
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm
Find out how LLM quantization solves the challenges of making AI work on device
In the rapidly evolving world of artificial intelligence (AI), the growth of large language models (LLMs) has been nothing short of astounding. These models, which power everything from chatbots to advanced code generation tools, have grown exponentially in size and complexity. However, this growth brings significant challenges, particularly when it comes to deploying these models on devices with limited memory and processing power. This is where the innovative field of LLM quantization comes into play, offering a pathway to scale AI more effectively.
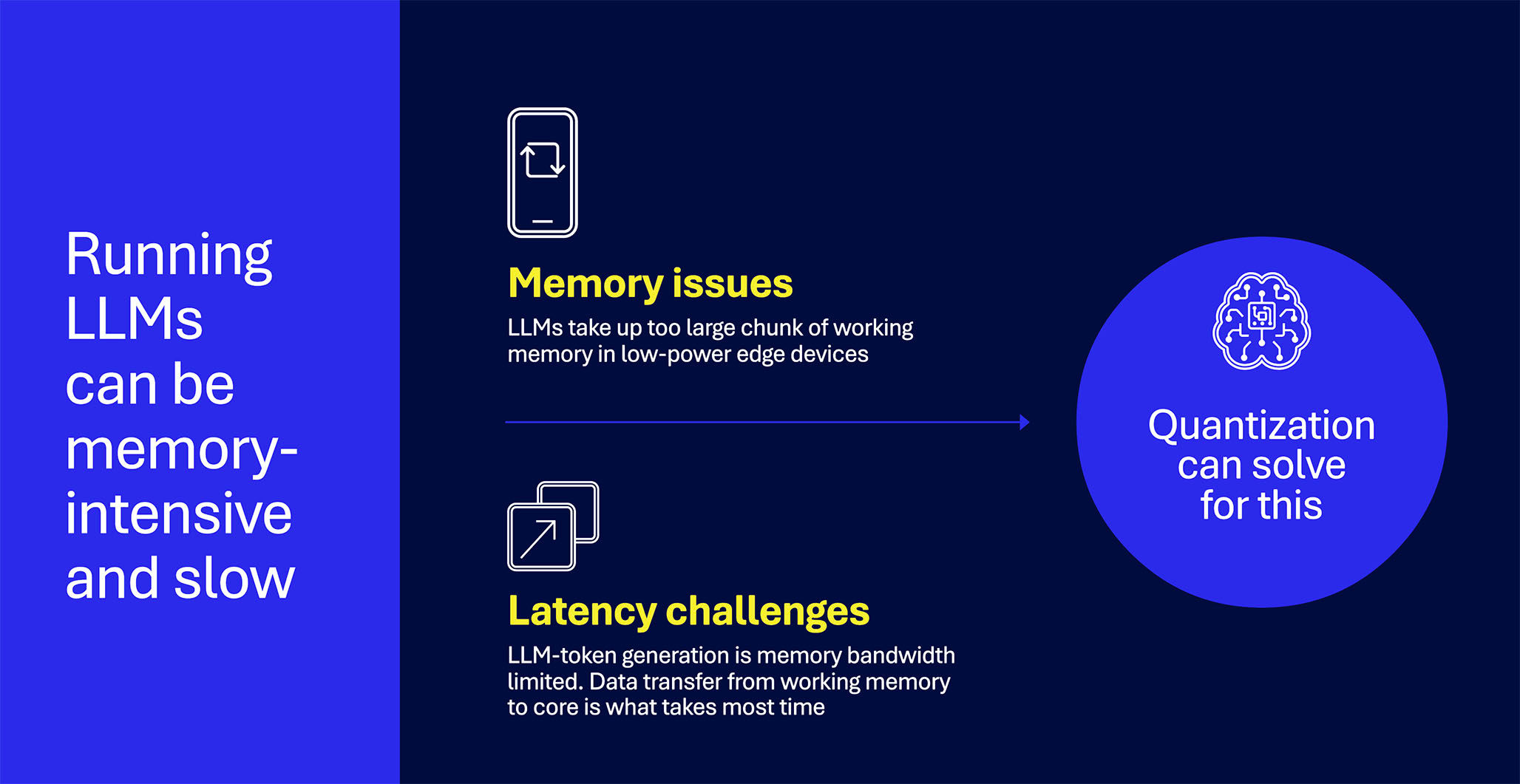
The challenge of large language models
The last years have seen a rise of flagship LLMs such as GPT-4 and Llamav3-70B. However, these models have tens to hundreds of billions of parameters and are too large to run on low-power edge devices. Smaller LLMs like Llamav3-8B phi-3 still achieve amazing results, and can run on low-power edge devices, but do require substantial memory and computational resources. This poses a problem for deployment on low-power edge devices, which have less working memory and processing power compared to cloud-based systems.
