
Federated Learning: Risks and Challenges
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica. In the first article of our mini-series on Federated Learning (FL), Privacy-First AI: Exploring Federated Learning, we introduced the basic concepts behind the decentralized training approach, and we also presented potential applications in certain domains. Undoubtedly, FL

Edge Intelligence and Interoperability are the Key Components Driving the Next Chapter of the Smart Home
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm. The smart home industry is on the brink of a significant leap forward, fueled by generative AI and edge capabilities The smart home is evolving to include advanced capabilities, such as digital assistants that interact like friends

Accelerate Custom Video Foundation Model Pipelines with New NVIDIA NeMo Framework Capabilities
This blog post was originally published at NVIDIA’s website. It is reprinted here with the permission of NVIDIA. Generative AI has evolved from text-based models to multimodal models, with a recent expansion into video, opening up new potential uses across various industries. Video models can create new experiences for users or simulate scenarios for training

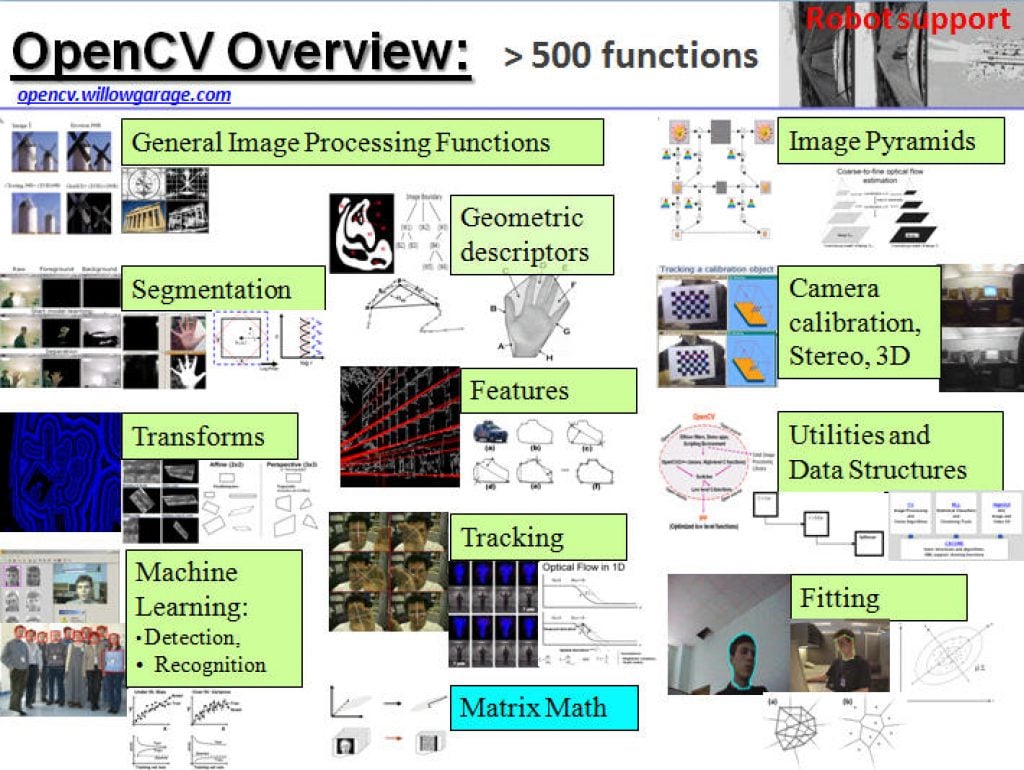
NVIDIA TAO Toolkit: How to Build a Data-centric Pipeline to Improve Model Performance (Part 3 of 3)
This blog post was originally published at Tenyks’ website. It is reprinted here with the permission of Tenyks. During this series, we will use Tenyks to build a data-centric pipeline to debug and fix a model trained with the NVIDIA TAO Toolkit. Part 1. We demystify the NVIDIA ecosystem and define a data-centric pipeline based

Computer Vision and AI at the Edge with a Thermal Camera Provider and a Toy Manufacturer
This blog post was originally published at Digica’s website. It is reprinted here with the permission of Digica. As the pace of artificial intelligence innovation accelerates, we’re seeing AI and computer vision go from science fiction tropes to enabling highly efficient and compelling applications. This integration is particularly potent at the edge, where devices locally

HPC Hardware Market to Grow at 13.6% CAGR to 2035
HPC systems, including supercomputers, outclass all other classes of computing in terms of calculation speed by parallelizing processing over many processors. HPC has long been an integral tool across critical industries, from facilitating engineering modeling to predicting the weather. The AI boom has intensified development in the sector, growing the capabilities of hardware technologies, including

