This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA.
Vision Transformers (ViTs) are taking computer vision by storm, offering incredible accuracy, robust solutions for challenging real-world scenarios, and improved generalizability. The algorithms are playing a pivotal role in boosting computer vision applications and NVIDIA is making it easy to integrate ViTs into your applications using NVIDIA TAO Toolkit and NVIDIA L4 GPUs.
How ViTs are different
ViTs are machine learning models that apply transformer architectures, originally designed for natural language processing, to visual data. They have several advantages over their CNN-based counterparts and the ability to perform parallelized processing of large-scale inputs. While CNNs use local operations that lack a global understanding of an image, ViTs provide long-range dependencies and global context. They do this effectively by processing images in a parallel and self-attention-based manner, enabling interactions between all image patches.
Figure 1 shows see the processing of an image in a ViT model, where the input image is divided into smaller fixed-size patches, which are flattened and transformed into sequences of tokens. These tokens, along with positional encodings, are then fed into a transformer encoder, which consists of multiple layers of self-attention and feed-forward neural networks.
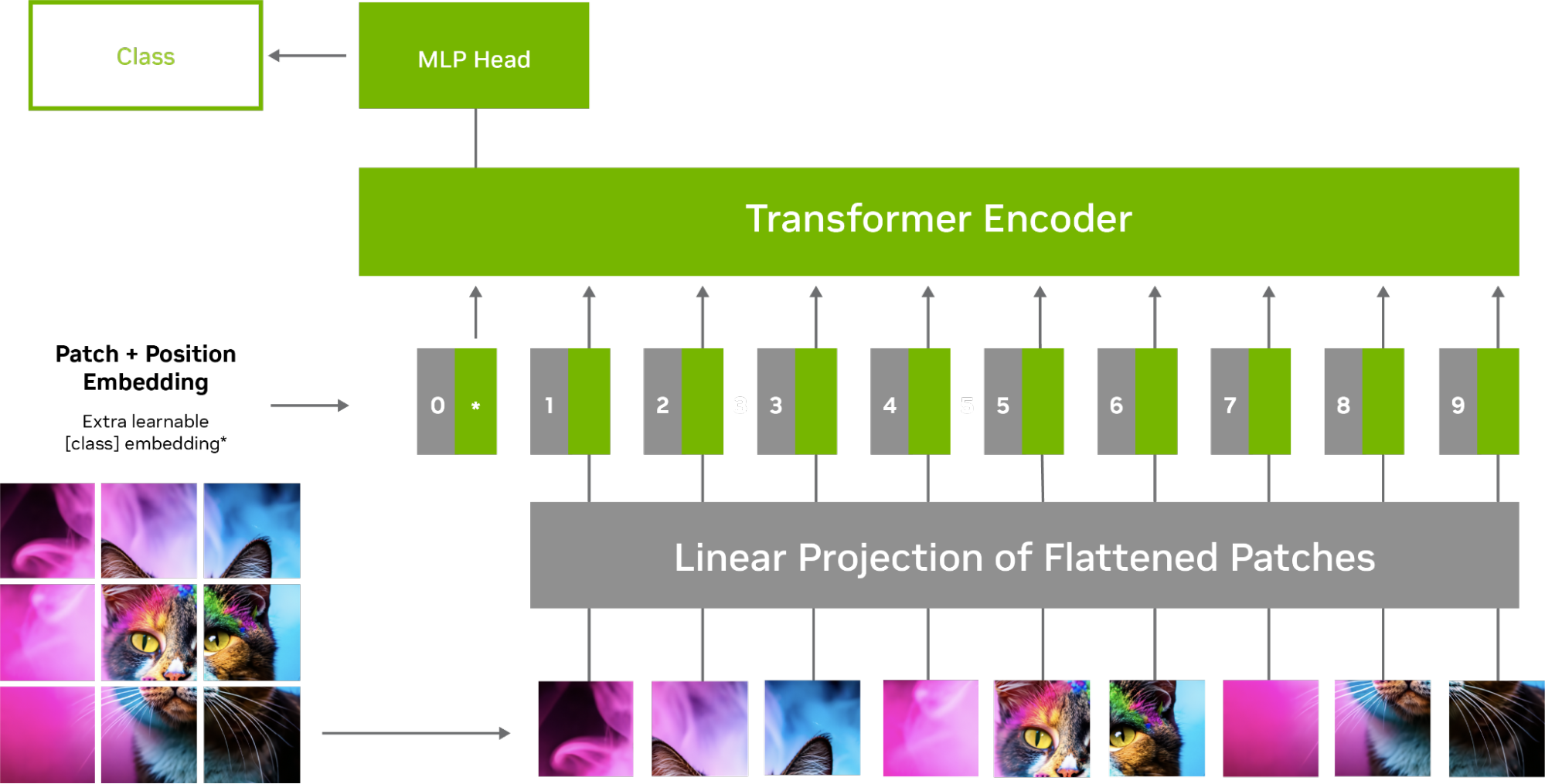
Figure 1. Processing an image in a ViT model that includes positional embedding and encoder (inspired by the study Transformers for Image Recognition at Scale)
With the self-attention mechanism, each token or patch of an image interacts with other tokens to decide which tokens are important. This helps the model capture relationships and dependencies between tokens and learns which ones are considered important over others.
For example, with an image of a bird, the model pays more attention to important features, such as the eyes, beak, and feathers rather than the background. This translates into increased training efficiency, enhanced robustness against image corruption and noise, and superior generalization on unseen objects.
