This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
To run neural networks efficiently at the edge on mobile, IoT, and other embedded devices, developers strive to optimize their machine learning (ML) models’ size and complexity while taking advantage of hardware acceleration for inference. For these types of devices, long battery life and thermal control are essential, and performance is often measured on a per-watt basis. Optimized ML models can help achieve these goals by reducing computations, memory traffic, latency, and storage requirements while making more efficient use of the hardware.
In this blog post, we take a closer look at ML model optimization techniques and how solutions from Qualcomm Technologies and Qualcomm Innovation Center can help developers implement them.
State-of-the-Art Model Optimization
While developers put a lot of effort into a model’s design, they can also employ the following optimization techniques to reduce a model’s size and complexity:
- Quantization: reduces the number of bits used to represent a model’s weights and activations (e.g., reducing weights from 32-bit floating point values to 8-bit integers).
- Compression: removes redundant parameters or computations with little or no influence on predictions.
The key to success with these optimization techniques is implementing them without significantly affecting the model’s predictive performance. In practice, this is often done by hand through a lot of trial and error. This typically involves iterating on model optimizations, testing the model’s predictive and runtime performance, and then repeating the process to compare the results against past tests.
Given its importance on mobile, ML model optimization is an area where we continue to do extensive research. Traditionally, we’ve shared our breakthroughs via conference papers and workshops, but for these optimization techniques, we decided to increase accessibility by releasing our AI Model Efficiency Toolkit (AIMET). AIMET provides a collection of advanced model compression and quantization techniques for trained neural network models.
AIMET supports many features, such as Adaptive Rounding (AdaRound) and Channel Pruning, and the results speak for themselves. For example, AIMET’s data-free quantization (DFQ) algorithm quantizes 32-bit weights to 8-bits with negligible loss in accuracy. AIMET’s AdaRound provides state-of-the-art post-training quantization for 8-bit and 4-bit models, with accuracy very close to the original FP32 performance. AIMET’s spatial SVD plus channel pruning is another impressive example because it achieves a 50% MAC (multiply-accumulate) reduction while retaining accuracy within 1% of the original uncompressed model.
In May 2020, our Qualcomm Innovation Center (QuIC) open-sourced AIMET. This allows for collaboration with other ML researchers to continually improve model efficiency techniques that benefit the ML community.
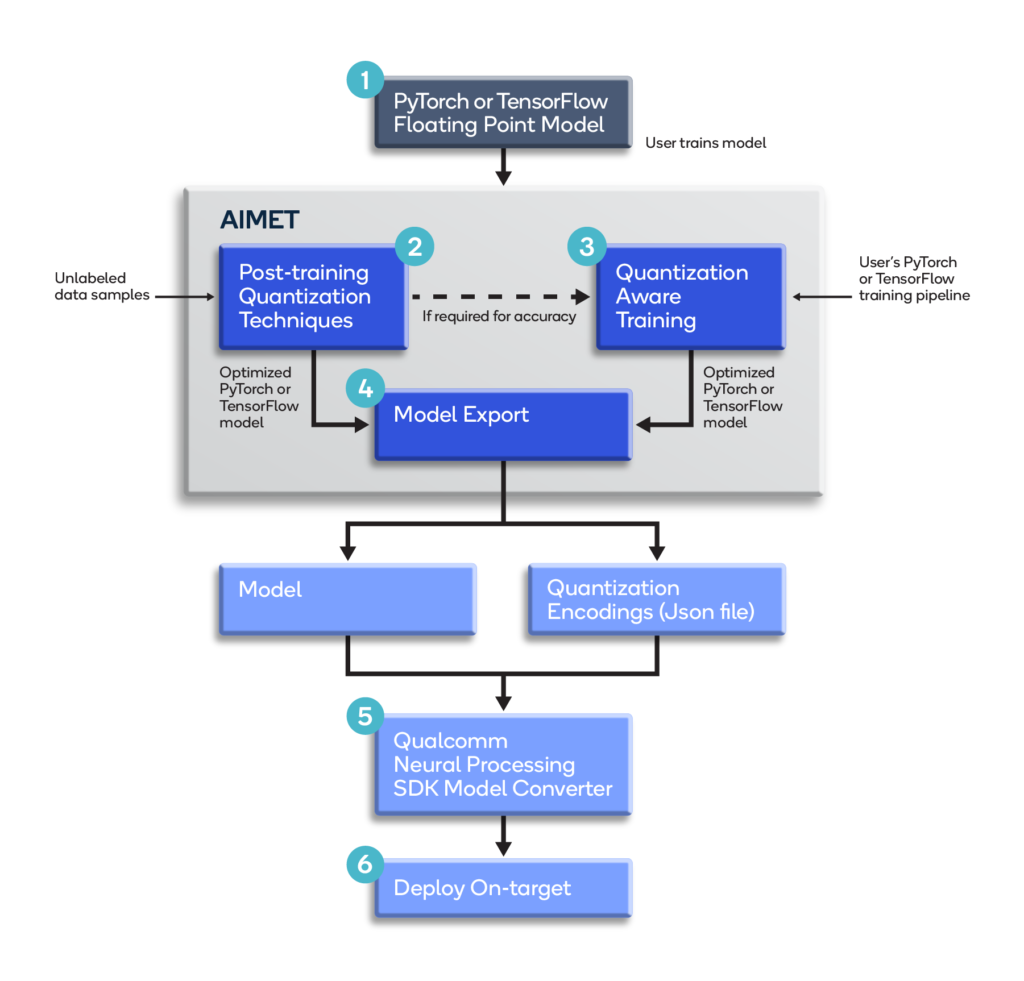
Figure 1 shows how AIMET fits into a typical ML model optimization pipeline:
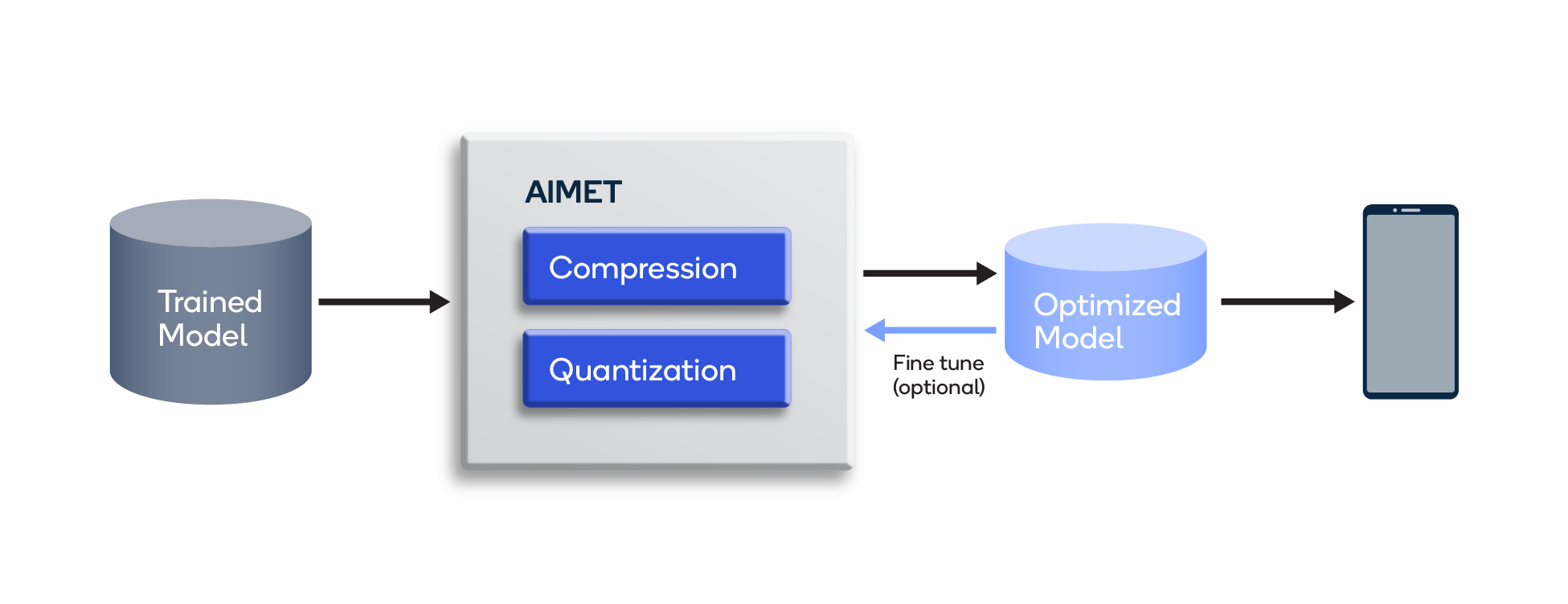
Figure 1 – Overview of AIMET in an ML model optimization pipeline.
