
This article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
In today’s data-driven world, the ability to retrieve accurate information from even modest amounts of data is vital for developers seeking streamlined, effective solutions for quick deployments, prototyping, or experimentation. One of the key challenges in information retrieval is managing the diverse modalities in unstructured datasets, including text, PDFs, images, tables, audio, video, and so on.
Multimodal AI models address this challenge by simultaneously processing multiple data modalities, generating cohesive and comprehensive output in different forms. NVIDIA NIM microservices simplify the secure and reliable deployment of AI foundation models for language, computer vision, speech, biology, and more.
NIM microservices can be deployed on NVIDIA-accelerated infrastructure anywhere and expose industry-standard APIs for fast integration with applications and popular AI development frameworks, including LangChain and LlamaIndex.
This post helps you get started with building a vision language model (VLM) based, multimodal, information retrieval system capable of answering complex queries involving text, images, and tables. We walk you through deploying an application using LangGraph, the state-of-the-art llama-3.2-90b-vision-instruct VLM, the optimized mistral-small-24B-instruct large language model (LLM), and NVIDIA NIM for deployment.
This method of building simple information retrieval systems offers several advantages over traditional ones. The latest VLM NIM microservice enables enhanced contextual understanding by processing lengthy, complex visual documents without sacrificing coherence. The integration of LangChain’s tool calling enables the system to create tools, dynamically select and use external tools, and improve the precision of data extraction and interpretation from various sources.
This system is good for enterprise applications because it generates structured outputs, ensuring consistency and reliability in responses. For more information about the implementation steps of this system, see the /NVIDIA/GenerativeAIExamples GitHub repo.
A simple HTML multimodal retrieval pipeline
The system consists of the following pipelines:
- Document ingestion and preprocessing: Runs a VLM on the images and translates them into text.
- Question-answering: Enables the user to ask questions of the system.
Both pipelines integrate NVIDIA NIM and LangGraph to process and understand text, images, complex visualizations, and tables effectively.