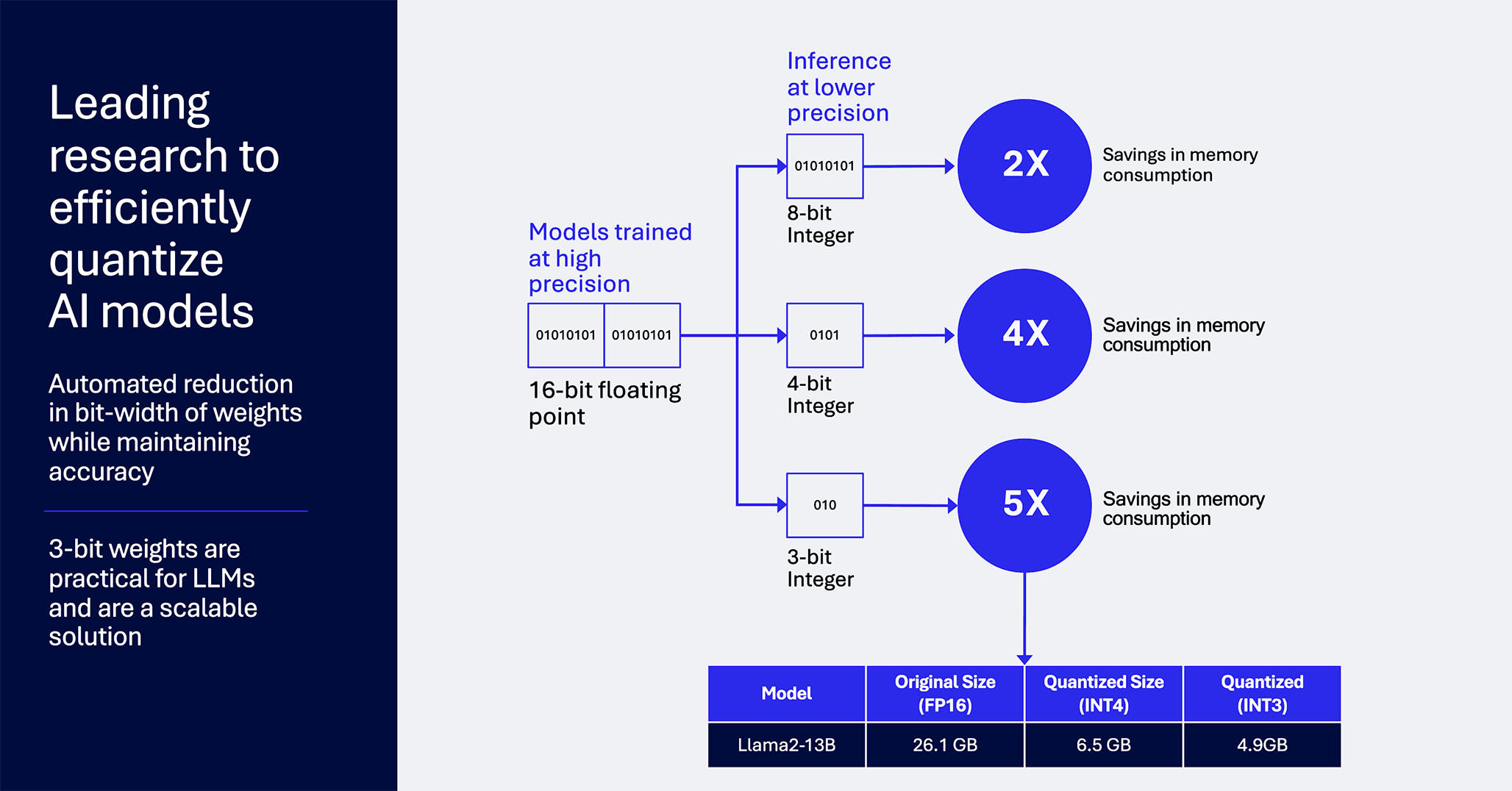
Enter quantization: A solution for efficiency
Quantization is a technique used to reduce the precision of the numbers used in computations, which in turn decreases the model size and the resources needed to run it. By converting floating-point representations to lower-bit integers, quantization significantly reduces the memory requirements and speeds up the processing time, making it feasible to run LLMs on edge devices.