Using AIMET, developers can incorporate its advanced model compression and quantization algorithms into their PyTorch and TensorFlow model-building pipelines for automated post-training optimization, as well as for model fine-tuning, if required. Automating these algorithms helps eliminate the need for hand-optimizing neural networks that can be time consuming, error prone, and difficult to repeat.
AIMET and Snapdragon
Developers building ML solutions for devices powered by Snapdragon® mobile platforms often use the Qualcomm® Neural Processing SDK. This SDK provides a workflow to convert models (e.g., exported TensorFlow models) to our DLC format for optimal execution on the SoC’s Qualcomm® AI Engine.
By incorporating AIMET to perform optimization much earlier in the model-building pipelines, developers can evaluate model optimizations prior to conversion to DLC. Doing so can help reduce iterations during deployment. It also allows developers to try out the rich set of algorithms made available by AIMET.
A user can compress a model with AIMET as described in the AIMET Model Compression topic in the AIMET user guide. AIMET’s Spatial Singular Value Decomposition (SVD) and Channel Pruning (CP) techniques can compress a model based on a user-configured compression ratio.
Quantization Workflow
Prior to exporting a model to the target Snapdragon hardware, AIMET can be used to optimize the model for quantized accuracy as shown in Figure 2:
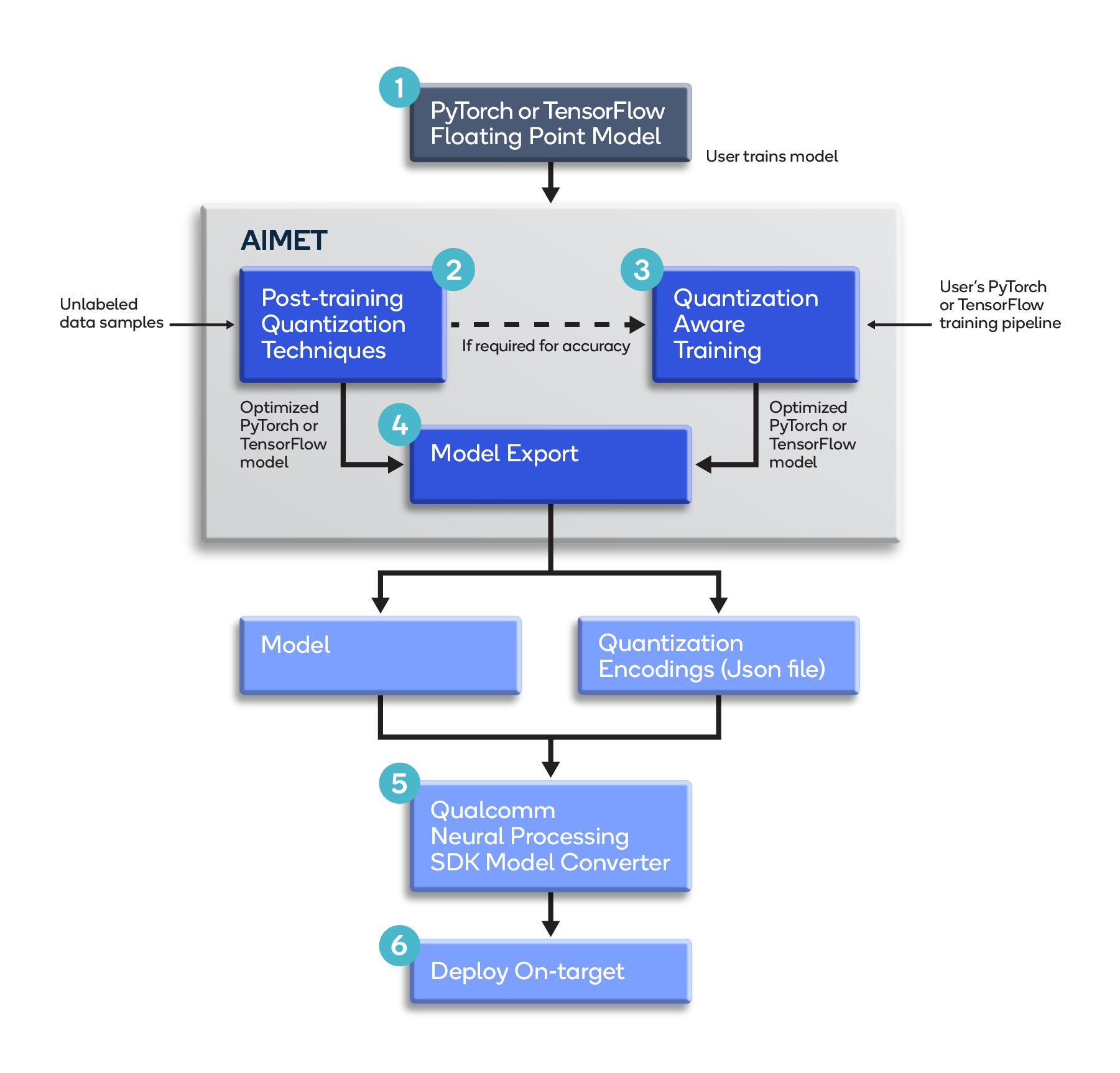
Figure 2 – AIMET quantization workflow
The following are the main steps of this workflow:
- The model is trained using PyTorch or TensorFlow with standard 32-bit floating-point (FP32) weights.
- The user optimizes the model for quantization using AIMET’s built-in post-training quantization techniques. Post-training techniques like Cross-Layer Equalization (CLE) and AdaRound can be used without labeled data and can provide good performance for several models without requiring model fine-tuning, thus avoiding the time and effort for hyper-parameter tuning and training. Using quantization simulation, AIMET evaluates model accuracy which gives an estimate of performance expected when running quantized inference on the target.
- The user (optionally) fine-tunes the model using AIMET’s Quantization-Aware Training feature to further improve quantization performance by simulating quantization noise and adapting model parameters to combat this noise.