Data ingestion and preprocessing pipeline
This stage parses documents to process text, images, and tables separately. Tables are first converted into images, and images are processed by the NVIDIA-hosted NIM microservice API endpoint for the llama-3.2-90b-vision-instruct VLM to generate descriptive text.
Next, in the document reconstruction step, the descriptive text is merged with the original text of the document, then summarized by an LLM with long context modeling capability. In this implementation, llama-3.2-90b-vision-instruct is also used as the LLM, although other LLMs such as mistral-small-24b-instruct can also be deployed.
Finally, the complete text, summaries, images, and their descriptions are stored in a NoSQL database, along with unique document identifiers.
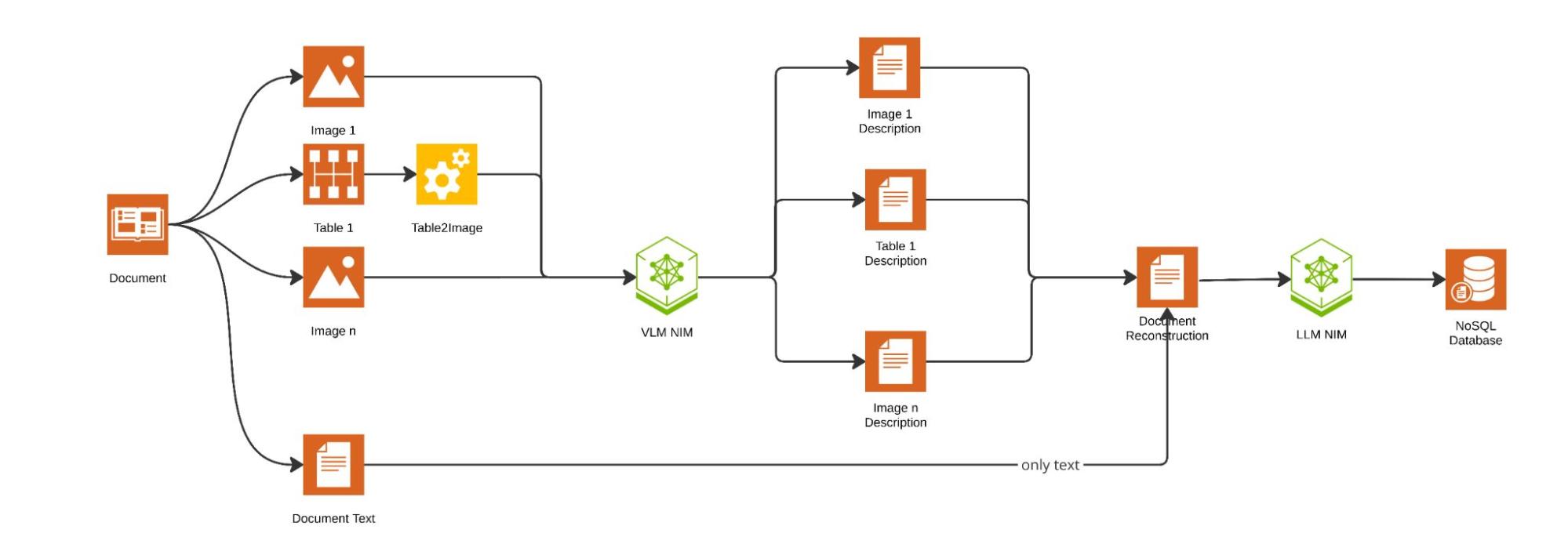 Figure 1. Data ingestion and preprocessing pipeline
Figure 1. Data ingestion and preprocessing pipeline
LLMs with long context modeling can process entire documents without fragmentation, enhancing comprehension of the document in a single pass, and capturing relationships and nuances across longer spans of text, leading to more accurate information retrieval.
In contrast, traditional models may handle inputs of up to a few thousand tokens, requiring lengthy documents to be split into smaller chunks to fit within the model’s context window. This chunking process can disrupt coherence and context, making it more difficult to accurately retrieve and rank relevant information.
However, long context modeling presents challenges related to scalability and cost, which must be considered when trading off with higher accuracy.
QA pipeline
All document summaries and their identifiers are compiled into a large prompt. When a query is sent, a LLM with long context modeling (mistral-small-24b-instruct in this case) processes the question, evaluates the relevance of each summary to the query, and returns the identifiers of the most relevant documents.
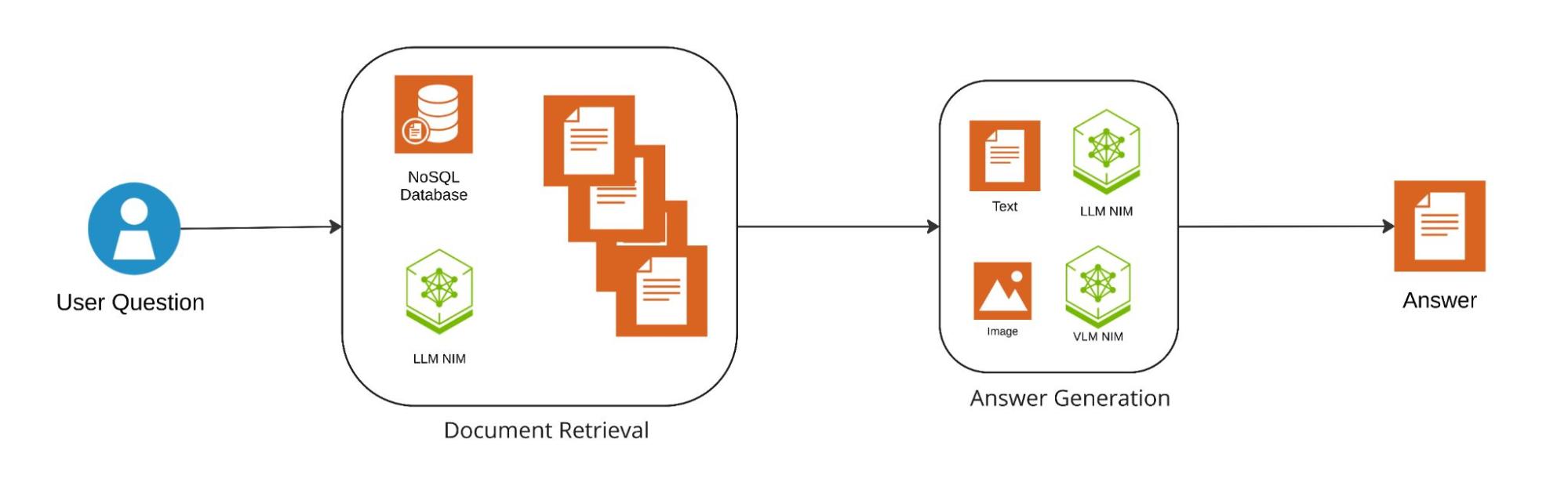 Figure 2. Question-answering pipeline
Figure 2. Question-answering pipeline
Next, the most relevant documents are fed into an LLM with long context (mistral-small-24b-instruct). The model generates an answer to the query based on the textual content. If the model identifies that an image may contain pertinent information based on its descriptive text, an additional step is triggered: the original image and the user’s question are sent to the VLM (llama-3.2-90b-vision-instruct), which can provide an answer based on the actual visual content.
