Introducing INT8 Quantization for Fast CPU Inference Using OpenVINO
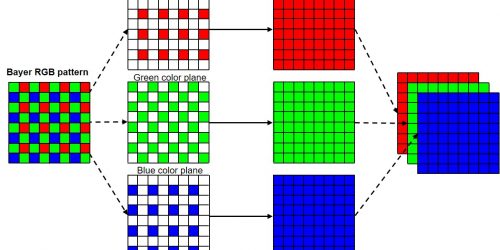
This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel. Deep learning framework optimizations and tools that streamline deployment are advancing the adoption of inference applications on Intel® platforms. Reducing model precision is an efficient way to accelerate inference on processors that support low precision math, with […]
Introducing INT8 Quantization for Fast CPU Inference Using OpenVINO Read More +