How AI On the Edge Fuels the 7 Biggest Consumer Tech Trends of 2025
This blog post was originally published at Qualcomm’s website. It is reprinted here with the permission of Qualcomm. From more on-device AI features on your phone to the future of cars, 2025 is shaping up to be a big year Over the last two years, generative AI (GenAI) has shaken up, well, everything. Heading into

Israeli Start-up Visionary.ai Powers the Revolutionary Under-display Camera on the Lenovo Yoga Slim 9i
The long-awaited camera-under-display laptop technology is being launched at CES for the first time on Lenovo Yoga Slim 9i Jan 08, 2025 – JERUSALEM, ISRAEL – Under-display cameras—fully hidden beneath laptop screens—have been an unrealized dream until now. This revolutionary technology enables Lenovo to deliver a sleek, bezel-free design while maintaining exceptional video quality, thanks

Customize e-con Systems’ FPGA IP Cores to Meet Unique Vision Needs
This blog post was originally published at e-con Systems’ website. It is reprinted here with the permission of e-con Systems. Developing cutting-edge vision systems requires more than just advanced hardware—it demands the ability to customize and optimize image processing to meet specific application needs. That’s why e-con Systems offers a suite of high-performance Image Signal

NVIDIA DRIVE Hyperion Platform Achieves Critical Automotive Safety and Cybersecurity Milestones for AV Development
Adopted and Backed by Automotive Manufacturers and Safety Authorities, Latest Iteration to Feature DRIVE Thor on NVIDIA Blackwell Running NVIDIA DriveOS January 6, 2025 — CES — NVIDIA today announced that its autonomous vehicle (AV) platform, NVIDIA DRIVE AGX™ Hyperion, has passed industry-safety assessments by TÜV SÜD and TÜV Rheinland — two of the industry’s

NVIDIA Expands Omniverse With Generative Physical AI
New Models, Including Cosmos World Foundation Models, and Omniverse Mega Factory and Robotic Digital Twin Blueprint Lay the Foundation for Industrial AI Leading Developers Accenture, Altair, Ansys, Cadence, Microsoft and Siemens Among First to Adopt Platform Libraries January 6, 2025 — CES — NVIDIA today announced generative AI models and blueprints that expand NVIDIA Omniverse™

NVIDIA Launches Cosmos World Foundation Model Platform to Accelerate Physical AI Development
New State-of-the-Art Models, Video Tokenizers and an Accelerated Data Processing Pipeline, Optimized for NVIDIA Data Center GPUs, Are Purpose-Built for Developing Robots and Autonomous Vehicles First Wave of Open Models Available Now to Developer Community Global Physical AI Leaders 1X, Agile Robots, Agility, Figure AI, Foretellix, Uber, Waabi and XPENG Among First to Adopt January 6, 2025 —

NVIDIA Launches AI Foundation Models for RTX AI PCs
NVIDIA NIM Microservices and AI Blueprints Help Developers and Enthusiasts Build AI Agents and Creative Workflows on PC January 6, 2025 — CES — NVIDIA today announced foundation models running locally on NVIDIA RTX™ AI PCs that supercharge digital humans, content creation, productivity and development. These models — offered as NVIDIA NIM™ microservices — are accelerated by

NXP Accelerates the Transformation to Software-defined Vehicles (SDV) with Agreement to Acquire TTTech Auto
NXP strengthens its automotive business with a leading software solution provider specialized in the systems, safety and security required for SDVs TTTech Auto complements and accelerates the NXP CoreRide platform, enabling automakers to reduce complexity, maximize system performance and shorten time to market The acquisition is the next milestone in NXP’s strategy to be the

Optimizing Multimodal AI Inference
This blog post was originally published at Intel’s website. It is reprinted here with the permission of Intel. Multimodal models are becoming essential for AI, enabling the integration of diverse data types into a single model for richer insights. During the second Intel® Liftoff Days 2024 hackathon, Rahul Nair’s workshop on Inference of Multimodal Models

Qualcomm Brings Industry-leading AI Innovations and Broad Collaborations to CES 2025 Across PC, Automotive, Smart Home and Enterprises
Highlights: Spotlight on bringing edge AI across devices and computing spaces, including PC, automotive, smart home and into enterprises broadly, with global ecosystem partners at the show. In PC, continued traction for the Snapdragon X Series, the launch of the new Snapdragon X platform, and the launch of a new desktop form factor and NPU-powered