Finally, the system combines both textual and visual insights to deliver a comprehensive answer.
Structured outputs ensure that the data returned by the model conforms to a predefined format, making it easier to extract specific information and perform subsequent operations. In contrast, unstructured or variable outputs can introduce ambiguities and difficulties in parsing the model’s responses, hindering automation and integration with other systems.
Generating structured data from models typically requires carefully designed prompts to guide the model into responding in a particular format, such as JSON. However, ensuring consistent adherence to this structure can be challenging due to the models’ natural tendency to generate free-form text.
NVIDIA NIM now natively supports capabilities for generating structured outputs. This means that you can rely on built-in functionalities to ensure that the model’s responses are consistently formatted, reducing the need for complex prompt engineering.
Integrating NVIDIA NIM with LangGraph
NVIDIA NIM offers seamless compatibility with popular frameworks and the latest AI models for your applications. The implementation of the pipeline integrates NVIDIA NIM with LangGraph, a framework to build agentic applications to determine the control flow, which has been widely adopted by the developer community. To orchestrate the workflow of this pipeline, the graph mainly consists of two nodes:
- Assistant node: Serves as an agent responsible for managing the logic and decision-making process. It interacts with the user’s inputs and invokes the necessary tools.
- Tools node: A collection of tools that perform specific tasks required by the assistant.
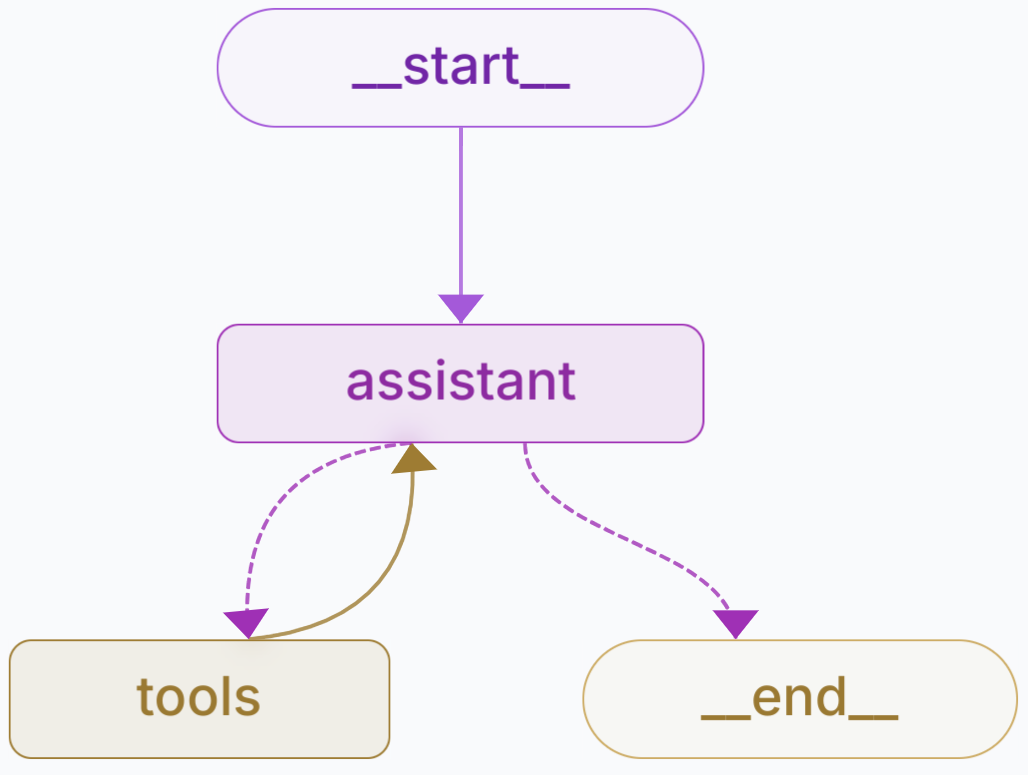 Figure 3. Use LangGraph to build an agent for the pipeline
Figure 3. Use LangGraph to build an agent for the pipeline
Assistant node
The assistant node is a primary agent that operates according to the workflow outlined in Figure 3. The code of the main agent can be found in the /NVIDIA/GenerativeAIExamples GitHub repo.
Here are the agent inputs:
Collection_name: The set of documents on which to search.Question: The user’s question.document_id: (Optional) If provided, the agent skips the document ranking phase.
This is the agent process:
- Document selection: If
document_idis not provided, the agent invokes thefind_best_document_idtool, which identifies the most relevant document for the user’s question within the specified collection. - Question answering: With
