
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm.
See how Qualcomm AI Research continues to innovate, from platform enhancements to AI fundamentals
Neural Information Processing Systems (NeurIPS), the premier machine learning conference, returns in person this year with an impressive 25% acceptance rate, maintaining its status as one of the most prestigious events in the field alongside Computer Vision and Pattern Recognition Conference (CVPR) and International Conference of Computer Vision (ICCV). We’re thrilled to engage with attendees directly, showcasing our research and demos.
2024 is notable for the remarkable advancements in generative artificial intelligence (GenAI), and Qualcomm Technologies is at the forefront of bringing these capabilities to edge devices. Our Qualcomm AI Research team is dedicated to pushing the boundaries of AI/ML and translating these innovations into real-world applications.
We’re proud to have 11 papers and five technology demos accepted at the conference, with our demos making up over a quarter of the total EXPO demonstrations. We can’t wait to connect with you in Vancouver starting December 10. Be sure to visit us at booth #533, explore our EXPO demos, workshop and talk panel, as well as join our accepted poster sessions and workshops to learn more about our work.
Visual results generated by LoRA and FouRA for “Blue Fire” style adapter across four seeds with the prompt, “fantastical forest witch”. While LoRA images suffer from distribution collapse and lack diversity, we observe diverse images generated by FouRA.
Innovative papers with novel discoveries
At prestigious academic conferences like NeurIPS, groundbreaking papers serve as a key channel for sharing innovative and influential AI research with the broader community. I want to spotlight some of our accepted papers and key themes that are pushing the boundaries of machine learning.
Our papers can be categorized under two main areas: generative AI and foundational machine learning. Here is a list of our papers contributing to generative AI:
- FouRA: Fourier Low-Rank Adaptation
- SHiRA: Sparse High-Rank Adapters
- Hollowed Net for On-Device Personalization of Text-to-Image Diffusion
- Read-ME: Refactorizing LLMs as Router-Decoupled MoE with System Co-Design
- AdaEDL: Early Draft Stopping for Speculative Decoding of LMMs (ENLSP workshop paper)
- Live Fitness Coaching as a Testbed for Situated Interaction
- ClevrSkills: Compositional Language And Visual Understanding in Robotics
- Your Context Is Not an Array: Unveiling Random Access Limitations in Transformers (S2RS workshop paper)
Low-rank adaptation (LoRA) has been a game-changer for efficiently fine-tuning large models. However, it often leads to less diverse images, especially with smaller datasets. To tackle this, we introduce FouRA, a novel low-rank method that learns projections in the Fourier domain and employs a flexible input-dependent adapter rank selection strategy. FouRA enhances the generalization of fine-tuned models through adaptive rank selection, significantly improving image quality.
From a mobile deployment perspective, LoRA faces challenges like significant inference latency when switching multiple fused models and concept-loss with concurrent adapters. We propose Sparse High Rank Adapters (SHiRA), a new paradigm with no inference overhead, rapid switching and reduced concept-loss. Our extensive experiments on vision-language models and large language models (LLMs) show that fine-tuning a small fraction of the base model’s parameters suffices for many tasks, enabling rapid switching and multi-adapter fusion.
Additionally, we present Hollowed Net, an efficient LoRA-based personalization approach for on-device subject-driven generation. By fine-tuning pretrained diffusion models with user-specific data on resource-constrained devices, our method enhances memory efficiency during fine-tuning by temporarily removing a fraction of the deep layers in a diffusion U-Net, creating a hollowed structure. We show that our approach substantially reduces training memory to levels required for inference while maintaining or improving personalization performance.
Mixture-of-Experts (MoE) architectures use specialized subnetworks to boost efficiency and performance. However, they struggle with inference issues like inefficient memory management and suboptimal batching due to misaligned design choices. To tackle this, we introduce Read-ME, a framework that converts pretrained dense LLMs into smaller MoE models, avoiding the high costs of training from scratch. Read-ME outperforms other dense models of similar scales, improving accuracy benchmarks and reducing end-to-end latency. Check out the code.
To speed up inference without sacrificing accuracy, speculative decoding uses a more efficient draft model to propose tokens, which are then verified in parallel. Our Adaptive Entropy-based Draft Length (AdaEDL) offers a simple, training-free criterion for early stopping in token drafting by estimating a lower bound on the acceptance probability based on the observed entropy of the logits. AdaEDL consistently outperforms static draft-length speculative decoding by up to 57% and integrates seamlessly into existing LLMs.
Vision-language models have made impressive strides recently, but most are still limited to turn-based interactions. They struggle with open-ended, asynchronous interactions where an AI can proactively provide timely responses or feedback in real-time. To push research forward, we introduce the Qualcomm Exercise Video Dataset and benchmark, focusing on human-AI interaction in the real-world domain of fitness coaching. This task requires monitoring live user activity and giving immediate feedback. We propose a straightforward end-to-end streaming baseline that responds asynchronously to human actions with timely feedback.
