This blog post was originally published at Plumerai’s website. It is reprinted here with the permission of Plumerai.
New results show Plumerai leads performance on all Cortex-M platforms, now also on M0/M0+
Last year we presented our MLPerf Tiny 0.7 and MLPerf Tiny 1.0 benchmark scores, showing that our inference engine runs your AI models faster than any other tool. Today, MLPerf released new Tiny 1.1 scores and Plumerai has done it again: we still lead the performance charts. A faster inference engine means that you can run larger and more accurate AI models, go into sleep mode earlier to save power, and/or run AI models on smaller and lower cost hardware.
The Plumerai Inference Engine compiles any AI model into an optimized library and runtime that executes that model on a CPU. Our inference engine executes the AI model as-is: it does no additional quantization, no binarization, no pruning, and no model compression. Therefore, there is no accuracy loss. The AI model simply runs faster than other solutions and has a smaller memory footprint. We license the Plumerai Inference Engine to semiconductor manufacturers such that they can include it in their SDK and make it available to their customers. In addition, we license the Plumerai Inference Engine directly to AI software developers.
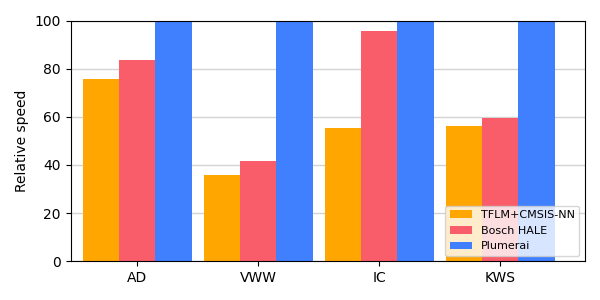
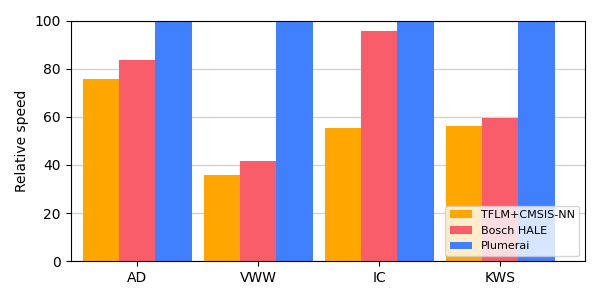
Here’s the overview of the MLPerf Tiny 1.1 results for the STM32 Nucleo-L4R5ZI board with an Arm Cortex-M4 CPU running at 120MHz:
MLPerf Tiny v1.1 results on Nucleo-L4R5ZI (Arm Cortex-M4). The y-axis shows the relative speed [higher is better] of the different solutions compared to the best result, measured in percentage (0 till 100%). The x-axis shows the 4 official MLPerf Tiny benchmarks: Anomaly Detection (AD), Visual Wake Words (VWW), Image Classification (IC), and Keyword Spotting (KWS).
For comparison purposes, we also included TensorFlow Lite for Microcontrollers (TFLM) with Arm’s CMSIS-NN in orange, although this is not part of the official MLPerf Tiny results. To be clear: all results in the above graph compare inference engine software-only solutions. The same models run on the same hardware with the same model accuracy.
Since MLPerf Tiny 1.0, we have also improved our inference engine significantly in other areas. We have added new features such as INT16 support (e.g. for audio models), support for more layers, lowered RAM usage further, and added support for more types of microcontrollers.
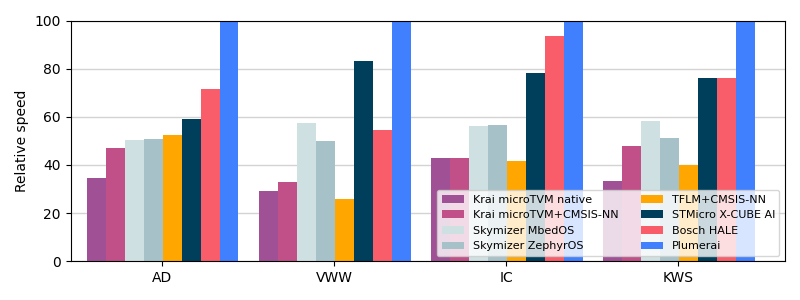
We recently also extended support for the Arm Cortex-M0/M0+ family. Even though our results for these tiny microcontrollers are not included in MLPerf Tiny 1.1, we did run extra benchmarks with the official MLPerf Tiny software specifically for this blog post and guess what: we beat the competition again! In the following graph we present results on the STM32 Nucleo-G0B1RE board with a 64MHz Arm Cortex-M0+:
MLPerf Tiny v1.1 results on Nucleo-G0B1RE (Arm Cortex-M0+). The y-axis shows the relative speed [higher is better] of the different solutions compared to the best result, measured in percentage (0 till 100%). The x-axis shows the 4 official MLPerf Tiny benchmarks.
As mentioned before, our inference engine also does very well on reducing RAM usage and code size, which are often very important factors for microcontrollers due to their limited on-chip memory sizes. MLPerf Tiny does not measure those metrics, but we do present them here. The following table shows the peak RAM numbers for our inference engine compared to TensorFlow Lite for Microcontrollers (TFLM) with Arm’s CMSIS-NN:
| Memory | Visual Wake Words | Image Classification | Keyword Spotting | Anomaly Detection | Reduction |
|---|---|---|---|---|---|
| TFLM memory (KiB) | 98.80 | 54.10 | 23.90 | 2.60 | |
| Plumerai memory (KiB) | 36.60 | 37.90 | 17.10 | 1.00 | |
| Reduction | 2.70x | 1.43x | 1.40x | 2.60x | 2.03x |
The Plumerai Inference Engine reduces memory usage by a factor of 2.03x.
And here are our code size results (excluding model weights) compared to TensorFlow Lite for Microcontrollers (TFLM):
| Code size | Visual Wake Words | Image Classification | Keyword Spotting | Anomaly Detection | Reduction |
|---|---|---|---|---|---|
| TFLM code (KiB) | 187.30 | 93.60 | 104.00 | 42.60 | |
| Plumerai code (KiB) | 54.00 | 22.50 | 20.20 | 28.40 | |
| Reduction | 3.47x | 4.16x | 5.15x | 1.50x | 3.57x |
MLPerf Tiny code size is lower by a factor of 3.57x.
Want to see how fast your models can run? You can submit them for free on our Plumerai Benchmark service. We compile your model, run it on a microcontroller, and email you the results in minutes. Curious to know more? You can browse our documentation online. Contact us if you want to include the Plumerai Inference Engine in your SDK.