document_id, the agent uses thequery_documenttool. This tool attempts to answer the question using the LLM (mistral-small-24b-instruct) based on the text and image descriptions within the document. - Image analysis (if necessary): If the
query_documenttool indicates that the answer might be in an image (by returning animage_hashvalue), the agent invokes thequery_imagetool. This tool retrieves the actual image and uses a VLM to analyze the image and find the answer.
Tools node
We implemented three key tools for the agent to perform its tasks.
Find_best_document_id: Identify the most relevant document for the user’s question whendocument_idis not provided. For more information, see the /NVIDIA/GenerativeAIExamples GitHub repo.query_document: Search for an answer within the specified document. If the answer may be in an image, it provides details to query the image. For more information, see the /NVIDIA/GenerativeAIExamples GitHub repo.query_image: Analyze the actual image using a VLM when the answer might be within the image content. For more information, see the /NVIDIA/GenerativeAIExamples.
Binding external tools with models
Tool calling is a feature that enables language models to integrate and interact with external tools or functions based on the prompts that they receive. This mechanism enables a model to decide which tools to use and how to use them to accomplish specific tasks.
Tool binding empowers models to extend their capabilities dynamically, selecting appropriate tools during execution to provide more accurate, context-aware responses.
Binding external tools is particularly crucial in agentic frameworks, where agents must choose the appropriate tools and provide the necessary arguments to perform tasks effectively. The benefits of binding external tools include the following:
- Extended capabilities: Models can perform complex operations such as calculations, data retrieval, or API calls, which go beyond mere text generation.
- Dynamic tool selection: The model can assess in real time which tools are most suitable for the task, improving efficiency and relevance.
- Seamless integration: NVIDIA NIM supports the integration of external tools, such as LangChain and LangGraph, with open community models such as Llama 3.3. You can adopt these advanced features without making significant changes to your existing systems.
In this implementation, use LangChain’s @tool decorator to create three tools, then use the .bind_tools method to bind the tools with models.
