This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
How pruning, quantization and knowledge distillation help fit generative AI into resource-limited edge devices
As of April 2023, one in three U.S. adults have used generative artificial intelligence (AI): Are you among them?1 When OpenAI unveiled ChatGPT in November 2022, it sparked an international AI frenzy.
And while most generative AI applications run in the cloud today, their workloads burden the cloud with added equipment and operating costs. Consequently, these additional AI workload burdens are causing a re-evaluation of how AI models can best be implemented as applications such as ChatGPT and Midjourney see broader and broader use.
One of the most promising implementation strategies is to move some or all of the AI workload to edge devices, such as smartphones, laptops and extended reality (XR) headsets, since they have significant on-device AI processing capability available. This on-device AI implementation strategy requires that AI models be optimized for edge devices, taking advantage of their available AI accelerators.
Examples of generative AI requests that can be implemented locally include: text generation; image and video generation, enhancement or modification; audio creation or enhancement and even code generation.
At Mobile World Congress earlier this year, we demonstrated Stable Diffusion, a text-to-image generative AI model, on a smartphone powered by the Snapdragon 8 Gen 2 processor.
More recently, we announced our intention to deliver large language models (LLMs) based on Meta’s Llama 2 running on Snapdragon platforms in 2024. Optimization of these neural networks will reduce the memory and processing requirements, placing them within the capacity of mainstream edge devices.
While the performance improvements in mobile systems-on-chips (also known as SoCs) are unlikely to outpace the parameter growth of some generative AI applications, such as ChatGPT, many sub-10 billion parameter generative AI models exist today that are suitable for on-device processing, and the number of these AI models will increase over time.
For AI to scale efficiently, models need to be optimized for their target devices.

Optimizing AI models for on-device use
While neural network models are generally trained in a data center with high levels of accuracy, AI models deployed on edge devices, or even in the cloud, trade off computational efficiency with accuracy. The goal being to achieve a balance between getting the model as small as possible while still achieving high enough accuracy for the results to be valuable in the particular use case.
Typically, the larger the model, the more accurate the result. However, in many cases, increased accuracy comes at a high price, in terms of resource usage, and with only minimal benefit. AI model size is measured by the number of parameters in the model, where fewer parameters generally require less time or computational resources to produce a result.
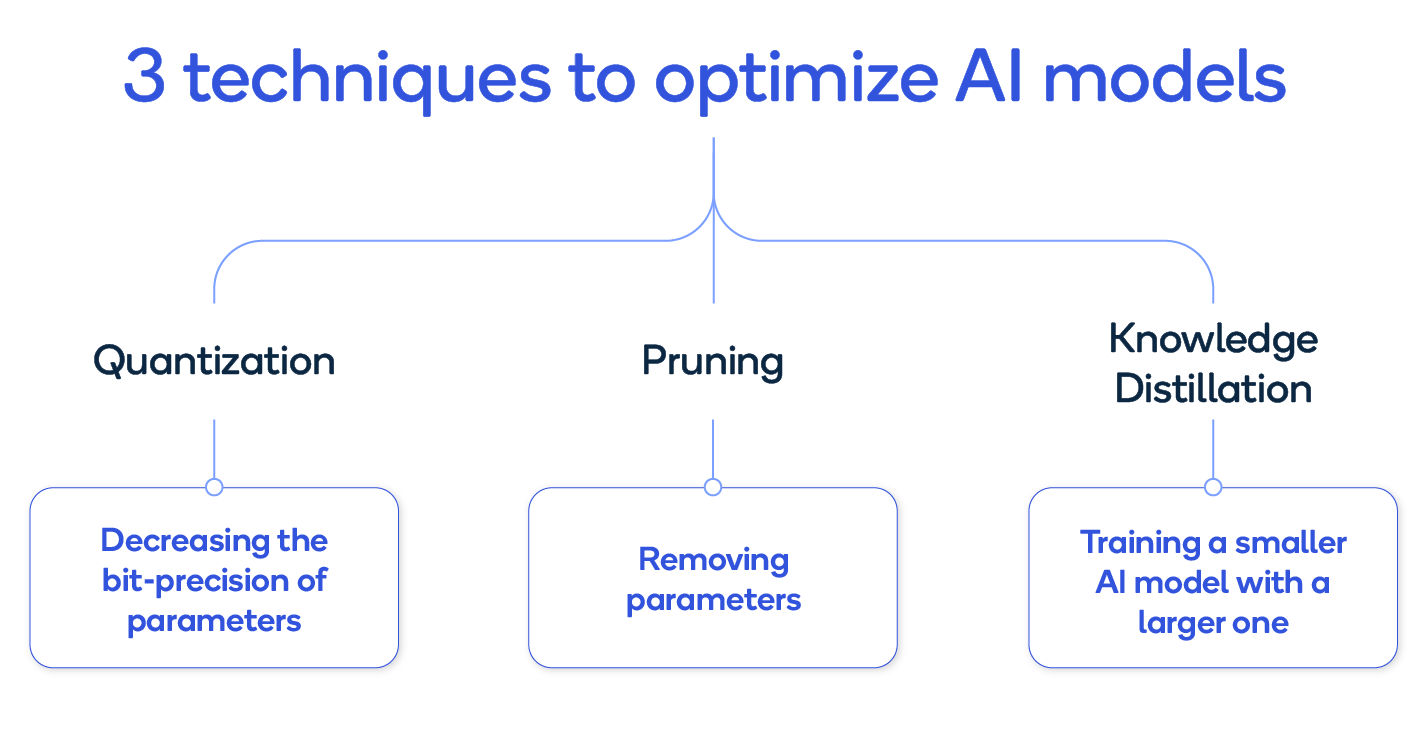
Techniques to compress AI models while maintaining nearly the same accuracy.
3 techniques to optimize AI models
There are three major techniques for optimizing AI models: quantization, pruning and knowledge distillation.
- Quantization reduces the bit-precision that the AI model uses for the neural network’s weight and activation values, using lower-precision data types including 4-bit or 8-bit integers (INT4 or INT8) instead of the higher-precision, 32-bit floating point (FP32) data type that’s usually used when training the model. Quantizing to 8-bits from 32-bits reduces the model size by 4x.
- Pruning2 is a process of identifying and eliminating parameters that are redundant or unimportant. Pruning can improve AI model efficiency while maintaining similar accuracy. Our results have shown a 3x reduction in model size with less than 1% loss in accuracy using both Bayesian compression and spatial SVD with ResNet18 as baseline. Our results show that in most cases quantization outperforms pruning.
- Knowledge distillation3 starts with a large, trained AI model and uses it to train a smaller model, which results in model size reduction often many times smaller than the original model while maintaining similar accuracy.
Optimized AI models combined with improving on-device AI capabilities allow generative AI to proliferate across devices, such as phones, laptops and XR headsets.

