LLMs interpret it, and the system delivers actionable insights, creating continuous value by transforming visual information into business advantage.
From theory to practice: Computer Vision and LLMs integration
After exploring the capabilities and advantages of Computer Vision enhanced by LLMs, let’s examine how these technologies can be effectively integrated and what key considerations organizations need to address during implementation.
Integration architecture
Most organizations don’t build multimodal systems from scratch when integrating Computer Vision with LLMs. Instead, they typically leverage and fine-tune existing models like CLIP, BLIP, GPT-4V, or Flamingo. While this approach is common and often effective, it’s not always the best solution for every use case – a topic we’ll explore in detail later when discussing implementation considerations.
A successful integration of Computer Vision and LLMs typically follows a three-layer architecture that serves as a blueprint for implementation:

Visual processing layer
This foundational layer handles the initial processing of visual data:
- Manages image and video ingestion and preprocessing
- Employs pre-trained models (such as YOLOv8, Faster R-CNN) for object detection, classification, and segmentation
- Extracts structured metadata including bounding boxes and class labels
- Ensures scalable inference through GPU deployment and acceleration
- Optimizes for low-latency processing in real-time applications like surveillance
Context integration layer
Acting as a crucial bridge between vision and language components, this layer:
- Converts Computer Vision outputs into LLM-compatible formats
- Transforms technical detections (e.g., “Person(87% confidence)”) into natural language prompts
- Engineers contextual prompts that capture relevant scene details
- For video applications, maintains temporal memory to track object movements and scene changes over time (e.g., “Person walked from left to right”)
Language processing layer
The final layer that delivers human-understandable insights:
- Utilizes pre-trained or fine-tuned LLMs that support vision-language tasks
- Processes both text and image embeddings when available
- Generates natural language outputs and responds to user queries
- Integrates with business systems for automated alerts and actions (e.g., notifications for unauthorized access)
This architecture balances technical capabilities with practical implementation needs, providing a flexible framework that can be adapted to various use cases and requirements.
Deployment and performance optimization
When deploying Computer Vision and LLM integrations, three key technical areas require careful consideration:
Performance optimization
The balance between batch and real-time processing significantly impacts system architecture. While batch processing maximizes throughput for large-scale offline analyses, real-time systems require careful optimization to reduce latency. For resource-constrained environments, model quantization (FP16, INT8) can improve efficiency without significant accuracy loss.
Scalability architecture
A microservices approach enables independent scaling of Computer Vision and LLM components based on demand. Load balancing across multiple inference nodes helps handle traffic surges efficiently, while maintaining system responsiveness.
Resource management
Both Computer Vision and LLM workloads are GPU-intensive, requiring strategic resource allocation. Efficient memory management through optimized data formats and smart caching strategies helps avoid redundant computations and reduces overall system load.
While pre-trained Computer Vision models and existing multimodal LLMs offer quick deployment options for most business needs, certain scenarios still demand custom development and specialized solutions.
- Specialized domains: Medical imaging and industrial inspection require higher precision than general models can provide
- Performance-critical: Real-time applications like autonomous driving need optimized architectures for speed and throughput
- Regulatory compliance: Healthcare and finance often require on-premises solutions to maintain data privacy and control
- Edge cases: Rare equipment identification and unusual scenarios demand custom training beyond standard datasets
Conclusion
Through this exploration, we’ve seen how this integration enables real value for business, from operational improvements to innovation opportunities. The success of these implementations relies on understanding the evolution and capabilities of both technologies, choosing the right integration approach for specific business needs, and careful consideration of technical requirements, from architecture design to deployment optimization.
Over the last 15 years in the AI industry, we’ve witnessed and participated in this technological evolution firsthand, from basic object detection to today’s sophisticated multimodal systems. Our expertise lies at the intersection of cutting-edge AI capabilities and solving business challenges. If you’re interested in exploring solutions that can transform your business, let’s connect and discuss the possibilities.
Florencia Sanguinetti
Marketing Analyst, Tryolabs
Juan Pablo González
Machine Learning Expert, Tryolabs