Qualcomm AI Research has been creating and publishing state-of-the-art research in model efficiency for many years. Our work focuses on various quantization techniques, including post-training quantization (PTQ) and quantization-aware training (QAT). QAT incorporates quantization into the training process, allowing the model to adapt to the reduced precision and maintain higher accuracy. PTQ is a method that involves taking a pre-trained model and directly converting it into a lower precision format, which is faster and requires less expertise, but is also less accurate. How do we get the best of both worlds?
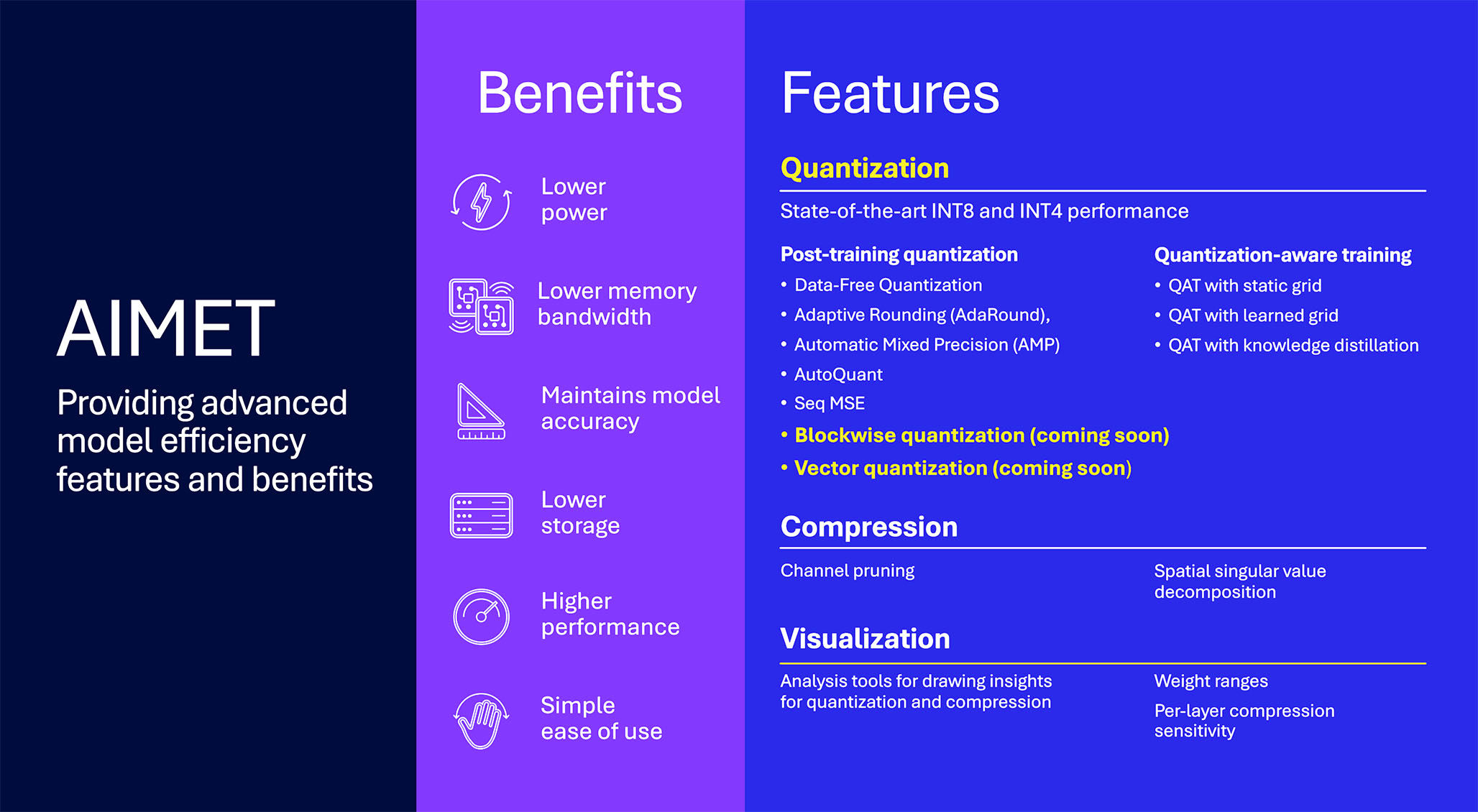
Supporting developers in quantizing their models
The Qualcomm Innovation Center has open-sourced the AI Model Efficiency Toolkit and more recently has published the comprehensive Qualcomm AI Hub portal, which allows developers to compress, quantize and visualize their models properly, as well as choose from a library of over 100 pre-optimized AI models ready to deploy with for up to four times faster inferencing.
Some newer techniques made available to the AI community are sequential mean squared error (MSE), which finds a weight quantization scale that minimizes output activation MSE, as well as knowledge distillation, which improves QAT through training a smaller “student” model to mimic a larger “teacher” model. Qualcomm AI Research’s paper on low-rank QAT for LLMs dives deeper into this topic.

The role of vector quantization in LLMs
A promising advancement is vector quantization (VQ), which Qualcomm has been actively developing. Unlike traditional methods that quantize each parameter independently, VQ considers the joint distribution of parameters, leading to more efficient compression and less loss of information.
