
This blog post was originally published at Cadence's website. It is reprinted here with the permission of Cadence.
The keynote on the second day of the Embedded Vision Summit was by Jitendra Malik of UC Berkeley. He has been working in the field since before there really was a field, and so was the perfect person to give some history, a look at the exciting problems of today, and what we have to look to going forward.

He used the picture above to introduce the levels of the problem. There is a person sitting on a bench. She has an accordion. She has a bag. It appears to contain money. A woman with bags is walking away. A man is maybe listening to the music. And so on.
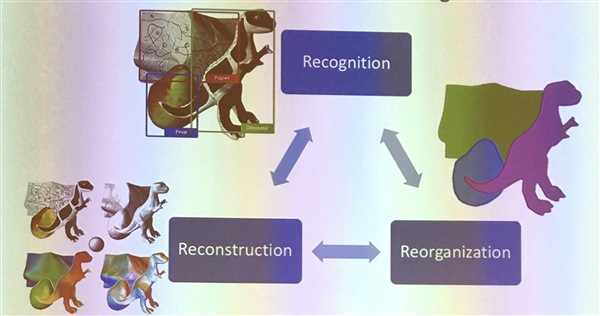
In the early days, computers were a lot slower, and the focus was on algorithmic ways of recognizing objects. Jitendra divides them into the 3Rs: recognition, reconstruction, reorganization. He said that reorganization could also be called segmentation, but 3 Rs are cuter. These three processes historically were pursued with different techniques. Five years ago Jitendra argued that they should he unified and now he realizes that the unifying technology are deep neural networks (DNN).
What changed? All the components were there. Back propagation was rediscovered and Yann Lecun applied it, giving rise to convolutional neural nets (CNN). Neural nets were invented ages ago but for 20 years they were considered good enough for digit recognition (such as reading zip codes on envelopes) but in the real world was not considered competitive. Then bigger CPUs and big data sets, especially Imagenet, came along and the rest is history.
The state of the art is that the people in the picture can be detected and the individual pixels associated with each person identified. Objects can be identified separeately: umbrella, backpack, and so on. "I should just now retire," Jitendra said. "I started 35 years ago as a grad student and this was my dream. And now it is there."
But not everything has been done, so he doesn't get to retire yet. Jitendtra went into details on three areas where research is ongoing.
Feedback Architectures
We went from neuroscience to computer vision, by taking a look at some aspects of how the brain works to come up with the idea of neural networks. But that immediately raises the question as to whether there are other things that we should be studying. For example, there is a feed forward part that we copy in CNNs, but in animal visual systems there is a ubiquitous feedback path, too.
So what use is the feedback? It enables recognition to work at both a very low level but also use higher level approaches. An example is to look at the scene and identify which parts of the scene go with which person. If you end up with a person with two heads and another with none, then you can adjust at the higher level even though at the lower level the two-headed person may be the best analysis at the pixel level.
For animals, the advantage of this move up and move down approach is that it enables rough results quickly, and more accurate results with more time. It doesn't matter to be "really, really sure that this is a tiger."
3D Understanding
Pictures are two dimensional (or sometimes we have stereo vision, too). But we have knowledge of 3D objects and we know that they have to make sense. For example, we know a lot about chairs and how they work, and how people sit on them. Bringing these two types of knowledge together, the 3D models of things and the neural nets identifying things, is hard. The big question is whether to convert geometry to the NN world, or NN into language geometry. It looks like it will be easiest to go all NN.
He had another example of a person on a horse. We know a fair bit about people and horses so that when we see a picture of a person on a horse, we immediately identify it as two objects interacting visually: it's a person on a horse, not some odd hybrid centaur-like beast we have never seen before. This is hard to do since it is not purely visual, it requires real-world knowledge. You are constructing a 3D model of the scene and the analyzing whether that is compatible with the 2D image you see.
Prediction and Self-Supervised Learning

If you go back to the picture at the beginning of the musician, then you want to be able to answer questions such as will person B put some money in person C's tip bag? Of course there is no exact answer.
One way to train this sort of work is using video, even though it is focused on analyzing two-dimensional images. Sports videos are really good for this. Look at a scene of people playing water polo or basketball and try and predict who will receive the ball next. The big advantage of this approach is that having made the prediction, the correct answer can be found by running a little more of the video. In this way the training can be self-supervised, instead of a human having to look at each image and give their prediction (the "right" answer, which might be wrong). It turns out that currently machines can do a little worse than non-experts.
Again, this requires a model, this time an action and motion model. How will a cat behave if you kick it? How will two pool balls behave if one hits the other? Infants are very good at this (they give up kicking the cat pretty quickly). It builds models of physics and models of social interactions.
Where we are furthest from human capability is the example I mentioned at the start of the week. A child is a visual genius by age two. He or she can learn from just one example ("that is a zebra") whereas we require thousands.
So a big challenge is to make these systems self-training, since large labelled datasets do not exist for most things. Video adds another level of information since there is movement. The problem of deciding whether the musician will get tipped is a lot easier from a video where you can see which way everyone is moving, or even pick the frame that makes answering the question the easiest. The level at which problems can be solved can change, too. If you have a robot in a building and you give it the goal of going to a given place, at one level you can do it with maps. But there are semantics to go along with the visual images, such as the fact that doors open into corridors and that exit signs might tell you something.
Summary
 Jitendra admits that he was old school and was a critic of NN. He thought they were over-hyped in 2010 and, in fact, would be invited to conferences to present the counter point of view on panels. The evidence still wasn't there as late as that. But now it is, "so, like Keynes, I changed my belief." In the same way that the whole scientific world has had to learn English to communicate, everything to do with vision has had to learn neural networks. In a short period of time, many tasks have gone from impossible to straightforward, and every few months more things become "solved."
Jitendra admits that he was old school and was a critic of NN. He thought they were over-hyped in 2010 and, in fact, would be invited to conferences to present the counter point of view on panels. The evidence still wasn't there as late as that. But now it is, "so, like Keynes, I changed my belief." In the same way that the whole scientific world has had to learn English to communicate, everything to do with vision has had to learn neural networks. In a short period of time, many tasks have gone from impossible to straightforward, and every few months more things become "solved."
By Paul McLellan
Editor of Breakfast Bytes, Cadence