
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
This post is the first in a series on Autonomous Driving at Scale, developed with Tata Consultancy Services (TCS). In this post, we provide a general overview of the deep learning inference for object detection.
Autonomous vehicle software development requires data, computation, and algorithmic innovation on a massive scale only achieved by GPUs. An array of neural networks forms a base for the perception and decision-making systems. The neural network performance increases proportionally to the amount of data and requires infrastructure to support training and inference at scale.
For autonomous vehicles (AV) to reach acceptable levels of safety, they must be trained on massive amounts of real-world driving data encompassing the diversity of situations that a car could encounter daily. These training scenarios are collected by fleets of vehicles fitted with multiple sensors driving hours each day, generating petabytes of data. This data must then be annotated and processed for comprehensive AV development, testing, and validation.
A large part of AV software is the perception stack that enables the vehicle to detect, track, and classify objects and to estimate distances. A perception algorithm developer can create high performance and robust algorithms that are capable of accurately detecting other vehicles, lanes, static and moving objects, pedestrians, traffic lights at crossings, and intersections in any scenario. The scenarios include various ambient conditions, including inside a tunnel, on a pitch-dark highway, or in glaring sunlight. For these algorithms to work effectively, they need a steady influx of high-quality, annotated or labeled data to train.
In the case of object detection, the goal is not only to detect objects in a single frame but also to determine the location of the objects in the frame. The objects need to be identified, classified, and labeled in the right classes. You can achieve these objectives through a bounding box, which not only identifies the object but also determines the location of the object along with a confidence score.
Traditionally, annotation or labeling has mostly been considered a manual task. However, AI can accelerate the data labeling process. An AI model can generate pre-annotations, which are then reviewed and augmented by human annotators to improve accuracy and create a high-quality training dataset.
Object detection inference pipeline components
GPUs are powering autonomous vehicle software development driven by the scale of data, the scale of computation, and algorithmic innovation. An array of neural networks form a base for the perception and decision making systems. The neural network performance increases proportional to the amount of data and requires infrastructure to support training and inference at scale.
- Dataset
- Data schema
- System configuration
Dataset
Figure 1 shows the details for a dataset of 23 drive sessions in different scenarios for inference.

Figure 1. Dataset distribution.
In addition to the variation in environmental elements and the principal objects for detection, the following tables show the attributes set for the camera used in the ego vehicle and scene.
| Attribute | Value |
| Image resolution captured by the camera | 1280×720 |
| Frame rate of the camera used | 30 FPS |
Table 1. Camera sensor attributes.
| Attribute | Value |
| Ego Vehicle Sensor Suite | 1xFront Camera |
| Infrastructure Elements used in the scenes | Buildings, Roads, Vegetation, Vehicles (Stationary and moving), Pedestrians, Signposts, Traffic Lights, Street Lights |
| Total Duration of the Drive Session | 51 mins |
Table 2. Scene attributes.
Data schema
The dataset is time-stamped and contains raw data from the camera sensor, calibration values, pose trajectory, and ground truth pose. The ground truth data enables the validation of object detection inference output and aids in the interpretation and analysis of the metrics collected.
The data schema gives you information regarding the format and structure of the ground truth data. The data objectively tells you the information about the object localization and categorization. It contains the exact coordinates of the objects, along with its category for each image in the given dataset.
For this post, you are interested in detecting specific objects.
| Static_Fixed/Dynamic/Movable | Object Class |
| Dynamic | Vehicle.Car |
| Dynamic | Vehicle.Truck |
| Dynamic | Vehicle.Bus |
| Static | Object.Trafficlight |
| Dynamic | Human.Pedestrian |
| Static | Object.TrafficSign |
Table 3. Object ontology.
Figure 2 shows the structure of the ground truth file.

Figure 2. Ground truth structure.

Figure 3. Ground truth JSON for different object types.
System configuration
The configuration in Table 4 runs deep learning inference on a single CPU and one or more GPUs.
| Cloud/VM Size | Azure/Standard_NC24s_v3 |
| Operating System | Ubuntu 18.04 |
| No of vCPUs/CPU type | 24/Intel Xeon E5-2690 v4 (Broadwell) |
| Memory: GiB (DDR4)/Temp storage (SSD) GiB | 448/2948 |
| No of GPU/GPU type | 4/NVIDIA Tesla V100-PCIE |
| GPU memory: GiB | 64 |
| Max data disks/Max NICs | 32/8 |
| Max uncached disk throughput: IOPS/MBps | 80000/800 |
| GPU driver/CUDA version | 440.64.0/10.2 |
| python/OpenCV-python versions | 3.6.9/3.4.1 |
| PyTorch version | 1.5.0 |
| NGC Container | nvcr.io/nvidia/pytorch:20.03-py3 |
Table 4. System configuration.