Defining structured outputs with Pydantic
By defining the output schema with Pydantic and guiding an LLM NIM microservice such as mistral-small-24b-instruct through precise prompts, you ensure that the responses are consistent, reliable, and easily consumable by other components within the system. This approach is essential when integrating the LLM into automated workflows and agent-based frameworks such as LangGraph.
Define the structure
The process begins by defining the structure of the output that you expect from the LLM using Pydantic. This guarantees that the data returned by the model is consistent and can be easily parsed for downstream processing.
from typing import List, Optional
from pydantic import BaseModel, Field
class Document(BaseModel):
"""
Represents a document with an identifier and its summary.
"""
id: str = Field(..., description="Hash identifier of the document")
summary: str = Field(..., description="The summary of the document as is")
class BestDocuments(BaseModel):
"""
Contains a list of the best documents to answer the question and their summaries.
"""
documents: List[Document] = Field(..., description="List of best documents")
class Answer(BaseModel):
"""
Represents the answer to the user's question.
"""
answer: str = Field(..., description="Answer to the question posed by the user")Next, instruct the LLM to generate outputs that align with the defined Pydantic structures. This is achieved by incorporating specific instructions within the prompt and using LangChain’s with_structured_output method.
Define the prompt
The prompt_document_expert contains detailed instructions for the LLM, specifying the expected input format (Markdown with document summaries) and the required output format (JSON matching the BestDocuments schema).
from langchain.chat_models import ChatNVIDIA
from langchain.prompts import ChatPromptTemplate
# Initialize the LLM with desired parameters
llm = ChatNVIDIA(model="mistralai/mistral-small-24b-instruct
", temperature=0, max_tokens=3000)
# Define the prompt template for the document expert
prompt_document_expert = ChatPromptTemplate.from_messages(
[
(
"system",
f""" # Extract Best Document Identifier from list of summaries, based on a question coming from the user. You are an expert in getting insights of a document, based on its summaries and you are able to figure the best matches to the question in terms of the summary of the document.
Provide no more than 3 of these documents. ## Format of the Input - The input is a markdown file containing second level headers (##) with the chapter index in the form ## Document where document_id is an integer pointing to the index of the document. After the document heading there is the summary of the document which is relevant to understand the content of the document. ## Format of the output - The output is going to be the list of the best documents indices and a few of the corresponding summaries that help to answer the question coming from the user. ## Content - Here is the input you can work on:
{{documents_context}}
""",
),
(
"human",
"Can you tell me what are the most relevant document ids for this question: {question}"
),
("human", "Tip: Make sure to answer in the correct format"),
]
)Prepare context
The get_context function prepares the input data by retrieving document summaries and formatting them appropriately.
def get_context(input_data: dict) -> dict:
collection_name = input_data.get("collection_name")
question = input_data.get("question")
documents_context = get_document_summaries_markdown(collection_name)
# print(context)
return {"documents_context": documents_context,
"collection_name": collection_name,
"question": question}Bind the structured output
The llm.with_structured_output(BestDocuments) method instructs the LLM to produce output conforming to the BestDocuments Pydantic model. This method internally handles the parsing and validation of the LLM’s response, ensuring that the output matches the expected structure.
LangChain’s with_structured_output method simplifies the process of binding the model to produce structured outputs. It abstracts the complexity of parsing and validating the LLM’s responses, enabling you to focus on defining the desired output structure and the prompt instructions.
Finally, create a chain to process the input and generate the structured output:
chain_document_expert = (
RunnableLambda(get_context) | prompt_document_expert | llm.with_structured_output(BestDocuments) | (lambda x: x.dict())
)End-to-end tool in action
To get started with the multimodal retrieval system, clone the /NVIDIA/GenerativeAIExamples GitHub repo and follow the Quick Start guide to set up the service. When it’s up and running, open your web browser and navigate to http://localhost:7860 to access the system through the Gradio user interface.
For example, explore how the system processes queries on the NVIDIA Technical Blog. Ask a question about a bar chart showing the NVIDIA H100 GPU performance from one of the posts. The Select Question field is for evaluation purposes, with the Ground Truth Answer field value provided by a human.