We also explore highly compositional robotics tasks. Given the progress of large vision-language models in human-like reasoning, we ask: If these models learn the necessary low-level skills, can they combine them to perform complex tasks like cleaning a table without explicit instructions? We introduce ClevrSkills, a benchmark suite for compositional reasoning in robotics. This suite assesses a model’s ability to generalize and execute step-by-step plans, covering both high-level planning and low-level execution for various end-to-end robotics tasks. This helps evaluate a model’s capability to plan and execute within a closed loop.
Our papers contributing to foundational machine learning areas are:
- On Sampling Strategies for Spectral Model Sharding
- An Information Theoretic Perspective on Conformal Prediction
- Stepping Forward on the Last Mile
- UniMTS: Unified Pre-training for Motion Time Series
- Textual Training for the Hassle-Free Removal of Unwanted Visual Data
- Optimizing Attention (OPT)
Due to increasing concerns about user data privacy, a federated approach becomes a viable alternative for common centralized methods of machine learning. Several methods which carefully create smaller sub-models from a larger global model were proposed. Spectral model sharding (i.e., partitioning the model parameters into low-rank matrices based on the singular value decomposition) has been one of the proposed solutions for more efficient on-device training in such settings. We present two sampling strategies for such sharding, obtained as solutions to specific optimization problems and demonstrate that both of these methods can lead to improved performance on various commonly used datasets.
Machine learning models have rapidly grown in popularity and found use in many safety-critical domains where predictions must be accompanied by reliable measures of uncertainty to ensure safe-focused decision-making. However, most ML models are designed and trained to produce only point estimates, which capture only crude notions of uncertainty with no statistical guarantees. Conformal prediction (CP) has recently gained in popularity as a principled and scalable solution to equip any model with proper uncertainty estimates in the form of prediction sets. We take a closer look at conformal prediction through the lens of information theory, establishing a connection between conformal prediction and the underlying intrinsic uncertainty of the data-generating process. We prove three different ways to upper bound the intrinsic uncertainty. We show our theoretical results translate to lower inefficiency (average prediction set size) for popular CP methods.
Adapting pretrained models to local data on resource-constrained edge devices is the last mile for model deployment. However, as models grow, backpropagation demands too much memory for edge devices. Most low-power neural processing engines (NPUs, DSPs, MCUs) are designed for fixed-point inference, not training. Our latest research investigates on-device training with fixed-point forward gradients across various deep learning tasks in vision and audio. In our paper Stepping Forward on the Last Mile, we propose algorithm enhancements to reduce memory use and close the accuracy gap with backpropagation. Our empirical study explores how forward gradients navigate the loss landscape.
Advanced technology demonstrations painting what’s coming next
Our work isn’t confined to theoretical exploration. We breathe life into our AI research through tangible demonstrations. We’re eager to share our cutting-edge demos, highlighting remarkable strides in on-device generative AI, full-stack AI optimization and innovative AI applications. Here’s a quick description of our accepted EXPO demos.
On-device GenAI video editing demo
We are demonstrating the world’s fastest GenAI video editing on a phone. The large vision model based on InstructPix2Pix generates 512×384 resolution video at over 12 frames per second. Our full-stack AI optimization allows us to achieve this high performance at low power.
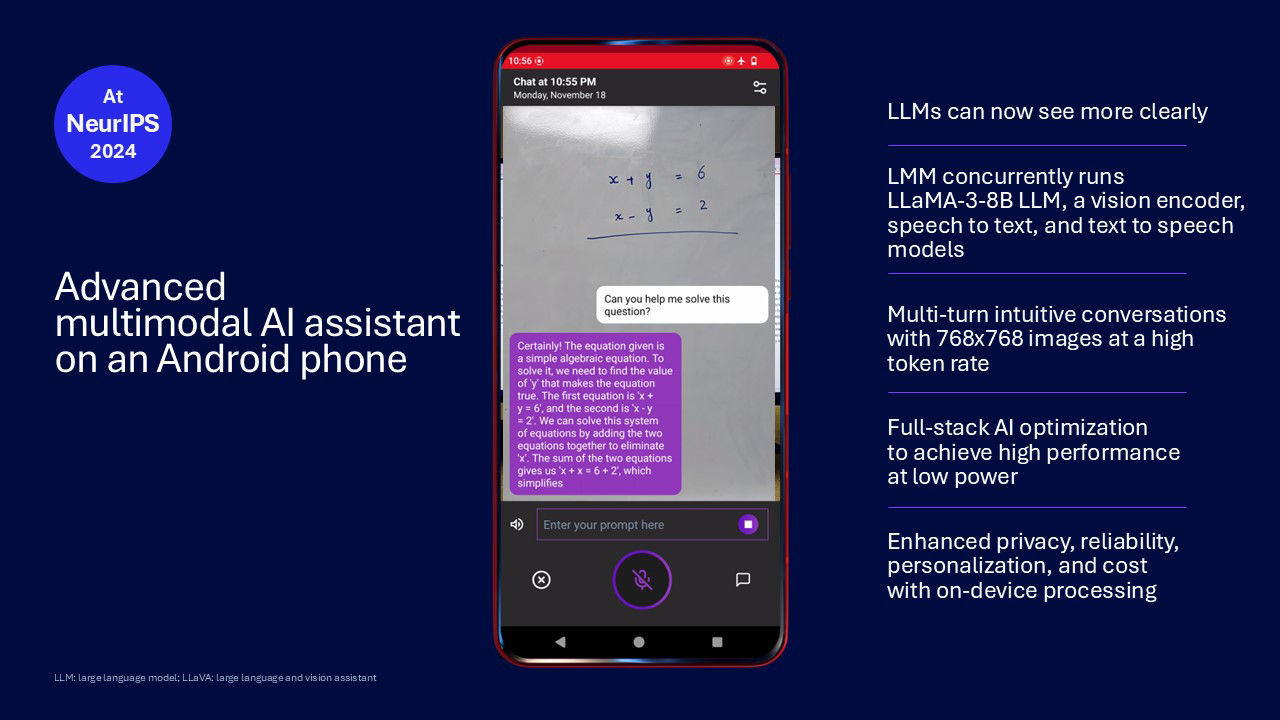
On-device multimodal AI assistant demo
We demonstrated the world’s first large multimodal model (LMM) running on an Android phone at MWC 2024. Our latest AI assistant demo efficiently runs the LMM with an increased input image resolution and upgrades to the concurrently running GenAI models, including Llama-3-8B. The end result is a more accurate assistant that sees what you see and responds to questions at a high token rate.

