
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
Learn about Qualcomm Technologies’ accepted AI demos and papers
Neural Information Processing Systems (NeurIPS) is the marquee machine learning (ML) conference of the year. This year the paper acceptance rate was 26%, making it one of the most selective machine learning conferences in the world, alongside Computer Vision and Pattern Recognition Conference (CVPR) and International Conference of Computer Vision (ICCV). We are happy to see NeurIPS continuing in-person, as our team can bring both research contributions and demonstration to attendees.
This year is marked by a disruptive growth in generative artificial intelligence (Gen AI), and Qualcomm Technologies has made significant efforts to bring Gen AI to the edge. Meanwhile, Qualcomm AI Research continues exploring fundamentals along with innovations to bring AI/ML advances toward commercial applications. It was very rewarding to find out that six of our papers were accepted at the conference, as well as four accepted technology demos out of the 15 total EXPO demos.
Fast Stable Diffusion
As generative AI adoption is growing quickly, so do the cost and energy demands of the technology. Being able to distribute the processing between cloud and devices is crucial. On-device AI provides benefits in terms of cost, energy, performance, privacy and personalization — at a global scale. In this demo we showcase the world’s fastest Stable Diffusion running entirely on a smartphone, with image generation happening in under one second. Watch the video above to see how we made a 1B+ parameter generative AI model run on device through full-stack AI optimization.
Fast AI assistant
Large language models (LLMs) are useful for many user applications, from language translation to content creation, virtual assistance, and even cybersecurity. However, they are challenging to run on device. Let’s take as an example Llama 2-7B, an LLM with 7 billion parameters. All the parameters must be read to generate each token, which equates to significant bandwidth, especially for providing long answers. As a result, memory bandwidth is the bottleneck for LLMs. Our research addresses this issue. In this demo, we show Llama 2-7B Chat running at a high token rate completely on device, both a smartphone and laptop, through full-stack AI optimization.
