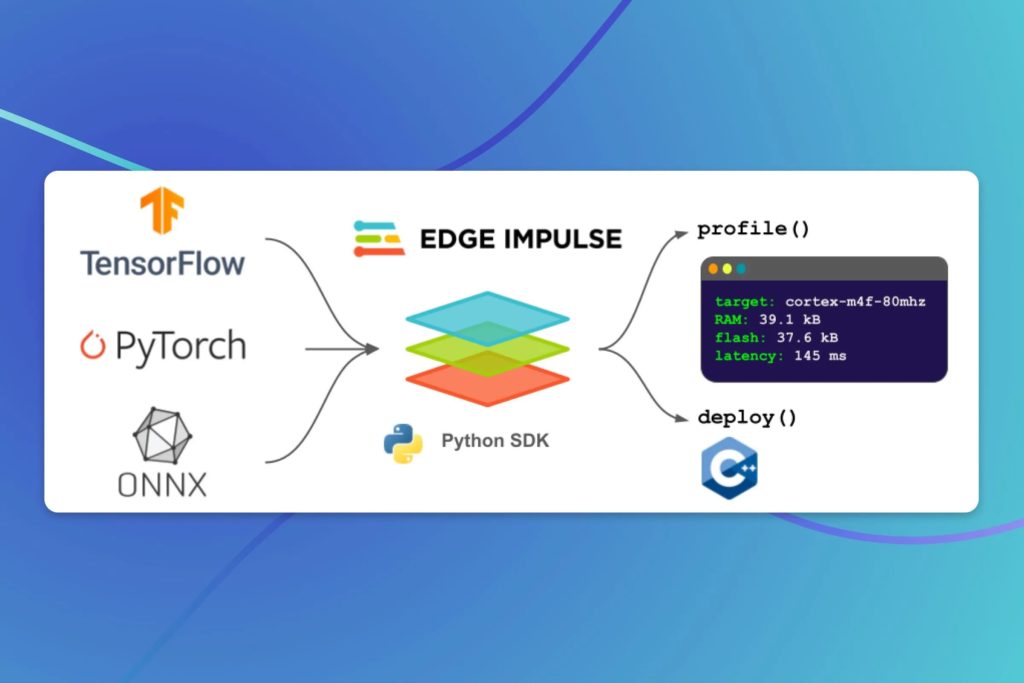
We launched Edge Impulse to help developers and companies embed data-driven machine learning algorithms into physical devices, bridging the gap between technology and real life. I’m in awe every day of the incredible products our customers are building — like Oura, who are improving lives with best-in-class sleep tracking, and Advantech, who have unlocked extreme productivity increases at their manufacturing plant.
We started our journey by building tools for embedded engineers, enabling them to work with ML while staying focused on their craft. But over four years, we’ve noticed something exciting. At the companies we work with, our product has been more than a tool for embedded engineers. It’s become wildly popular with ML experts, too.
At many companies, ML practitioners are the champions of bringing AI to the edge: building datasets, training models, and working with embedded teams to deploy them. ML experts understand the potential of machine learning to transform the way that humans and computers work together. But they have a different set of needs to the embedded teams they support.
Today, we’re launching a whole new way to use Edge Impulse. Built with ML experts in mind, it’s designed to help practitioners feel incredibly productive with edge AI: to take their existing skills and workflows and apply them to an entirely new domain — hardware — while working confidently next to embedded engineers.
Meet `edgeimpulse`, our Python SDK, available today on PyPI:
$ pip install edgeimpulse
import edgeimpulse as ei
Designed by our ML team, based on tools we built to solve our own problems, `edgeimpulse` is a toolbox of essential functions for anyone deploying models to the edge. It supports a new set of capabilities we call Bring Your Own Model (BYOM), which help you optimize and deploy any model you’ve trained, no matter where.
Edge Impulse has always been known for its fantastic user interface, but ML practitioners — like us — live in Python. We sketch out ideas in notebooks, build data pipelines and training scripts, and integrate with a vibrant ecosystem of Python tools. The Edge Impulse SDK is designed to be one of them. It’s built to work seamlessly with the tools you already know. It feels familiar and obvious, but also magical.
Here are a couple of its key features.
