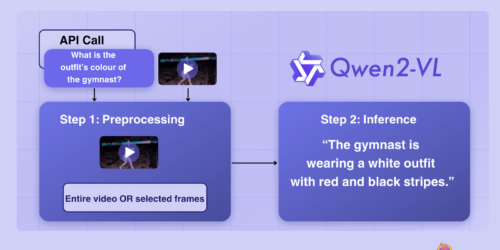
LLM Benchmarking: Fundamental Concepts
This article was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. The past few years have witnessed the rise in popularity of generative AI and large language models (LLMs), as part of a broad AI revolution. As LLM-based applications are rolled out across enterprises, there is a need to […]
LLM Benchmarking: Fundamental Concepts Read More +