On-device learning (ODL) for video segmentation
The past years have seen a surge in mobile video calls and live streaming. When users join video calls they want to be able to change their virtual backgrounds easily, and for those backgrounds to be robust to movements, artefacts and glitches. For this, good video segmentation is crucial. ODL is possible when the model is adapted to the target environment by training on additional user data. In this demo, we show a video segmentation use case, which runs efficiently and works well on any new target environment. The ODL model provides improved segmentation with a virtual background, both qualitatively and quantitatively.
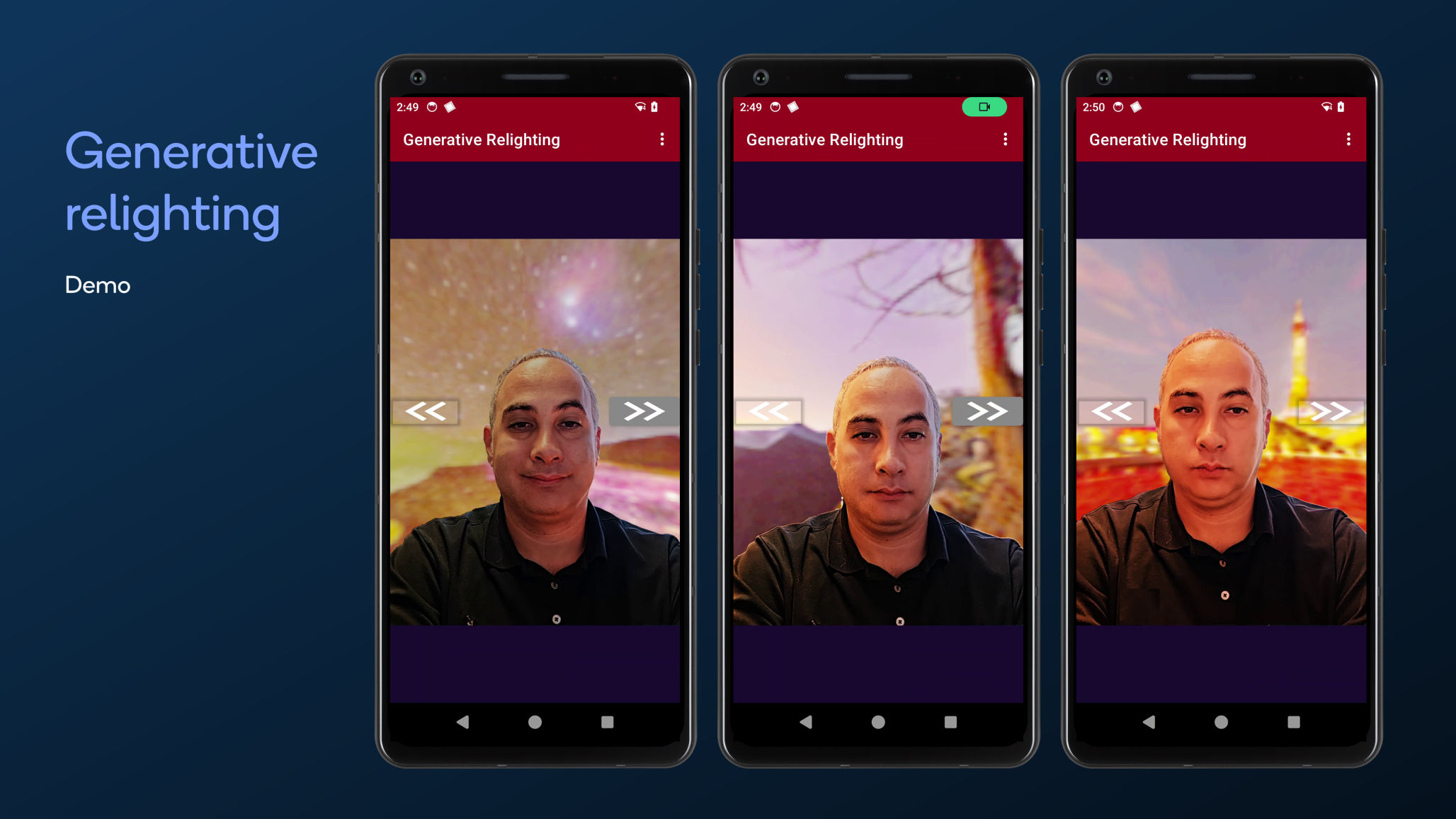
Generative relighting
Generative AI is great at creating images, but lighting is an area of improvement for realism. In this demo, we show a real-time portrait video relighting system given an AI-generated HDR map from a text prompt. Our techniques include HDRI map generation, relighting and video segmentation all running on the Qualcomm AI Engine in real time. To do this, we extend Stable360, a text-to-360° image generation model, to high dynamic range prediction and generate 360° radiance maps from text prompts. Then, we develop a relighting pipeline on the segmented foreground that combines a lightweight normal estimation network with a novel rendering equation to produce realistic lighting effects. Our demo shows visually convincing lighting effects while preserving temporal consistency. It allows a subject to be naturally embedded into AI-generated scene, which could be used in many video chat applications.
AI Model Efficiency Toolkit (AIMET) allows developers to implement ML on low-power edge devices.
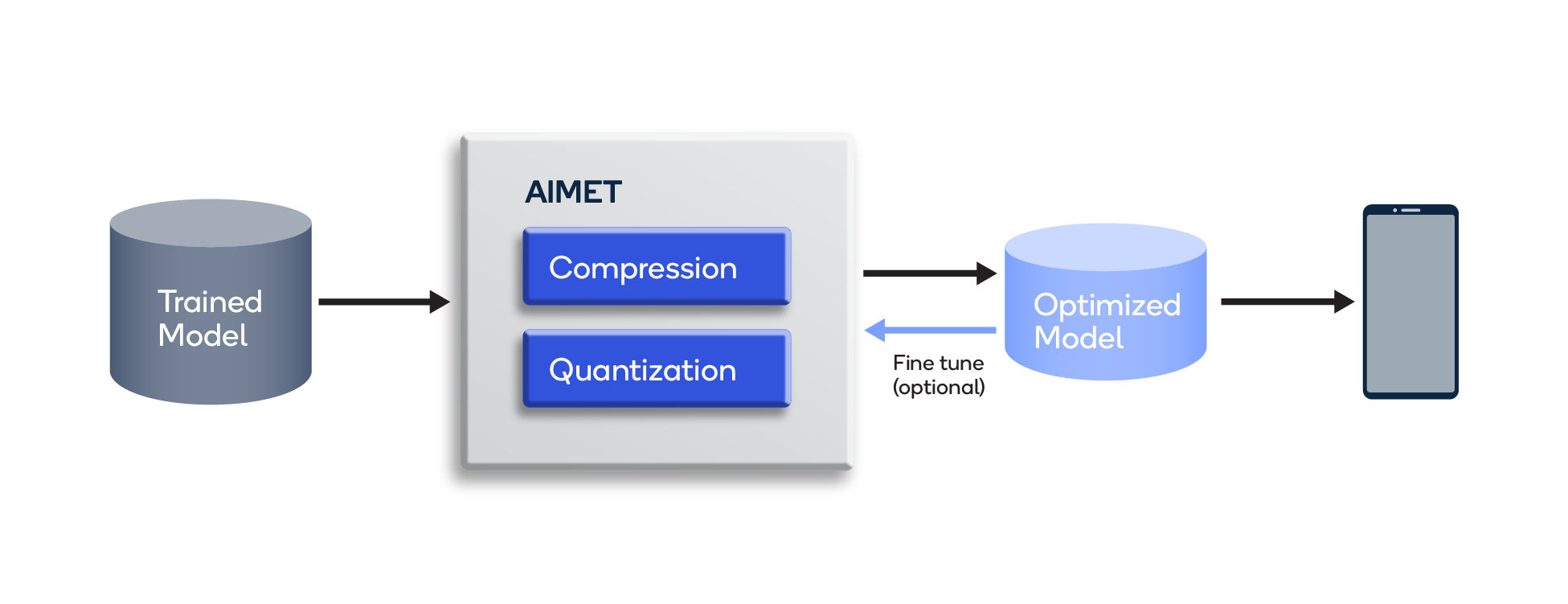
Shrinking and optimizing AI models
Making machine learning run smoothly on device through quantization and compression techniques has been an important goal for our team in the past years. We open-sourced AI Model Efficiency Toolkit (AIMET) to support developers and researchers to shrink and optimize their models, independent from which hardware they work with. Three of our NeurIPS papers tackle this topic further.
