|
Dear Colleague,
On Wednesday, August 28 at 11:00 am, Embedded Vision Alliance founder (and BDTI co-founder and President) Jeff Bier will be a speaker at the Drive World with ESC Conference and Expo, taking place August 27-29 in Santa Clara, California. Bier's presentation, "Embedded Vision: The 4 Key Trends Driving the Proliferation of Visual Perception," will examine the four most important trends that are fueling the proliferation of vision applications and influencing the future of the industry:
- Deep learning
- Democratization of developer access to vision
- Fast, inexpensive, energy-efficient processors
- 3D perception
Bier will explain what's fueling each of these key trends, and highlight key implications for technology suppliers, solution developers and end-users, especially those in the automotive industry.
Drive World with ESC is bringing 2,500 electrical and mechanical engineers to Silicon Valley for an inaugural, cross-discipline event where you can find the foundational education, networking, career guidance, and supplier connections needed to keep pace with the automotive and electronics industries. Get a free expo pass and explore innovations in autonomous, hardware, software, sensors, security, connectivity and more, or opt for deeper technical training at the two conferences covering smart mobility and embedded systems. For more information and to register, please see the event page.
Brian Dipert
Editor-In-Chief, Embedded Vision Alliance
|
|
The Future of Computer Vision and Machine Learning is Tiny
There are 150 billion embedded processors in the world — more than twenty for every person on earth — and this number grows by 20% each year. Imagine a world in which these hundreds of billions of devices not only collect data, but transform that data into actionable insights — insights that in turn can improve the lives of billions of people. To do this, we need machine learning, which has radically transformed our ability to extract meaningful information from noisy data. But conventional wisdom is that machine learning consumes a vast amount of processing performance and memory — which is why today you find it mainly in the cloud and in high-end embedded systems. What if we could change that? What would it take to do that, and what would that world look like? In this keynote talk, Pete Warden, Staff Research Engineer and TensorFlow Lite development lead at Google, shares his unique perspective on the state of the art and future of low-power, low-cost machine learning. He highlights some of the most advanced examples of current machine learning technology and applications, which give some intriguing hints about what the future holds. He also explores the ability of convolutional neural networks to handle a surprisingly diverse array of tasks, ranging from image understanding to speech recognition. Looking forward, Warden shares his vision for the opportunities being opened up by this transformative technology, examines the key challenges that remain to be overcome and presents his call to action for developers to make this vision a reality.
Methods for Creating Efficient Convolutional Neural Networks
In the past few years, convolutional neural networks (CNNs) have revolutionized several application domains in AI and computer vision. The biggest challenge with state-of-the-art CNNs is the massive compute demands that prevent these models from being used in many embedded systems and other resource-constrained environments. In this presentation, Mohammad Rastegari, Chief Technology Officer at Xnor.ai, explains and contrasts several recent techniques that enable CNN models with high accuracy to consume very little memory and processing resources. These methods include a variety of algorithmic and optimization approaches to deep learning models. Quantization, "sparsification" and compact model design are three of the major techniques for efficient CNNs, which are discussed in the context of computer vision applications including detection, recognition and segmentation.
|
|
Processor Options for Edge Inference: Options and Trade-offs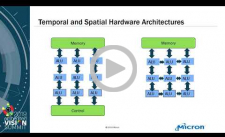
Thanks to rapid advances in neural network algorithms, we’ve made tremendous progress in developing robust solutions for numerous computer vision tasks. Face detection, face recognition, object identification, object tracking, lane marking detection and pedestrian detection are just a few examples of challenging visual perception tasks where deep neural networks are providing superior solutions to traditional computer vision algorithms. Compared with traditional algorithms, deep neural networks rely on a very different computational model. As a result, the types of processor architectures being used for deep neural networks are also quite different from those used in the past. In this talk, Raj Talluri, Senior Vice President and General Manager of the Mobile Business Unit at Micron Technology, explores the diverse processor architecture approaches that are gaining popularity in machine learning- based embedded vision applications and discusses their strengths and weaknesses in general, and in the context of specific applications.
NovuTensor: Hardware Acceleration of Deep Convolutional Neural Networks for AI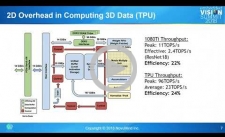
Deep convolutional neural networks (DCNNs) are driving explosive growth of the artificial intelligence industry. Effective performance, energy efficiency and accuracy are all significant challenges in DCNN inference, both in the cloud and at the edge. All these factors fundamentally depend on the hardware architecture of the inference engine. To achieve optimal results, a new class of special-purpose AI processor is needed – one that works at optimal efficiency on both computer arithmetic and data movement. NovuMind achieves this efficiency by exploiting the three-dimensional data relationship inherent in DCNNs, and by combining highly efficient, specialized hardware with an architecture flexible enough to accelerate all foreseeable DCNN structures. The result, according to Miao (Mike) Li, Vice President of IC Engineering at NovuMind in this 2018 Embedded Vision Summit presentation, is the NovuTensor processor, which puts server-class GPU/TPU performance into battery-powered embedded devices.
|
