This article was originally published at Synopsys' website. It is reprinted here with the permission of Synopsys.
Examples of applications abound where high-performance, low-power embedded vision processors are used: a mobile phone using face recognition to identify a user, an augmented or mixed reality headset identifying your hands and the layout of your living room to incorporate them into game-play, and a self-driving car ‘seeing’ the road ahead with pedestrians, oncoming cars, or the occasional animal crossing the road. Implementing deep learning in embedded applications requires a lot of processing power with the lowest possible power consumption. Processing power is needed to execute convolutional neural networks (CNNs) – the current state-of-the-art for embedded vision applications – while low power consumption will extend battery life, improving user experience and competitive differentiation. To achieve the lowest power with the best CNN graph performance in an ASIC or system-on-chip (SoC), such as for an automotive ADAS system (Figure 1), designers are turning to dedicated CNN engines.
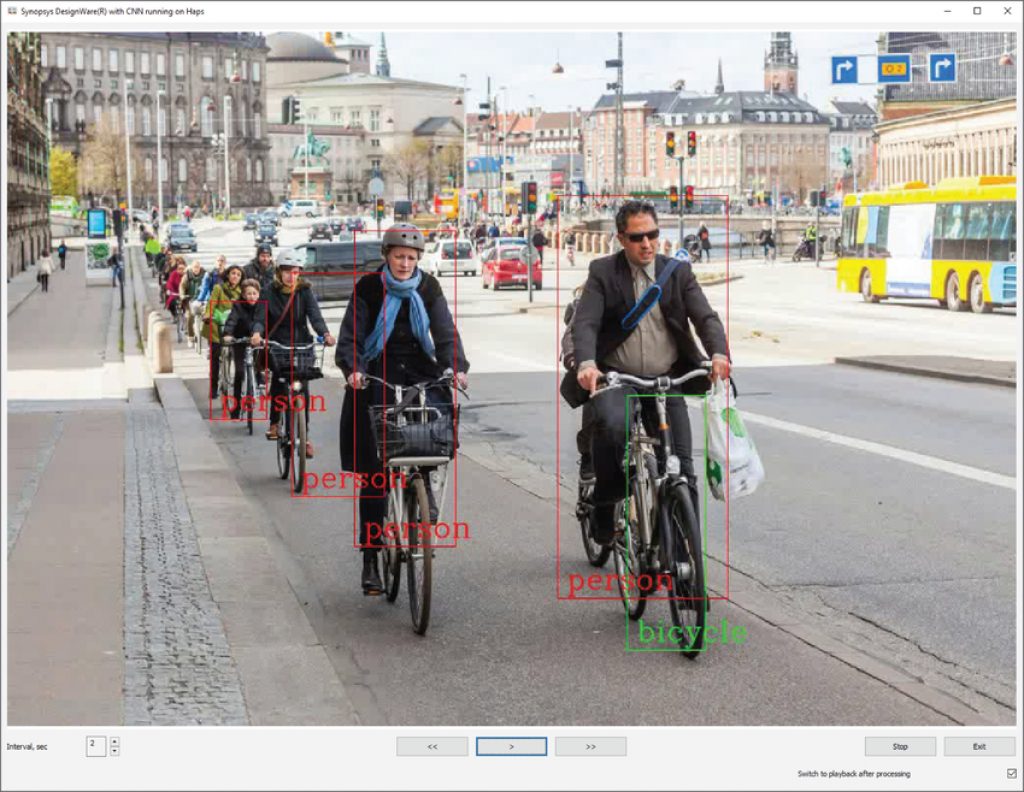
Figure 1: A TinyYOLO CNN graph running on Synopsys’ DesignWare® EV61 Embedded Vision Processor with CNN Engine provides an example of object detection and classification for automotive and surveillance applications.
Chip Options for Deep Learning Implementations
GPUs helped usher in the era of deep learning computing. The performance improvements gained by shrinking die geometries combined with the computational power of GPUs provide the horsepower needed to execute deep learning algorithms. However, the larger die sizes and higher power consumed by GPUs, which were originally built for graphics and repurposed for deep learning, limit their applicability in power-sensitive embedded applications.