Key features of Edge Impulse’s Python SDK
Profile a deep learning model for inference on embedded hardware
If you pass in almost any model, `ei.profile()` will show you how it performs on a wide range of embedded processors:
> results = ei.model.profile(model='/home/tiny-model',
device='cortex-m4f-80mhz')
> results.summary()
Target results for float32:
===========================
{ 'device': 'cortex-m4f-80mhz',
'tfliteFileSizeBytes': 3364,
'isSupportedOnMcu': True,
'memory': { 'tflite': {'ram': 2894, 'rom': 33560, 'arenaSize': 2694},
'eon': {'ram': 1832, 'rom': 11152}},
'timePerInferenceMs': 1}
If you’re still searching for the right hardware, you can get a summary of performance across every device type:
> results = ei.model.profile(model='/home/tiny-model')
> results.summary()
Performance on device types:
============================
{ 'variant': 'float32',
'lowEndMcu': {
'description': 'Estimate for a Cortex-M0+ or similar, '
'running at 40MHz',
'timePerInferenceMs': 4,
'memory': { 'tflite': {'ram': 2824, 'rom': 29128},
'eon': {'ram': 1784, 'rom': 11088}},
'supported': True},
'highEndMcu': {
'description': 'Estimate for a Cortex-M7 or other '
'high-end MCU/DSP, running at 240MHz',
'timePerInferenceMs': 2,
'memory': { 'tflite': {'ram': 2894, 'rom': 33560},
'eon': {'ram': 1832, 'rom': 11152}},
'supported': True},
'highEndMcuPlusAccelerator': {
'description': 'Estimate for an MCU plus neural network '
'accelerator',
'timePerInferenceMs': 1,
'memory': { 'tflite': { 'ram': 2894, 'rom': 33560},
'eon': { 'ram': 1832, 'rom': 11152}},
'supported': True},
'mpu': {
'description': 'Estimate for a Cortex-A72, x86 or other '
'mid-range microprocessor running at 1.5GHz',
'timePerInferenceMs': 1,
'rom': 3364.0,
'supported': True},
'gpuOrMpuAccelerator': {
'description': 'Estimate for a GPU or high-end '
'neural network accelerator',
'timePerInferenceMs': 1,
'rom': 3364.0,
'supported': True}
}
We’ve built `ei.profile()` to fit great into your iterative workflow, when you’re developing models for embedded and you need to know if an architecture will fit. We support TensorFlow, TFLite, and ONNX, so you can profile models trained in nearly any framework:
> keras_model = tf.keras.Sequential()
> …
> results = ei.profile(model=keras_model)
> results = ei.profile(model='heart_rate.tflite')
> results = ei.profile(model='heart_rate.onnx')
If your model will not run well on the target you’ve selected, we’ll provide the information you need to understand why: whether it’s operator support, memory, latency, or another design constraint.
You can also use the output to drive automation. You can add it to your objective function for hyperparameter optimization, or log the results to your favorite experiment tracker, like Weights & Biases:
# Profile model on target device
results = ei.model.profile(model=keras_model,
device='cortex-m4f-80mhz')
# Log profiling results to W&B alongside your usual metrics
wandb.log({
'test_loss': test_loss,
'test_accuracy': test_accuracy,
'profile_ram': results.memory.tflite.ram,
'profile_rom': results.memory.tflite.rom,
'inference_time_ms': results.time_per_inference_ms
})
Deploy a deep learning model to embedded C++
Once you have a model that works, `ei.deploy()` will help you run inference on-device. It’s a single call to generate portable, readable C++ code, optimized for low latency and memory use, and compatible with nearly any device:
import edgeimpulse as ei
from ei.model.output_type import Classification
ei.deploy(model=model,
model_output_type=Classification(),
output_directory='library')
Powered by Edge Impulse’s deployment engine, `ei.deploy()` lets you skip the headache of working with complex vendor model conversion toolchains — and gets better results. You can deploy to any target with a single line of code. You can work directly with your embedded team, giving them readable C++ code, not proprietary model files.
It takes one function call to make your model smaller and more efficient. Perform 8-bit quantization to achieve 4x smaller size and lightning-fast integer math, and run our award-winning EON Compiler for even higher efficiency compared to industry standard frameworks:
ei.deploy(model=model,
model_output_type=Classification(),
representative_data_for_quantization=data_sample,
engine='tflite-eon',
output_directory='library')
As part of our Python SDK, `ei.deploy()` will easily integrate with your team’s automated ML pipeline and continuous integration tools, so that your latest, greatest model is always available as C++. And for many popular development boards, you can download pre-built firmware that lets you test your model immediately.
Building for real teams
Our new Python SDK is designed to help simplify common tasks that fit into your edge AI workflow. All of the Bring Your Own Model functionality is also available via our famously easy web interface, so that everyone on your team can self-serve. And in combination with our Python API bindings, Node.js SDK, and CLI, every single feature of Edge Impulse is exposed for interactive computing and scripting.
We’ve been using these tools internally at Edge Impulse, and it’s unbelievable how simple they make on-device development. With the SDK in your Python environment, you can completely close the feedback loop between model architecture and embedded deployment, so you’ll never find out at the last minute that your model doesn’t fit.
Our `ei.profile()` and `ei.deploy()` are not the only features planned for our Python SDK. We’ll be adding more tools that integrate with your current workflows to reduce the biggest pain points in embedded ML — such as dataset management and feature engineering for sensor data.
Our product is part of an incredible ecosystem of practical ML tools, and we’re excited to share feedback from some of our partners:
- “At Weights & Biases, we have an ever-increasing user base of ML practitioners interested in solving problems at the edge. With the new Edge Impulse SDK, our users have a new option to explore different model architectures, track on-device model performance across their experiments, and obtain a library they can deploy and manage on the edge.” – Seann Gardiner, VP, Business Development & International, Weights & Biases
- “Hyfe leverages Edge Impulse’s platform to deploy our market-leading AI model for cough detection to the edge, facilitating real-time and efficient monitoring of respiratory health.” – Paul Rieger, Co-Founder, Hyfe
How to get started
In usual Edge Impulse style, we’ve built a ton of documentation and examples that can help you get started with our Python SDK. Here are some of the highlights:
- Overview and getting started with the Python SDK
- Tutorial demonstrating how to train a model and use the Python SDK to profile and deploy
- Python SDK reference guide
We can’t wait to see what you build with this stuff. Give it a try, and visit us on the forum to let us know what you think!
Daniel Situnayake
Head of Machine Learning, Edge Impulse