Rockets to Retail: Intel Core Ultra Delivers Edge AI for Video Management
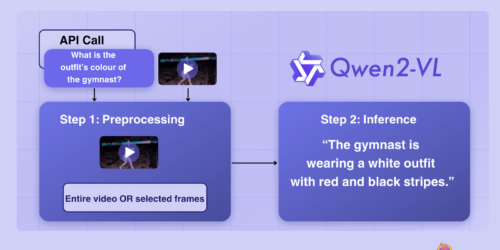
At Intel Vision, Network Optix debuts natural language prompt prototype to redefine video management, offering industries faster AI-driven insights and efficiency. On the surface, aerospace manufacturers, shopping malls, universities, police departments and automakers might not have a lot in common. But they each collectively use and manage hundreds to thousands of video cameras across their […]
Rockets to Retail: Intel Core Ultra Delivers Edge AI for Video Management Read More +