- The optimized model is exported as a typical FP32 TensorFlow or PyTorch/ONNX model, along with a JSON file containing recommended quantization encodings.
- The outputs from Step 4 are fed to the model conversion tool in the Qualcomm Neural Processing SDK. This converts the model to Qualcomm Technologies’ DLC format, using the quantization encodings generated by AIMET, for optimal execution on the SoC’s Qualcomm AI Engine.
- The converted (DLC) model is deployed on the target hardware.
Conclusion
AIMET allows developers to utilize cutting-edge neural network optimizations to improve the run-time performance of a model without sacrificing much accuracy. Its rich collection of state-of-the-art optimization algorithms removes a developer’s need to optimize manually and, thanks to open-sourcing the algorithms, are sure to be continually improved.
To get up to speed with quantization using AIMET, check out the AIMET GitHub page and also the Model Zoo for AI Model Efficiency Toolkit. The AIMET Model Zoo contains a collection of popular neural networks and a set of scripts to help developers quantize models with AIMET and compare results.
For additional information about AIMET, be sure to check out the following resources:
- QuIC AIMET overview page – includes an overview, videos, and links to AIMET’s user guide and API documentation
- Intelligence at scale through AI model efficiency – a presentation that includes an overview of AIMET
- What’s new with our AI Open Source: AIMET enhancements and code from papers
- Open sourcing the AI Model Efficiency Toolkit
- AIMET Model Zoo: Highly accurate quantized AI models are now available
We also have a number of blogs that discuss the Qualcomm Neural Processing SDK and ML modeling:
- On-device AI with Developer-Ready Software Stacks
- Exploring Different Types of Neural Networks
- AI Machine Learning Algorithms – How a Neural Network Works
- From Training to Inference: A Closer Look at TensorFlow
Related Blogs:
- Key Insights from Microsoft Build 2022
- Cloud Connectivity Planning Considerations for IoT Edge Devices
- Smart Sensors II – How Adding AI Can Predict the Future for IIoT
- Embedded IoT Device Protection: Physical Protection for the Real World
- Building Innovative MedTech with Innominds’ iMedVision (iDhi) Platform
Felix Baum
Director of Product Management, Qualcomm Technologies