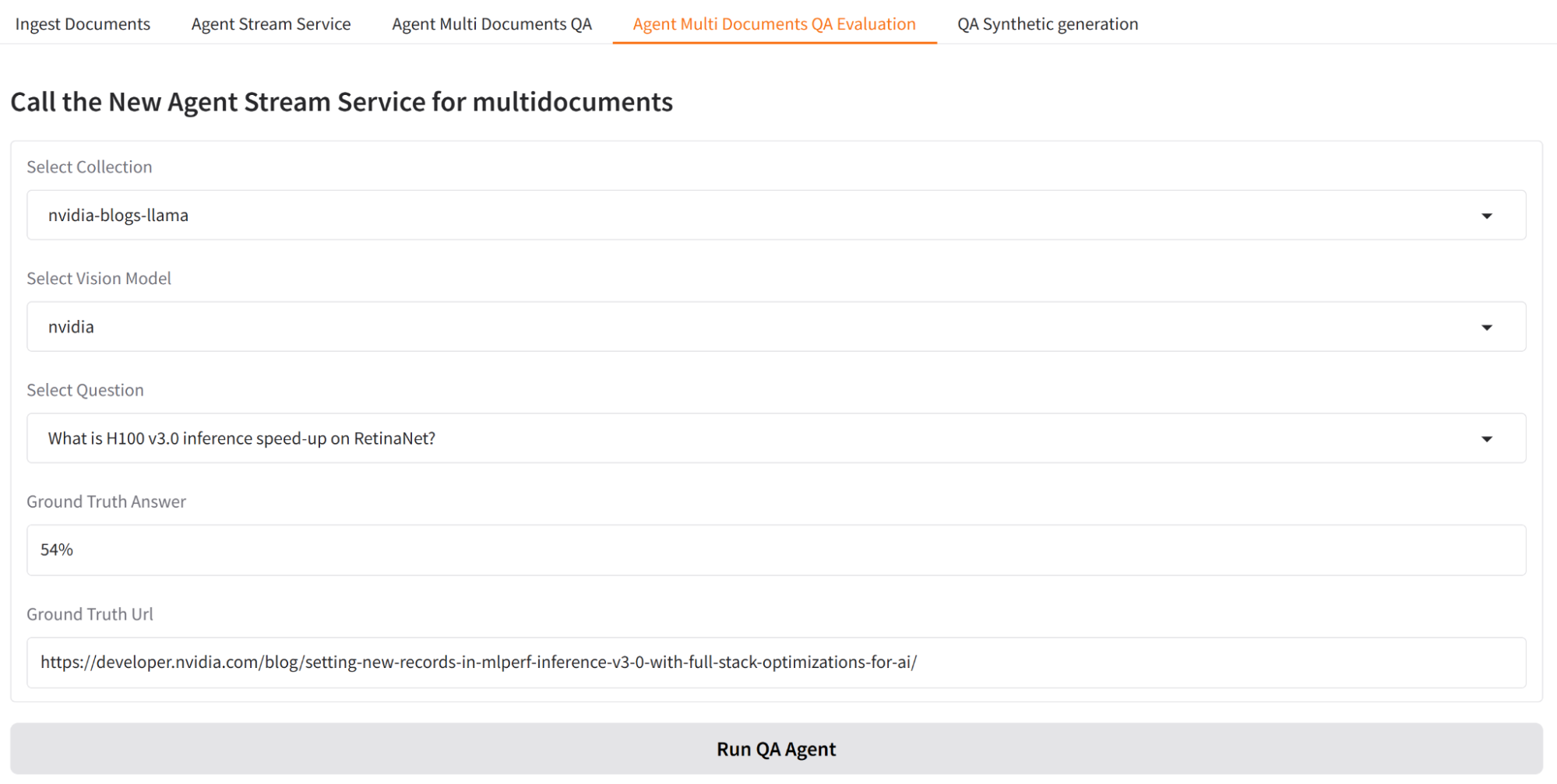 Figure 4. Agent multi-document evaluation
Figure 4. Agent multi-document evaluation
This system generates an accurate answer based on the bar chart and also displays the relevant image for reference, such as the chart showing RetinaNet achieving 54%. This ensures precise answers while enabling users to visually verify the referenced data.