Pre-annotation using YOLOv3
Deep learning is the state-of-the-art method to perform object detection primarily driven by data availability and computational scale. Many other details, such as neural network architecture, are also important and there has been much innovation over the last few years.
There are quite a few models that have pushed the envelope for object detection, such as Faster-Region Based Convolutional Neural Network (Faster-RCNN), You Only Look Once model (YOLO), and Single Shot MultiBox Detector (SSD). There is no straight answer on which model is the best. For pre-annotation object detection needs, you make choices to balance accuracy and speed.
For this post, we chose the YOLOv3 algorithm, which is one of the most effective object detection algorithms. It also encompasses many of the best ideas across the entire computer vision literature that relate to object detection. Darknet-53 serves as the backbone for YOLOv3, which takes an image as the input and extracts the feature map. YOLOv3 is a multiclass object detection model, a single-stage detector that reduces latency.
Figure 4 depicts the architecture of the YOLOv3 algorithm. The detection layer contains many regression and classification optimizers, and the number of anchor boxes determines the number of layers used to detect the objects directly. It is a single neural network that predicts bounding boxes and class probabilities from full images in one evaluation. Because the whole detection pipeline is a single network, it can be optimized end-to-end based on the detection performance.
Figure 4 shows that YOLO v3 makes predictions at three scales. The 13×13 layer is responsible for detecting large objects, the 26×26 layer detects medium objects, and the 52×52 layer detects smaller objects.
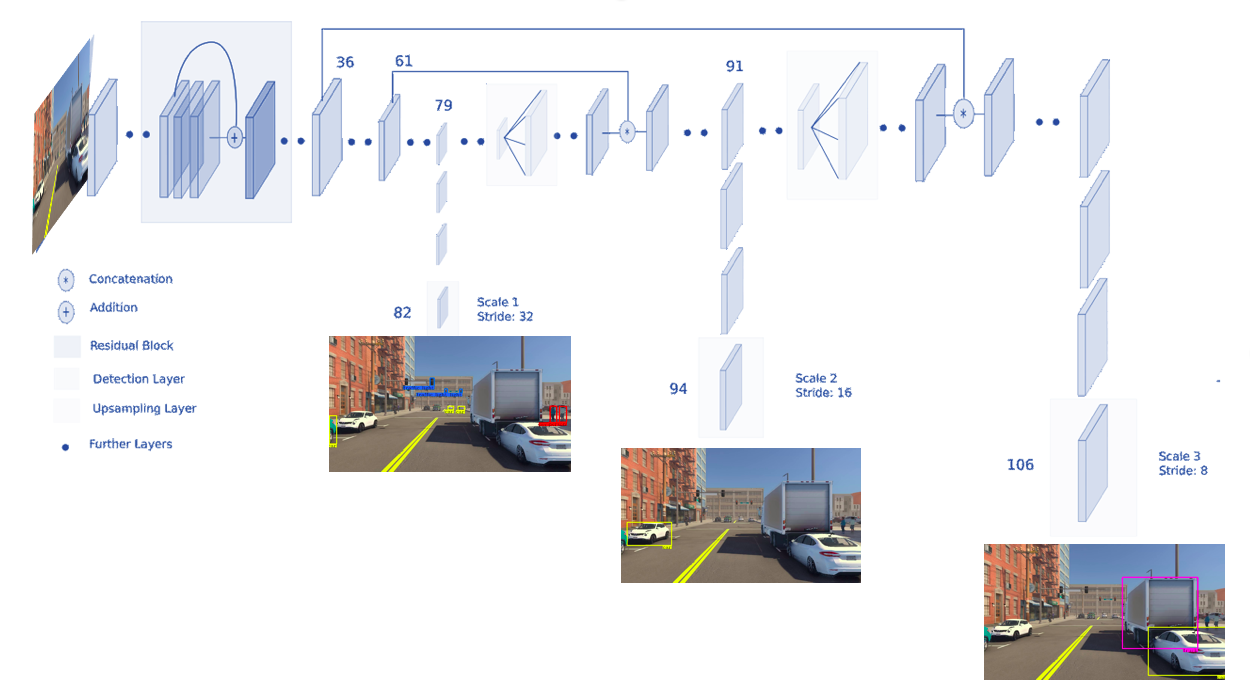
Figure 4. YOLOv3 network architecture.