On-device mixture-of-experts (MoE) LLM demo
The MoE architecture has emerged as a powerful approach for enhancing the capacity of LLMs while maintaining computational efficiency. However, deploying MoE models on memory-constrained devices remains challenging due to their large number of parameters, which often exceed the available DRAM capacity of a typical smartphone. With our expert caching strategy that selectively stores only a subset of experts in DRAM from the flash memory, we are able to run a 14+ billion parameter MoE LLM on a phone with a 2x cache hit-rate improvement and 30% token rate increase compared to standard least-recently-used (LRU) caching.
On-device low-rank adaptation (LoRA) demo
LoRA reduces the number of trainable parameters of AI models significantly (e.g., 98% reduction in parameters) to lower training cost while still improving the accuracy of the model for the fine-tuned task. We first demonstrated Stable Diffusion with LoRA adapters running on an Android smartphone at MWC 2024. The LoRA adapters enable the creation of high-quality custom images for Stable Diffusion based on personal or artistic preferences.

Augmenting driving scenes with high-fidelity GenAI models demo
Training and evaluation of automotive perception models requires high-quality annotated images. We demonstrate state-of-the-art GenAI models, namely diffusion models and differentiable renderers, that create high-fidelity automotive scenes. Our implementation uses dynamic Gaussian splatting for 3D reconstruction of driving scenes to remove, translate or add new vehicles.
Additional demos at our booth
Besides our accepted EXPO demos, the other demos in our booth highlight the breadth of the AI activities happening across Qualcomm Technologies.
For AI developers, we showed how to easily compile, profile, and deploy models on edge devices with the Qualcomm AI Hub. Another developer demo showcased the Qualcomm Cloud AI 100 Ultra Developer Playground as a straightforward way to experiment with AI models and explore the Qualcomm Cloud AI 100 Ultra performance.
For automotive, we showcased our ground-truth as-a-service pipeline, which offers a comprehensive way for building a high-quality ground truth for camera perception and drive policy data.
For computer vision, we showcased open-set semantic segmentation, generative video portrait relighting, and a real-time Gaussian splatting avatar — each demo running on phone.
Additional initiatives and highlights at NeurIPS
We’re excited to share that we’ll be presenting a talk and workshop at the NeurIPS Expo this year.
Our talk explores the crucial role of deploying GenAI on device. Moving AI workloads to edge devices not only cuts cloud operation costs but also boosts privacy, reduces communication bandwidth and streamlines access. However, making GenAI work on resource-limited devices means optimizing AI models for the edge. Our talk will dive deep into these innovations, showcasing the industrial research behind this optimization. We’ll cover examples like self-speculative decoding, text-to-image/video diffusion models, 3D content generation, multimodal generative models with efficient image tokenization and efficient model fine-tuning through LoRA.
Join Us at Our Co-Organized D3S3 Workshop
We’re co-organizing an exciting workshop on the latest advances in ML and their applications in simulation-based scientific discovery. Our workshop aims to bring together experts working on topics such as learnable surrogates, probabilistic simulation and operator-valued models. We also seek to connect these experts with practitioners and researchers from diverse fields like physics, climate science, chemistry, wireless technology, graphics and manufacturing. This is a unique chance to discuss the challenges and opportunities of integrating ML methods with simulation techniques across various domains and explore new opportunities.
At Qualcomm Technologies, we pioneer groundbreaking research and extend its impact across various devices and industries, enabling our vision to drive intelligent computing everywhere. Qualcomm AI Research collaborates closely with the rest of the company to seamlessly integrate cutting-edge AI advancements into our products. This collaboration accelerates the transition from laboratory research to real-world applications, enriching our lives with innovative AI solutions.
Fatih Porikli
Senior Director of Technology, Qualcomm Technologies