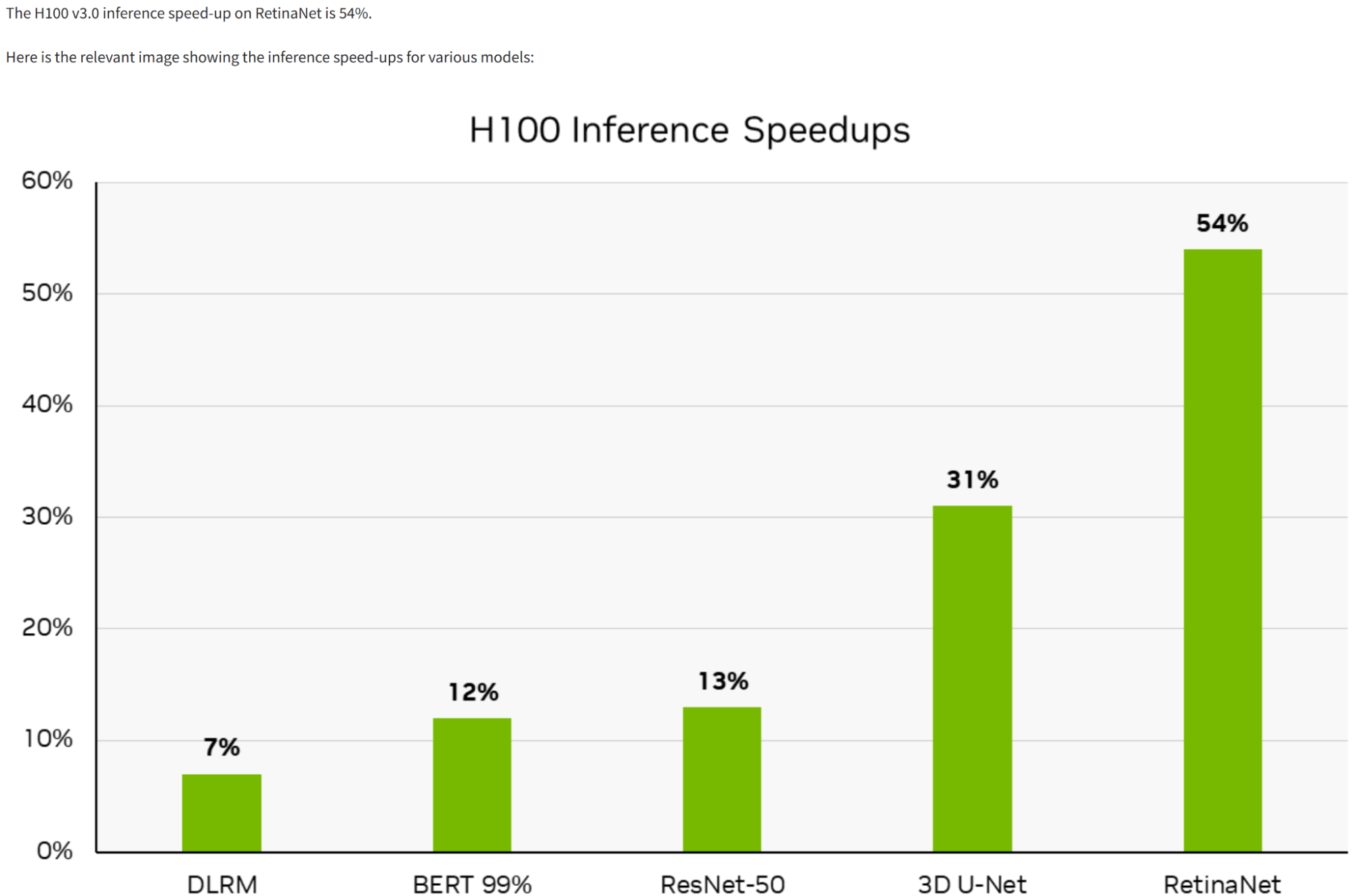 Figure 5. Agent result with source graph for verification
Figure 5. Agent result with source graph for verification
Video 1. How to Insert HTML Documents into a Multimodal Retriever Collection Using NVIDIA NIM
Video 2. How to Search Text and Images Within a Multimodal Retriever Collection Using NVIDIA NIM
Challenges and solutions
As data volumes increase, so does the complexity of processing and retrieving relevant information. Handling large datasets efficiently is essential to maintaining performance and ensuring user satisfaction. In this information retrieval system, the sheer amount of document summaries can exceed the context window of even long-context models, making it challenging to process all summaries in a single prompt.
