
The just-released NVIDIA Jetson AGX Orin raised the bar for AI at the edge, adding to our overall top rankings in the latest industry inference benchmarks.
In its debut in the industry MLPerf benchmarks, NVIDIA Orin, a low-power system-on-chip based on the NVIDIA Ampere architecture, set new records in AI inference, raising the bar in per-accelerator performance at the edge.
Overall, NVIDIA with its partners continued to show the highest performance and broadest ecosystem for running all machine-learning workloads and scenarios in this fifth round of the industry metric for production AI.
In edge AI, a pre-production version of our NVIDIA Orin led in five of six performance tests. It ran up to 5x faster than our previous generation Jetson AGX Xavier, while delivering an average of 2x better energy efficiency.
NVIDIA Orin is available today in the NVIDIA Jetson AGX Orin developer kit for robotics and autonomous systems. More than 6,000 customers including Amazon Web Services, John Deere, Komatsu, Medtronic and Microsoft Azure use the NVIDIA Jetson platform for AI inference or other tasks.
It’s also a key component of our NVIDIA Hyperion platform for autonomous vehicles. China’s largest EV maker. BYD, is the latest automaker to announce it will use the Orin-based DRIVE Hyperion architecture for their next-generation automated EV fleets.
Orin is also a key ingredient in NVIDIA Clara Holoscan for medical devices, a platform system makers and researchers are using to develop next generation AI instruments.
Small Module, Big Stack
Servers and devices with NVIDIA GPUs including Jetson AGX Orin were the only edge accelerators to run all six MLPerf benchmarks.
With its JetPack SDK, Orin runs the full NVIDIA AI platform, a software stack already proven in the data center and the cloud. And it’s backed by a million developers using the NVIDIA Jetson platform.
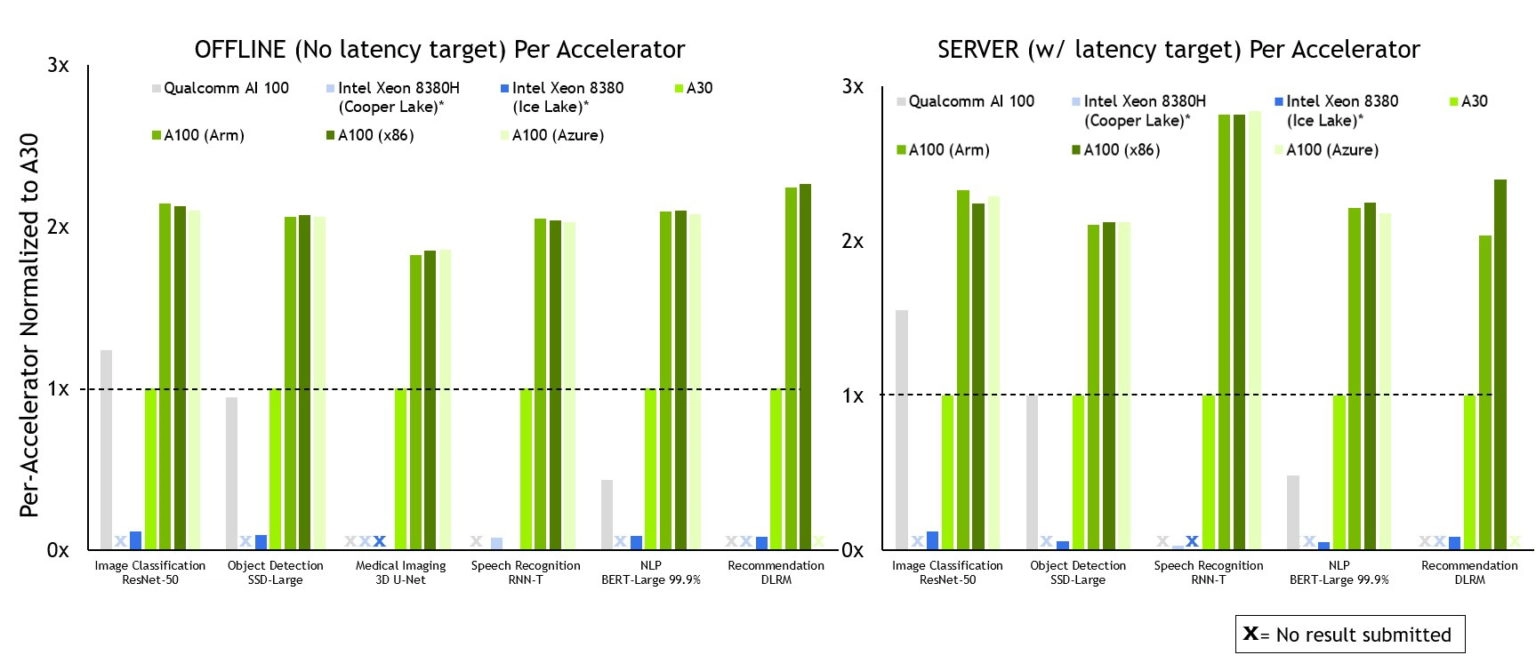
NVIDIA leads across the board in per-accelerator inference performance and is the only company to submit on all workloads.
Footnote: MLPerf v2.0 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline and Server. Qualcomm AI 100: 2.0-130, Intel Xeon 8380 from MLPerf v.1.1 submission: 1.1-023 and 1.1-024, Intel Xeon 8380H 1.1-026, NVIDIA A30: 2.0-090, NVIDIA A100 (Arm): 2.0-077, NVIDIA A100 (X86): 2.0-094.
MLPerf name and logo are trademarks. See www.mlcommons.org for more information.
NVIDIA and partners continue to show leading performance across all tests and scenarios in the latest MLPerf inference round.
The MLPerf benchmarks enjoy broad backing from organizations including Amazon, Arm, Baidu, Dell Technologies, Facebook, Google, Harvard, Intel, Lenovo, Microsoft, Stanford and the University of Toronto.
Most Partners, Submissions
The NVIDIA AI platform again attracted the largest number of MLPerf submissions from the broadest ecosystem of partners.
Azure followed up its solid December debut on MLPerf training tests with strong results in this round on AI inference, both using NVIDIA A100 Tensor Core GPUs. Azure’s ND96amsr_A100_v4 instance matched our highest performing eight-GPU submissions in nearly every inference test, demonstrating the power that’s readily available from the public cloud.
System makers ASUS and H3C made their MLPerf debut in this round with submissions using the NVIDIA AI platform. They joined returning system makers Dell Technologies, Fujitsu, GIGABYTE, Inspur, Lenovo, Nettrix, and Supermicro that submitted results on more than two dozen NVIDIA-Certified Systems.
Why MLPerf Matters
Our partners participate in MLPerf because they know it’s a valuable tool for customers evaluating AI platforms and vendors.
MLPerf’s diverse tests cover today’s most popular AI workloads and scenarios. That gives users confidence the benchmarks will reflect performance they can expect across the spectrum of their jobs.
Software Makes It Shine
All the software we used for our tests is available from the MLPerf repository.
Two key components that enabled our inference results — NVIDIA TensorRT for optimizing AI models and NVIDIA Triton Inference Server for deploying them efficiently — are available free on NGC, our catalog of GPU-optimized software.
Organizations around the world are embracing Triton, including cloud service providers such as Amazon and Microsoft.
We continuously fold all our optimizations into containers available on NGC. That way every user can get started putting AI into production with leading performance.
Dave Salvator
Senior Product Marketing Manager, Tesla Group, NVIDIA