Vector DSPs – very large instruction word SIMD processors – were designed as general purpose engines to execute conventionally programmed computer vision algorithms. A vector DSP’s ability to perform simultaneous multiply-accumulate (MAC) operations allows it to run the two-dimensional convolutions needed to execute a CNN graph more efficiently than a GPU. Adding more MACs to a vector DSP will allow it to process more CNNs per cycle and improve the frame rate. More power and area efficiency can be gained by adding dedicated CNN accelerators to a vector DSP.
The best efficiency, however, can be achieved by pairing a dedicated yet flexible CNN engine with a vector DSP. A dedicated CNN engine can support all common CNN operations (e.g., convolutions, pooling, elementwise) rather than just accelerating convolutions, and will offer the smallest area and power consumption because it is custom designed for these parameters. The vector DSP is still needed for pre- and post-processing of video images.
A dedicated CNN engine, optimized for memory and register reuse, is as important as increasing the number of MAC operations that the CNN engine can perform each second. If the processor doesn’t have the bandwidth and memory architecture to feed those MACs, the system will not achieve optimal performance. A dedicated CNN engine can be tuned for optimal memory and register re-use in state-of-the-art networks like ResNet, Inception, YOLO, and MobileNet.
Even lower power can be achieved with a hardwired ASIC design. This can be the desired solution when the industry agrees on a standard. For example, video compression using H.264 was implemented on programmable devices before the standard was settled on, and implemented on ASICs later. While CNN has emerged as the state-of-the-art standard for embedded vision processing, CNN implementation continues to evolve and remain a moving target, requiring designers to implement flexible and future-proof solutions.
How to Measure In-System Power Before Silicon
For the most power sensitive embedded vision applications, a vision processor with a dedicated CNN engine could be the difference between meeting the design’s power budget or missing it. Choosing a dedicated CNN engine seems intuitive, but how do you measure the power before silicon is available?
Consider an application’s performance threshold that has a tight power budget, such as a battery powered IoT smart home or mobile device running facial recognition. Facial recognition – depending on desired frame size, frame rate, and other parameters – might require a few hundred GMAC/s of embedded vision processing power. An ASIC or SoC design must now find an embedded vision solution that can execute that network within the design’s power budget – let’s say a several hundred mW.
Unfortunately, comparing different vision processor IP is not simple. Bleeding edge IP solutions often haven’t reached silicon yet, and every implementation is different, making it difficult to calculate and compare power or performance between IP options. No benchmark standards exist for comparing CNN solutions. An FPGA prototyping platform might provide accurate benchmarks but not accurate power estimates.
One way to calculate power consumption is to run a RTL or Netlist based simulation to capture the toggling of all the logic. This information, using the layout of the design, can provide a good power estimate. For smaller designs, the simulation can be completed in hours (e.g., running CoreMark or Dhrystone on an embedded RISC core.) For large designs, the simulation runs slowly. For larger CNN graphs requiring high frame rates, a simulation could take weeks to reach a steady state to measure power. There is a real risk when IP vendors skip such arduous power measurements in favor of estimating power through shortcuts using smaller simulation models, thereby pushing the problem downstream to the SoC vendors to sign-off on the IP vendor’s power analysis claim.
Synopsys’ ZeBu Server (Figure 2) provides a tremendous benefit for analyzing and measuring power for both IP developers and SoC designers. The ZeBu server is the industry’s fastest emulation system for complete SoC designs, supporting advanced use modes including power management verification, comprehensive debug and Verdi integration, hybrid emulation with virtual prototypes and architectural exploration and optimization. ZeBu has additional facilities to compute power accurately for hundreds of millions of clock cycles, e.g. Manhattan GPU frame, in hours instead of months. SoC designers can use ZeBu to tune power consumption of all elements in a system.