Quantization is one of the most effective ways to reduce the latency, computational resources and memory consumption of neural networks. However, modern transformer models tend to learn strong outliers in their activations, making them difficult to quantize. In our paper “Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing,” we introduce two simple (independent) modifications to the attention mechanism: clipped softmax and gated attention. We empirically show that models pre-trained using our methods learn significantly smaller outliers while maintaining and sometimes even improving the floating-point task performance. This enables us to quantize transformers to full 8-bit integer (INT8) of the activations without any additional effort and with good performance on language models and vision transformers.
Neural network pruning is just as good to optimize neural networks as quantization — or is it? We set out to compare the two techniques in a reliable way. First, we give an analytical comparison of expected quantization and pruning error for general data distributions. Then, we provide lower bounds for the per-layer pruning and quantization error in trained networks and compare these to empirical error after optimization. Finally, we provide an extensive experimental comparison for training eight large-scale models on three tasks. We published our results in the paper “Pruning vs Quantization: Which is Better?,” showing that quantization provides better accuracy in a large fraction of use cases but not in very specific cases of high compression ratios.
For better model efficiency, training a model on multiple input domains and/or output tasks turns out to be a good idea, as this allows for compressing information from more sources into a unified backbone. It also enables knowledge transfer across tasks and domains with improved accuracy and data efficiency.
However, this kind of training is still a challenge due to discrepancies between tasks or domains. We set out to solve this problem in the paper “Scalarization for Multi-Task and Multi-Domain Learning at Scale”. We devise a large-scale unified analysis of multi-domain and multi-task learning to better understand the dynamics of scalarization across varied task/domain combinations and model sizes. Following these insights, we then propose to leverage population-based training to efficiently search for the optimal scalarization weights when dealing with many tasks or domains.
Improving Chain-of-Thought for LLMs
Chain-of-Thought (CoT) prompting of LLMs is gaining more popularity recently, as users are attempting to improve the reasoning process of LLMs in solving a complex problem. For this purpose, the user shows the model a few examples where the step-by-step reasoning is taught. The models, however, often produce hallucinations and accumulated errors because of CoT. We seek to enable deductive reasoning and self-verification in LLMs in the paper “Deductive Verification of Chain-of-Thought Reasoning.” We propose Natural Program, a natural language-based deductive reasoning format. Our approach enables models to generate precise reasoning steps where subsequent steps are more rigorously grounded on prior steps. It also empowers language models to carry out reasoning self-verification in a step-by-step manner. Through this method we significantly enhanced the rigor and trustfulness of generated reasoning steps. Along this process, we also improve the answer correctness on complex reasoning tasks. Code has been released.
AI-powered robotics has great potential for improving society.

Embodied AI
At Qualcomm AI Research, we are working on applications of generative modelling to embodied AI and robotics, to go beyond classical robotics and enable capabilities such as:
- Open vocabulary scene understanding.
- Natural language interface.
- Reasoning and common sense via LLMs.
- Closed-loop control, dynamic actions via LLMs or diffusion models.
- Vision-language-action models.
One of the challenges of reinforcement learning for embodied AI is sample inefficiency and poor generalization of data. In the paper “EDGI: Equivariant Diffusion for Planning with Embodied Agents,” we introduce the Equivariant Diffuser for Generating Interactions (EDGI), a reinforcement learning algorithm that is equivariant to spatial symmetry, discrete time-translation and object permutation. EDGI follows the Diffuser framework (Janner et al., 2022) in treating both learning a world model and planning in it as a conditional generative modelling problem, training a diffusion model on an offline trajectory dataset. On object manipulation and navigation tasks, EDGI is much more sample efficient and generalizes better across the symmetry group SE(3) than non-equivariant models.
Geometric data is important for the field of robotics. This can take numerous forms, such as points, direction vectors, translations or rotations, but there isn’t any unifying architecture available at the moment for this. In our paper “Geometric Algebra Transformers (GATr),” we introduce the GATr method, which considers geometric structures of the physical environment through geometric algebra representations and equivariance. It has the scalability and expressivity of transformers. At its core, GATr is a general-purpose architecture for geometric data. It has three components: geometric algebra representations, equivariant layers and a transformer architecture. We show that GATr consistently outperforms both non-geometric and equivariant baselines in terms of error, data efficiency and scalability.
Dr. Jilei Hou
Vice President of Engineering, Qualcomm Technologies