Object detection inference pipeline overview
The pre-annotation model lies at the heart of the object detection inference pipeline. A pretrained YOLOv3-416 model with a mAP (mean average precision) of 55.3, measured at 0.5 IOU on the MS COCO test-dev, is used to perform the inference on the dataset. Download the config and the pretrained weight file from the PyTorch-YOLOv3 GitHub repo. Use the PyTorch neural network framework for inferencing. Use Docker containers to set up the environment and package them for distribution to run in different environments.
After import, the dataset hits the pre-processing stage for necessary transformations. The aspect ratio of the 1280×720 images in the dataset is maintained. The images are resized to 416×234 and padded to 416×416, and then inserted into the 416×416 network. All images of fixed height and width make it amenable to process the images in batches. Images in batches can be processed in parallel by the GPU, leading to speed boosts.
The pre-annotation models cover the straightforward annotations automatically, simplifying the job of human annotators by making it less intensive. Pre-annotation helps bootstrap the human annotation process. The subsequent steps are iterative, involving one or more rounds of quality checks. The deep learning–based pre-annotators progressively get better over time by continuously learning from the collection of vetted annotations by human annotators.
An efficient object detection inference pipeline goes a long way in driving consistent and high-quality labeled output.
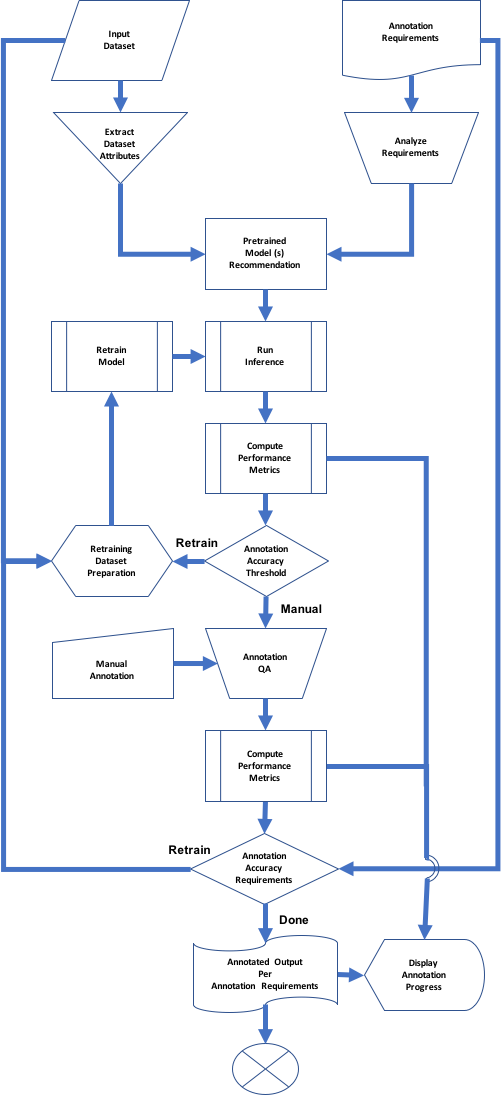
Figure 5. Annotation pipeline template.
Summary
Autonomous vehicles promise to deliver safer, more efficient transportation for all. Accurate detection of objects, including vehicles, pedestrians, traffic signs, and traffic lights, could assist self-driving cars to drive as safely as humans. The annotation of large volumes and a variety of drive session data are necessary to train and build state-of-the-art detection systems.
This post covered the components of building an end-to-end object detection pipeline running on GPUs. Stay tuned for more posts covering the typical challenges when working with annotating real-world, autonomous vehicle data.
Tata Consultancy Services
Tata Consultancy Services (TCS) is an IT services, consulting and business solutions organization that has partnered with many of the world’s largest businesses in their transformation journeys for the last 50 years. TCS offers a consulting-led, cognitive- powered, integrated portfolio of IT, business and technology services, and engineering. This is delivered through its unique Location Independent Agile delivery model, recognized as a benchmark of excellence in software development. TCS has more than 448,000 employees in 46 countries with $22 billion in revenues as of March 31, 2020.
TCS Automotive Industry Group focuses on delivering solutions and services to address the CASE ( Connected, Autonomous, Shared and Electric) ecosystem and partners with industry-leading players to address the opportunities evolving from disruption in the automotive industry.
To stay up-to-date on TCS news in North America, follow us on Twitter @TCS_NA and LinkedIn @Tata Consultancy Services – North America. For TCS global news, follow @TCS_News.
Sanjay Dulepet
Global Head of Product Development, Technology Leader, TCS
Pallab Maji
Machine Learning Senior Solutions Architect, NVIDIA
Manish Harsh
Global Developer Relations Manager for Autonomous Vehicles, NVIDIA
Katie Burke
Automotive Content Marketing Manager, NVIDIA