Processing large volumes of data also demands considerable computational resources, which can result in higher costs and increased latency. Optimizing resource utilization is crucial to delivering fast and accurate responses while minimizing unnecessary expenses.
Hierarchical document reranking solution
To address scalability challenges, we implemented a hierarchical approach in the initial document reranking phase. Instead of processing all document summaries simultaneously, we divided them into manageable batches that fit within the model’s context window. The process involves multiple stages:
- Batch processing: Summaries are grouped into batches that the model can handle without exceeding the prompt size limitations.
- Intermediate reranking: The model evaluates each batch separately, ranking the documents within each group.
- Selection of top candidates: The most relevant documents from each batch are selected to proceed to the next stage.
- Final reranking: The top candidates from all batches are combined and re-evaluated to identify the most relevant document.
Considering both scalability and cost concerns, this hierarchical approach ensures that all documents are considered without exceeding the model’s capacity. It not only improves scalability, but also boosts efficiency by narrowing down the candidate documents systematically until the most relevant one is identified.
Future prospects with smaller models
Using language models, especially those with long-context capabilities, involves processing a large number of tokens, which can incur significant costs. Each token processed adds to the overall expense, making cost management a critical consideration when deploying these systems at scale.
The concern about cost is indeed valid. However, the landscape of language models is rapidly evolving, with smaller models becoming increasingly capable and efficient. As these advancements continue, these smaller models may offer similar performance at a fraction of the cost.
Conclusion
This post discussed the implementation of a simple multimodal information retrieval pipeline that uses NVIDIA NIM and LangGraph. The pipeline offers several advantages over existing information retrieval methods:
- Enhanced comprehension of documents
- A multimodal model to extract information from images, tables, and text
- Seamless integration of external tools
- Generation of consistent and structured output
Using NVIDIA NIM and LangGraph, you can build on this work and customize it to suit specific needs. To get started, you can find source code in the /NVIDIA/GenerativeAIExamples GitHub repo.
NVIDIA NIM also offers access to more models optimized for NVIDIA GPUs. You can explore NVIDIA NeMo, a scalable generative AI framework designed for researchers and PyTorch developers working on LLMs, multimodal models, and more.
If you are working with a large corpora of enterprise data and are looking to develop enterprise-ready, real-time multilingual and cross-lingual information retrieval systems to generate context-aware responses, learn more about NVIDIA NeMo Retriever.
Related resources
- GTC session: How to Build Multimodal Agentic AI Retrieval Systems
- GTC session: Blueprints for Success: Navigating Multimodal Ingestion for Real-World RAG
- GTC session: Vision Language Models at NVIDIA
- NGC Containers: VLM Inference Service (Jetson)
- NGC Containers: Llama-3.2-90B-Vision-Instruct
- NGC Containers: NVIDIA Retrieval QA Mistral 7B Embedding v2
Francesco Ciannella
Senior Engineer, NVIDIA
Maggie Zhang
Senior Solutions Architect, NVIDIA
Daniel Glogowski
Senior Technical Product Manager, Enterprise product group, NVIDIA
Isabel Hulseman
Product Marketing Manager, Enterprise AI software, NVIDIA