Figure 2: Synopsys’ ZeBu server can be used to accurately estimate power consumption of elements within an SoC, and the entire SoC design.
Once you have an accurate and efficient way to measure power of the application software, you can analyze different design configuration trade-offs to minimize power consumption. These trade-offs can be iterated and refined multiple times a day using the ZeBu power analysis flow.
First Steps to Cutting System Power
For a given process node, the easiest way to cut power is to start by lowering the frequency of the design. Other low power techniques include near-threshold logic where the logic runs at a lower voltage, greatly reducing the power required to switch the transistor. Minimizing external bus bandwidth also helps cut power. The less external bus activity, the less power is consumed. For an embedded vision application, increasing the size of internal memory will decrease bandwidth and thereby lower power, even though it will increase the overall area of the design. Designers can also minimize bandwidth – and cut power – using compression techniques on CNN graphs to reduce the computations and memory usage.
Less Power, More TMAC/s
Low power requirements aren’t limited to designs using small CNN graphs. An autonomous vehicle, for example, might require significant embedded vision performance – one or more 8MP cameras running at 60 fps could require 20 to 30 TMAC/s of computational power – all within the lowest possible power budget. Note that these TMAC/s requirements might also be listed as tera-operations per second (TOP/s). Since a MAC cycle includes two operations (one multiply and one accumulate), MAC/s are converted to Ops/s by multiplying by two.
For this application, having a dedicated CNN for the lowest power is only helpful if it can scale to higher levels of performance needed. Embedded vision processors, such as Synopsys’ EV6x family, address this challenge in two ways – by scaling the number of MACs within each CNN engine, and then by scaling multiple instances of the CNN engine on the bus fabric (e.g., tailored NoC or standard AXI.) The top of Figure 3 shows the EV61 processor with an 880 MAC CNN for smaller applications like low-power IoT smart home devices. The EV61 can integrate an 880 MAC, 1760 MAC, or 3520 MAC CNN engine to meet specific application requirements. For applications requiring even higher performance, multiple EV processors (bottom of Figure 3) can be instantiated on an AXI bus or tailored high-performance NoC fabric, providing more MACs with the most efficient performance/power profile available in embedded applications.
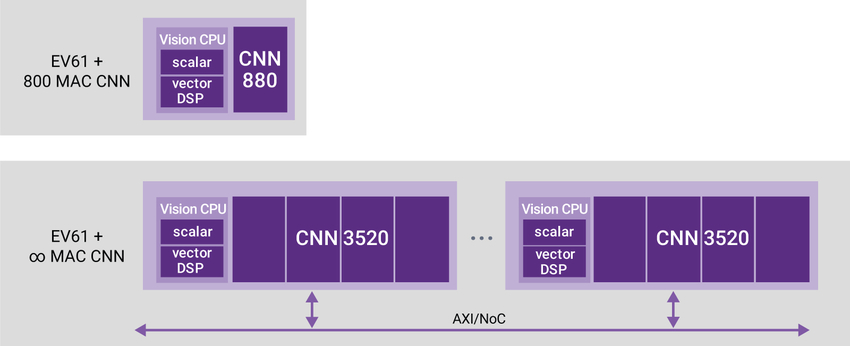
Figure 3: Synopsys’ DesignWare EV6x processors can implement one 880 CNN engine for smaller designs, up to greater CNN performance along an AXI bus. The DesignWare EV6x processors are currently deployed in low-power, high-performance applications from consumer facial recognition to large automotive applications.
Summary
To achieve the lowest power with the best convolutional neural network (CNN) graph performance in an ASIC or SoC, designers are turning to dedicated CNN engines. Implementing a design on an emulation system like the ZeBu Server is a more accurate means of determining and comparing power consumption between embedded processors than relying on back-of-the-envelope estimates from IP providers. A tightly integrated processor and CNN engine, such as in the DesignWare EV6x Embedded Vision Processor family, provides proven and measurable efficiency, performance, and power consumption.
Gordon Cooper
Product Marketing Manager, EV Processors, Synopsys