Qualcomm’s novel approach, GPTVQ, applies vector quantization to LLMs by quantizing groups of parameters together, rather than individually. This method preserves the accuracy of the models and reduces their size more effectively than traditional quantization methods. For instance, our experiments showed that GPTVQ could achieve near-original model accuracy with significantly reduced model size, making it a game-changer for deploying powerful AI models on edge devices.
Implications for AI scaling
The implications of effective LLM quantization are vast. By reducing the size and computational demands of LLMs, AI applications can become more accessible, running efficiently on a wider range of devices from smartphones to IoT devices. This democratizes access to advanced AI capabilities, enabling a new wave of innovation in AI applications across industries.
Moreover, the ability to run LLMs on edge devices also addresses privacy and latency issues associated with cloud computing, as data can be processed locally without the need to be sent to a centralized server.
As AI continues to advance, the ability to scale LLMs efficiently will be crucial for the next generation of AI applications. Quantization, particularly techniques like vector quantization developed by Qualcomm AI Research, offers a promising solution to overcome the challenges of memory and latency of AI on low-power edge devices. With ongoing research and development, the future of AI looks not only more intelligent but also more accessible and efficient.
Access the webinar — Quantization: Unlocking scalability for LLMs
Mart van Baalen
Engineer, Senior Staff/Manager, Qualcomm Technologies Netherlands B.V.
Abhijit Khobare
Senior Director, Software Engineering, Qualcomm Technologies, Inc.