Moving AI workloads on device
Using these three optimization techniques, it’s not difficult to imagine how generative AI — or any AI application — can be moved to an edge device like a personal computer, smartphone or XR headset.
Smartphones have already shown they can leverage advances in processing, memory and sensor technology to rapidly absorb functionality. In less than a decade, smartphones have replaced portable media players, handheld gaming devices, point-and-shoot cameras, consumer video cameras and prosumer digital Single Lens Reflex (also known as dSLR) cameras. Premium smartphones for the past several years can capture and process 8K video seamlessly.
Major smartphone brands already leverage on-device AI technology for a variety of functions ranging from battery life and security to audio enhancement and computational photography. The same is true for most major edge device platforms and edge networking solutions. The challenge is shrinking and optimizing generative AI models to run on these edge devices.
Processing AI models on device not only reduces latency, but it also addresses another growing concern — AI privacy and data security. By eliminating the interaction with the cloud, data and the resulting generative AI results can remain on the device.
Generative AI is migrating toward edge devices, such as phones, as models continue to be optimized.

Generative AI optimization for edge devices: it’s the future
As widespread consumer use of generative AI continues to expand, the burden of running its workloads in the cloud will follow. These additional AI workloads on the cloud are causing a re-evaluation of how AI models can best be implemented.
Optimization techniques such as quantization, pruning and knowledge distillation are being used to shrink AI models and make them suitable for on-device processing. By moving AI workloads to edge devices, users can experience reduced latency, enhanced privacy, personalization and other benefits of on-device AI.
Pat Lawlor
Director, Technical Marketing, Qualcomm Technologies, Inc.
Jerry Chang
Senior Manager, Marketing, Qualcomm Technologies
References
- Kastrenakes, J. and Veincent, J. (June. 15, 2023). Hope, Fear, and AI. Retrieved on September 6, 2023 from https://www.theverge.com/c/23753704/ai-chatgpt-data-survey-research.
- Hazimeh, H. and Benbaki, R. (August 17, 2023). Neural network pruning with combinatorial optimization. Retrieved September 26, 2023 from https://blog.research.google/2023/08/neural-network-pruning-with.html.
- Ji, G. and Zhu, Z. (NuerIPS Conference 2020.). Knowledge Distillation in Wide Neural Networks: Risk Bound, Data Efficiency and Imperfect Teacher. Retrieved on September 19, 2023 from https://proceedings.neurips.cc/paper/2020/file/ef0d3930a7b6c95bd2b32ed45989c61f-Paper.pdf.