Why ViTs are critical for computer vision applications
Real-world environments have diverse and complex visual patterns. The scalability and adaptability of ViTs enable them to handle a wide variety of tasks without the need for task-specific architecture adjustments, unlike CNNs.

Figure 2. Different types of imperfect and noisy real-world data create challenges for image analysis.
In the following video, we compare noisy videos running both on a CNN-based model and ViT-based model. In every case, ViTs outperform CNN-based models.
Learn about SegFormer, a ViT model that generates robust semantic segmentation while maintaining high efficiency
Integrating ViTs with TAO Toolkit 5.0
TAO, a low-code AI toolkit to build and accelerate vision AI models, now makes it easy to build and integrate ViTs into your applications and AI workflow. Users can quickly get started with a simple interface and config files to train ViTs, without requiring in-depth knowledge of model architectures.
The TAO Toolkit 5.0 features several advanced ViTs for popular computer vision tasks including the following.
Fully Attentional Network (FAN)
As a transformer-based family of backbones from NVIDIA Research, FAN achieves SOTA robustness against various corruptions as highlighted in Table 1. This family of backbones can easily generalize to new domains, fighting noise and blur. Table 1 shows the accuracy of all FAN models on the ImageNet-1K dataset for both clean and corrupted versions.
| Model | # of Params | Accuracy (Clean/Corrupted) |
| FAN-Tiny-Hybrid | 7.4M | 80.1/57.4 |
| FAN-Small-Hybrid | 26.3M | 83.5/64.7 |
| FAN-Base-Hybrid | 50.4M | 83.9/66.4 |
| FAN-Large-Hybrid | 76.8M | 84.3/68.3 |
Table 1: Size and accuracy for FAN models
Global Context Vision Transformer (GC-ViT)
GC-ViT is a novel architecture from NVIDIA Research that achieves very high accuracy and compute efficiency. It addresses the lack of inductive bias in vision transformers. It also achieves better results on ImageNet with a smaller number of parameters through the use of local self-attention, which combined with global self-attention can give much better local and global spatial interactions.
| Model | # of Params | Accuracy |
| GC-ViT-xxTiny | 12M | 79.9 |
| GC-ViT-xTiny | 20M | 82.0 |
| GC-ViT-Tiny | 28M | 83.5 |
| GC-ViT-Small | 51M | 84.3 |
| GC-ViT-Base | 90M | 85.0 |
| GC-ViT-Large | 201M | 85.7 |
Table 2: Size and accuracy for GC-ViT models
Detection transformer with improved denoising anchor (DINO)
DINO is the newest generation of detection transformers (DETR) with faster training convergence compared to other ViTs and CNNs. DINO in the TAO Toolkit is flexible and can be combined with various backbones from traditional CNNs, such as ResNets, and transformer-based backbones like FAN and GC-ViT.
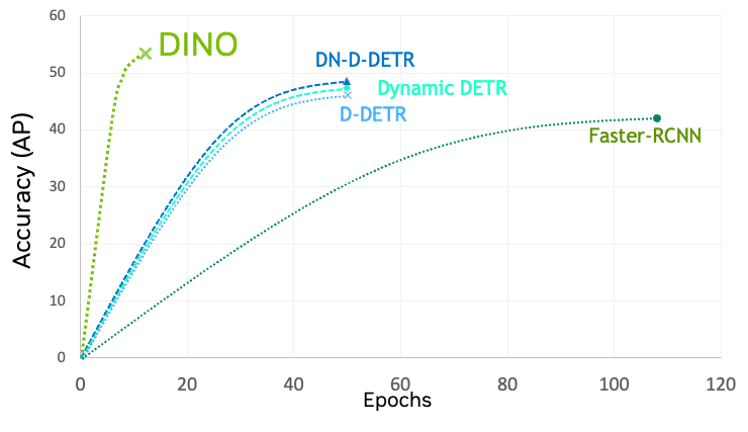
Figure 3. – Comparing the accuracy of DINO with other models
Segformer
Segformer is a lightweight and robust transformer-based semantic segmentation. The decoder is made of lightweight multi-head perception layers. It avoids using positional encoding (mostly used by transformers), which makes the inference efficient at different resolutions.
Powering efficient transformers with NVIDIA L4 GPUs
NVIDIA L4 GPUs are built for the next wave of vision AI workloads. They’re powered by the NVIDIA Ada Lovelace architecture, which is designed to accelerate transformative AI technologies.
L4 GPUs are suitable for running ViT workloads with their high compute capability of FP8 485 TFLOPs with sparsity. FP8 reduces memory pressure when compared to larger precisions and dramatically accelerates AI throughput.
The versatility and energy-efficient L4 with single-slot, low-profile form factor makes it ideal for vision AI deployments, including edge locations.
Watch this Metropolis Developer Meetup on-demand to learn more about ViTs, NVIDIA TAO Toolkit 5.0, and L4 GPUs.
Related resources
- GTC session: AI Models Made Simple Using TAO (Spring 2023)
- GTC session: Solving Computer Vision Grand Challenges in One-Click (Spring 2023)
- SDK: TAO Toolkit
- Webinar: Unleash the Power of Vision Transformers, NVIDIA TAO, and the Latest NVIDIA GPUs
- Webinar: Accelerate AI Model Creation Using AutoML in NVIDIA TAO 4.0
- Webinar: Designing Efficient Vision Transformer Networks for Autonomous Vehicles
Debraj Sinha
Product Marketing Manager for Metropolis, NVIDIA
Chintan Shah
Senior Product Manager for AI Products, NVIDIA
Ayesha Asif
Product Marketing Manager for deep learning products, NVIDIA